
AI Hypercomputer ist ein Supercomputing-System, mit dem Sie Arbeitslasten für künstliche Intelligenz (KI) und maschinelles Lernen (ML) mit mehreren Hosts mithilfe von GPU-Maschinen bereitstellen können. Die zugrunde liegenden Netzwerkdienste, die Sie bei der Bereitstellung verwenden, werden durch den von Ihnen ausgewählten GPU-Maschinentyp bestimmt.
Dieses Dokument soll Architekten, Netzwerktechnikern und Entwicklern helfen, die zugrunde liegenden Netzwerkdienste zu verstehen, die sich auf die GPU-Maschinen beziehen. Dabei wird vorausgesetzt, dass Sie mit Cloud-Netzwerken und Konzepten des verteilten Computing vertraut sind.
Die Netzwerkdienste für GPU-Maschinen zu verstehen ist der erste Schritt für die erfolgreiche Bereitstellung und Verwaltung Ihrer Arbeitslasten und unerlässlich, um Leistung und Goodput zu optimieren. Goodput (guter Durchsatz) misst den effektiven Fortschritt eines Systems bei einer ML-Trainingsaufgabe. Diese Metrik bietet im Vergleich zu Metriken wie der verstrichenen Gesamtzeit oder der Rohdurchsatzrate zusätzliche Einblicke.
Einige GPU-Maschinentypen haben eine ausgeprägte, mehrschichtige Hierarchie, die die Kommunikation auf jeder Ebene optimiert. Diese Hierarchie reicht von der Fabric des Rechenzentrums über KI-optimierte Cluster bis hin zu Compute Engine-Instanzen. In den folgenden Abschnitten werden diese hierarchischen Komponenten erläutert.
GPU-Netzwerkarchitektur
Mit AI Hypercomputer können Sie GPU Maschinen bereitstellen, die eine hierarchische, rail-konforme Netzwerkarchitektur verwenden. Die vorhersagbare, leistungsstarke Konnektivität dieses Designs minimiert den Kommunikationsaufwand, was den Goodput direkt verbessert, da GPUs mehr Zeit für Berechnungen aufwenden können, anstatt auf Daten zu warten.
Die rail-konforme Anordnung von GPUs besteht aus drei Hauptkomponenten:
- Unterblöcke:Dies sind Grundeinheiten, die aus einer Gruppe von Hosts bestehen, die sich auf demselben physischen Rack befinden. Ein ToR-Switch (Top-of-Rack) verbindet diese Hosts und ermöglicht eine extrem effiziente Kommunikation mit nur einem Hop zwischen zwei GPUs im Unterblock. RDMA over Converged Ethernet (RoCE) erleichtert diese direkte Kommunikation. Eine erweiterte NCCL-Bibliothek, die für die rail-konforme Topologie von Google optimiert ist, verarbeitet GPU-Kommunikationskollektive.
- Blöcke:Diese bestehen aus mehreren Unterblöcken, die mit einer nicht blockierenden Fabric verbunden sind, was eine Interconnect-Verbindung mit hoher Bandbreite ermöglicht. Jede GPU in einem Block ist in maximal zwei Netzwerk-Hops erreichbar. Das System stellt Block- und Unterblock-Metadaten zur Verfügung, um eine optimale Jobplatzierung zu ermöglichen.
- Cluster:Diese werden aus mehreren miteinander verbundenen Blöcken gebildet, die auf Tausende von GPUs skaliert werden können. So können Sie Trainingsarbeitslasten im großen Maßstab ausführen. Für die Kommunikation zwischen verschiedenen Blöcken ist nur ein weiterer Hop erforderlich. So bleiben Leistung und Vorhersagbarkeit auch in dieser Größenordnung hoch. Um eine intelligente Jobplatzierung im großen Maßstab zu ermöglichen, sind auch Metadaten auf Clusterebene für Orchestratoren verfügbar.
Technologien für die GPU-zu-GPU-Kommunikation
GPU-Maschinen verwenden eine Kombination von Technologien, um eine hohe Leistung, einen hohen Durchsatz und eine niedrige Latenz für Arbeitslasten zu bieten. Dazu gehören RDMA over Converged Ethernet (RoCE), NVIDIA-Netzwerkkarten und die rail-konforme Netzwerktopologie von Google im gesamten Rechenzentrum.
Diese Maschinentypen verwenden die NVLink-Technologie von NVIDIA, um direkte Datenpfade mit extrem hoher Geschwindigkeit zwischen den NVIDIA-Netzwerkkarten auf jeder Maschine zu erstellen. Außerdem ermöglicht RoCE eine effiziente RDMA-Kommunikation zwischen GPUs auf verschiedenen Maschinen.
GPU-Netzwerkstacks
Ein Netzwerkstack ist eine Sammlung von Softwareprotokollen, ‑treibern und ‑ebenen, die zusammenarbeiten, um die GPU-zu-GPU-Kommunikation zu implementieren. Verschiedene GPU-Maschinentypen verwenden unterschiedliche Netzwerkstacks. In der folgenden Tabelle sind die Netzwerkstacks und die zugehörigen Maschinentypen definiert:
| Netzwerkstack | Beschreibung | GPU-Maschinentyp |
|---|---|---|
| GPUDirect RDMA | GPUDirect RDMA ermöglicht einen direkten Pfad für den Daten austausch zwischen einer GPU und einem anderen Gerät. Bei A4X Max- und A4X-Instanzen, verwendet dieser Netzwerkstack RDMA over Converged Ethernet (RoCE). Mit dieser Technologie können Peer-Geräte direkt aus dem GPU-Speicher lesen und in ihn schreiben, wobei die CPU umgangen wird, um eine effizientere Verbindung für den leistungsstarken Datenaustausch zu schaffen. Weitere Informationen finden Sie unter Cluster Konfigurationsoptionen mit GPUDirect RDMA. | |
| GPUDirect-TCPXO | GPUDirect-TCPXO verbessert GPUDirect-TCPX, indem das TCP-Protokoll ausgelagert wird. Mit GPUDirect-TCPXO verdoppelt der Maschinentyp A3 Mega die Netzwerkbandbreite im Vergleich zu den Maschinentypen A3 High und A3 Edge types. Informationen zum Maximieren der Netzwerkbandbreite in GKE-Clustern , die GPUDirect-TCPXO verwenden, finden Sie unter GPU-Netzwerkbandbreite in Clustern im Standardmodus maximieren. Wählen Sie dann den Tab „GPUDirect-TCPXO“ aus. | |
| GPUDirect-TCPX | GPUDirect-TCPX erhöht die Netzwerkleistung, da Datenpaketnutzlasten direkt vom GPU-Speicher an die Netzwerkschnittstelle übertragen werden können. Informationen zum Maximieren der Netzwerkbandbreite in GKE-Clustern, die GPUDirect-TCPX verwenden, finden Sie unter GPU-Netzwerkbandbreite in Clustern im Standardmodus maximieren. Wählen Sie dann den Tab „GPUDirect-TCPX“ aus. |
Netzwerk der Daten- und Speicherebene des Hosts
Sämtlicher Traffic, der nicht direkte GPU-zu-GPU-Kommunikation ist, wird über einen separaten Netzwerkpfad geleitet. Dazu gehören der Zugriff auf Cloud Storage, die Verwaltung auf Hostebene und die Kommunikation mit anderen Google Cloud Diensten. Für die Verwaltung dieses Traffics verwenden die GPU-Maschinentypen Google Titanium-Netzwerkkarten.
Titanium-Netzwerkkarten entlasten die CPU von Netzwerkverarbeitungsaufgaben, damit diese sich auf Ihre Arbeitslasten konzentrieren kann. Diese Trennung sorgt dafür, dass Traffic für allgemeine Zwecke und dedizierter GPU-zu-GPU-Traffic unterschiedliche physische Schnittstellen verwenden, sodass sie nicht um dieselben Systemressourcen konkurrieren.
Umgebung mit mehreren VPCs
Alle Arbeitslasten werden in der Google Cloud's Virtual Private Cloud (VPC) von ausgeführt.
Beschleuniger mit hoher Leistung haben ein spezielles Hardwaredesign, das mehrere physische Netzwerkschnittstellen verwendet, um verschiedene Arten von Traffic zu verarbeiten. Für dieses spezielle Hardwaredesign ist eine Umgebung mit mehreren VPCs erforderlich, unabhängig davon, ob Sie Slurm, GKE oder Compute Engine verwenden, um Ihre Arbeitslasten auszuführen.
Die spezifische Multi-VPC-Konfiguration hängt vom GPU-Maschinentyp und seinem Netzwerkstack ab:
A4X Max, A4X, A4 und A3 Ultra mit GPUDirect RDMA:Diese Maschinen werden von zwei physischen Netzwerkkarten unterstützt: eine für allgemeinen Traffic und eine für RDMA-Traffic. Instanz-vNICs, die der physischen NIC für allgemeine Zwecke zugeordnet sind (die Schnittstelle
nic0und eine zusätzliche Netzwerkschnittstelle), werden an reguläre VPC-Netzwerke angehängt. RDMA-vNICs, die der RDMA-fähigen physischen NIC zugeordnet sind, werden an ein separates VPC-Netzwerk mit einem RDMA-Netzwerkprofil angehängt, um GPUDirect RDMA zu nutzen. Insgesamt sind für diese Maschinentypen drei VPC-Netzwerke erforderlich. Informationen zum Einrichten dieser Netzwerk infrastruktur finden Sie unter VPCs und Subnetze erstellen.A3 Mega mit GPUDirect-TCPXO:Für diese Maschinen sind acht separate VPCs für die GPU-Netzwerkkarten erforderlich, die für die Kommunikation mit hoher Bandbreite vorgesehen sind. Eine detaillierte Anleitung zum Ausführen dieser Konfiguration finden Sie unter VPCs und Subnetze erstellen.
A3 High mit GPUDirect-TCPX:Für diese Maschinen sind vier separate VPCs für die GPU-Netzwerkkarten erforderlich, die für die Kommunikation mit hoher Bandbreite vorgesehen sind. Eine detaillierte Anleitung zum Ausführen dieser Konfiguration finden Sie unter VPCs und Subnetze erstellen.
Diese Multi-VPC-Konfiguration trägt dazu bei, dass Speicheroperationen und andere Systemaufgaben nicht mit der Bandbreite für kritische GPU-zu-GPU-Kommunikation konkurrieren.
Die erforderliche Multi-VPC-Netzwerkkonfiguration, die Sie einrichten müssen, hängt vom GPU-Maschinentyp ab. Eine detaillierte Anleitung zur Netzwerkanordnung, zu Bandbreitengeschwindigkeiten und zu Netzwerkkarten für alle unterstützten GPU-Maschinentypen finden Sie unter Netzwerk und GPU-Maschinen.
Das folgende Diagramm zeigt die Netzwerkarchitektur für eine GPU-Maschine. Dabei wird die Trennung von Traffic für allgemeine Zwecke und dediziertem GPU-zu-GPU-Traffic auf verschiedene Netzwerkebenen hervorgehoben.
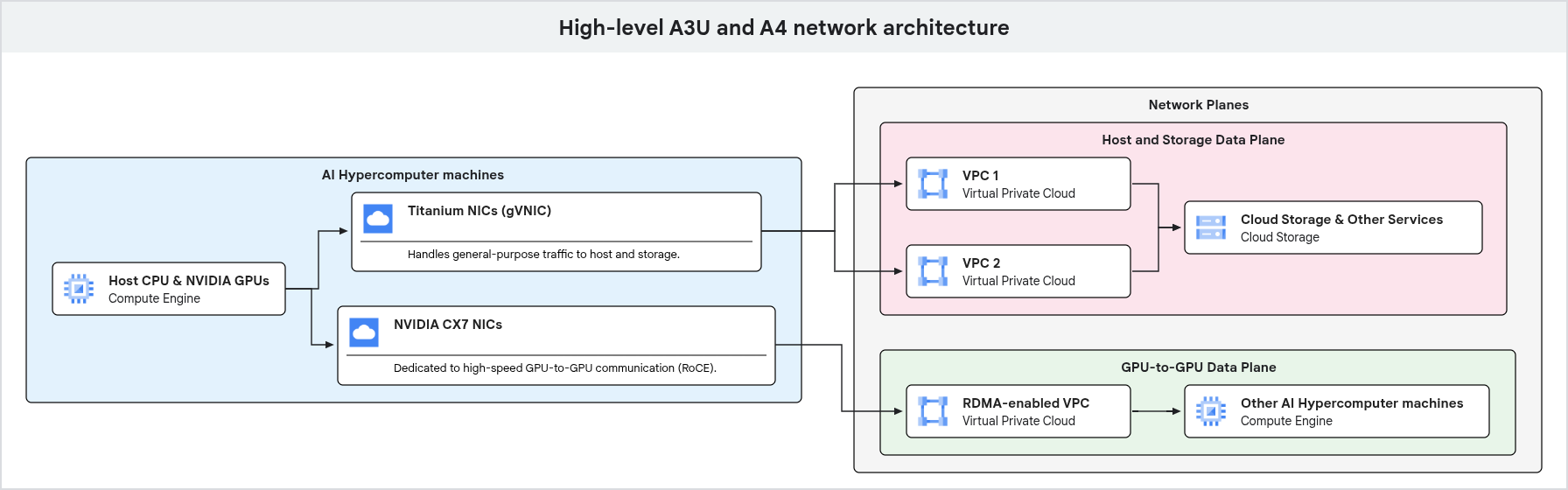
Wie im vorherigen Diagramm gezeigt, verwenden die GPU-Maschinen dedizierte Netzwerkpfade für verschiedene Arten von Traffic. Traffic für allgemeine Zwecke, einschließlich Verwaltungs- und Speicherzugriff, wird über Google Titanium-Netzwerkkarten geleitet, die mit einer VPC verbunden sind. Für die leistungsstarke GPU-zu-GPU-Kommunikation werden separate Netzwerkschnittstellen und VPCs verwendet, die mit Technologien wie RDMA optimiert sind. So werden eine hohe Bandbreite und eine niedrige Latenz für KI- und ML-Arbeitslasten gewährleistet.
Netzwerkbibliotheken und ihre Komponenten
Die folgenden Netzwerkbibliotheken und ‑komponenten ermöglichen die Verwendung von GPUs mit dem Netzwerkstack von Google, um die Netzwerkbandbreite und ‑leistung zu maximieren:
- gVNIC:Google Virtual NIC (gVNIC) ist eine virtuelle Netzwerkschnittstelle, die speziell für Compute Engine entwickelt wurde. gVNIC verbessert die Leistung, erhöht die Konsistenz und reduziert Probleme mit „noisy neighbors“. Sie wird auf allen Maschinenfamilien, Maschinentypen und Generationen unterstützt und empfohlen und ist die empfohlene vNIC für die Host-zu-Host-Kommunikation. Weitere Informationen finden Sie unter Google Virtual NIC.
- NCCL:Die NVIDIA Collective Communications Library (NCCL) bietet optimierte Primitive für gemeinsame Kommunikationsvorgänge. Sie wurde speziell für Umgebungen mit mehreren GPUs und Knoten entwickelt, die NVIDIA-GPUs und ‑Netzwerke verwenden. Führen Sie NCCL-Tests aus, um die Leistung der bereitgestellten Cluster zu bewerten. Weitere Informationen finden Sie unter Netzwerkleistung testen.
- GKE-Multi-Networking:Die Multi-Netzwerk-Unterstützung für Pods ermöglicht mehrere Schnittstellen auf Knoten und Pods in einem GKE-Cluster. Weitere Informationen zum Einrichten von Multi-Networking im Zusammenhang mit GPUDirect finden Sie unter GPU-Netzwerkbandbreite in Clustern im Standard modus maximieren und Clusterkonfigurationsoptionen mit GPUDirect RDMA.
Weitere Informationen zu den verfügbaren Softwarestacks finden Sie unter Betriebssystem- und Docker-Images.
Nächste Schritte
- Informationen zu Netzwerkdiensten für Cluster- und VM Bereitstellungen.
- Informationen zu den Best Practices für Netzwerke in AI Hypercomputer.
- Informationen zu GPU-Maschinentypen und Speicherdiensten für AI Hypercomputer.