
AI Hypercomputer 是一种超级计算系统,可帮助您使用 GPU 机器部署多主机人工智能 (AI) 和机器学习 (ML) 工作负载。部署中使用的底层网络服务取决于您选择的 GPU 机器类型。
本文档旨在帮助架构师、网络工程师和开发者了解与 GPU 机器相关的底层网络服务。本文档假定您对云网络和分布式计算概念有基本的了解。
了解 GPU 机型的网络服务是成功部署和管理工作负载的第一步,也是优化性能和有效吞吐量的关键。有效吞吐量用于衡量系统在机器学习训练任务中实现的实际有效运算进度。与总耗时或原始吞吐率等指标相比,此指标可提供更多数据洞见。
部分 GPU 机器类型具有独特的分层层次结构,可在每个层级优化通信。此层次结构涵盖了从数据中心网络到 AI 优化型集群和 Compute Engine 实例的各种资源。以下部分将介绍这些分层组件。
GPU 网络架构
AI Hypercomputer 可帮助您部署使用分层、导轨对齐网络架构的 GPU 机器。这种设计具有可预测的高性能连接,可最大限度降低通信开销,让 GPU 将更多时间用于计算而非等待数据,从而直接提升有效吞吐量。
GPU 的导轨对齐配置包含三大核心组件:
- 子区块:这些是基础单元,由一组物理上位于同一机架上的主机组成。架顶式 (ToR) 交换机连接这些主机,从而在子区块内的任意两个 GPU 之间实现极其高效的单跃点通信。基于融合以太网的 RDMA (RoCE) 可实现这种直接通信。经过增强且针对 Google 的导轨对齐拓扑进行了优化的 NCCL 库可处理 GPU 通信集合。
- 模块:由多个子模块组成,这些子模块通过非阻塞结构互连,从而实现高带宽互连。区块内的任何 GPU 最多仅需两个网络跃点即可通信。系统会公开块和子块元数据,以实现最佳作业布置。
- 集群:由多个相互连接的区块组成,可扩展至数千块 GPU,让您能够运行大规模训练工作负载。不同区块之间的通信仅增加一个额外的跃点,即使在大规模部署的情况下,也能保持高性能和可预测性。为了实现智能的大规模作业布置,编排程序还可以使用集群级元数据。
GPU 间通信技术
GPU 机器采用多种技术,可为工作负载提供高性能、高吞吐量和低延迟。这些技术包括基于融合以太网的 RDMA (RoCE)、NVIDIA NIC,以及 Google 的数据中心级导轨对齐网络拓扑。
这些机器类型使用 NVIDIA 的 NVLink 技术在每台机器的 NVIDIA 网卡之间创建超高速的数据直接传输通道。此外,借助 RoCE 技术,不同机器上的 GPU 之间能实现高效的 RDMA 通信。
GPU 网络栈
网络栈是共同实现 GPU 间通信的软件协议、驱动程序和层集合。不同的 GPU 机器类型使用不同的网络栈。下表定义了网络堆栈及其关联的机器类型:
| 网络堆栈 | 说明 | GPU 机器类型 |
|---|---|---|
| GPUDirect RDMA | GPUDirect RDMA 可在 GPU 与另一设备之间搭建直接的数据交换通道。对于 A4X Max 和 A4X 实例,此网络堆栈使用 RDMA over Converged Ethernet (RoCE)。此技术可让对等设备直接读取 GPU 的内存并向其中写入数据,从而绕过 CPU,为高性能数据交换创建更高效的连接。如需了解详情,请参阅使用 GPUDirect RDMA 的集群配置选项。 | |
| GPUDirect-TCPXO | GPUDirect-TCPXO 通过分流 TCP 协议,可改进 GPUDirect-TCPX。与 A3 High 和 A3 Edge 机器类型相比,A3 Mega 机器类型使用 GPUDirect-TCPXO 将网络带宽提高了一倍。如需了解如何在使用 GPUDirect-TCPXO 的 GKE 集群中最大限度地提高网络带宽,请参阅在 Standard 模式集群中最大限度地提高 GPU 网络带宽,然后选择“GPUDirect-TCPXO”标签页。 | |
| GPUDirect-TCPX | GPUDirect-TCPX 可让数据包载荷直接从 GPU 内存传输到网络接口,从而提高网络性能。如需了解如何在采用 GPUDirect-TCPX 的 GKE 集群中最大限度地提高网络带宽,请参阅在 Standard 模式集群中最大限度地提高 GPU 网络带宽,然后选择“GPUDirect-TCPX”标签页。 |
主机和存储数据平面网络
由独立网络路径承载所有非 GPU 直连通信的流量。此流量包括对 Cloud Storage 的访问、主机级管理操作,以及与各种 Google Cloud 服务的通信。为了管理此流量,GPU 机器类型使用 Google Titanium NIC。
Titanium NIC 可将网络处理任务从 CPU 分流,使 CPU 能够专注于处理工作负载。这种分离可确保通用流量和专用 GPU 间流量使用不同的物理接口,从而防止它们争夺相同的系统资源。
多 VPC 环境
所有工作负载都在 Google Cloud的虚拟私有云 (VPC) 中运行。
高性能加速机器采用专门的硬件设计,可使用多个物理网络接口来处理不同类型的流量。为适配专门的硬件设计,无论您是使用 Slurm、GKE 还是 Compute Engine 来运行工作负载,都必须部署在多 VPC 环境中。
具体的多 VPC 配置取决于 GPU 机器类型及其网络栈:
A4X Max、A4X、A4 和 A3 Ultra(配备 GPUDirect RDMA):这些机器由两个物理 NIC 提供支持:一个支持通用流量,另一个支持 RDMA 流量。映射到通用物理 NIC(
nic0接口和额外的网络接口)的实例 vNIC 连接到常规 VPC 网络。映射到支持 RDMA 的物理 NIC 的 RDMA vNIC 连接到具有 RDMA 网络配置文件的单独 VPC 网络,以利用 GPUDirect RDMA。总而言之,这些机器类型需要三个 VPC 网络。如需了解如何设置此网络基础架构,请参阅创建 VPC 和子网。搭载 GPUDirect-TCPXO 的 A3 Mega:这些机器需要为 GPU NIC 提供 8 个单独的 VPC,这些 VPC 专用于高带宽通信。如需详细了解如何完成此配置,请参阅创建 VPC 和子网。
使用 GPUDirect-TCPX 的 A3 High:这些机器需要为 GPU NIC 提供四个单独的 VPC,这些 VPC 专用于高带宽通信。如需详细了解如何完成此配置,请参阅创建 VPC 和子网。
这种多 VPC 配置有助于确保存储操作和其他系统任务不会与关键的 GPU 到 GPU 通信争用带宽。
您需要设置的多 VPC 网络配置因 GPU 机器类型而异。如需详细了解所有受支持的 GPU 机器类型的网络配置、带宽速度和网卡,请参阅网络和 GPU 机器。
下图展示了 GPU 机器的网络架构,重点说明了如何将通用流量和专用 GPU 到 GPU 流量分离到不同的网络平面。
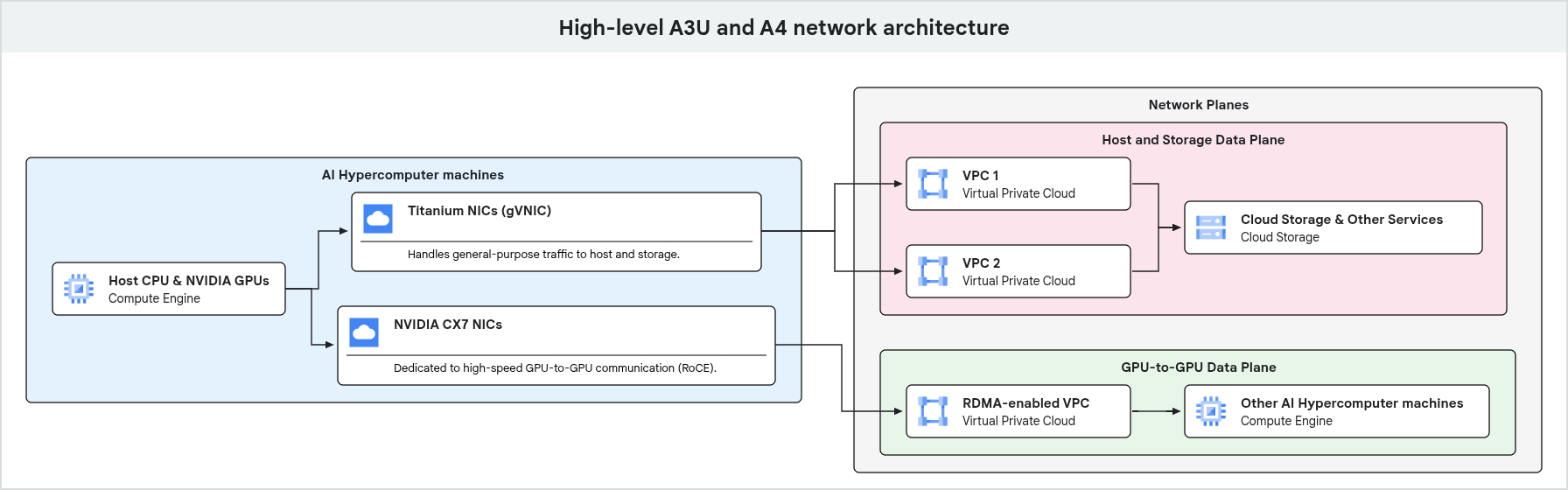
如上图所示,GPU 机器针对不同类型的流量使用专用网络路径。包括管理和存储访问在内的通用流量通过连接到 VPC 的 Google Titanium NIC 流动。高性能 GPU 间通信使用单独的网络接口和 VPC,并采用 RDMA 等技术进行优化,确保 AI 和 ML 工作负载具有高带宽和低延迟。
网络库和组件
为了最大限度地提高网络带宽和性能,以下网络库和组件可让您将 GPU 与 Google 的网络栈搭配使用:
- gVNIC:Google 虚拟 NIC (gVNIC) 是专为 Compute Engine 设计的虚拟网络接口。gVNIC 可提升性能、提高一致性并减少邻居干扰问题。所有机器系列、机器类型和世代都支持 gVNIC,建议使用。对于主机到主机的通信,建议使用 gVNIC。如需了解详情,请参阅使用 Google 虚拟 NIC。
- NCCL:NVIDIA Collective Communications Library (NCCL) 为集体通信操作提供优化的原语。它专门为多 GPU 和多节点环境而设计,使用 NVIDIA GPU 和网络。运行 NCCL 测试,以评估已部署集群的性能。 如需了解详情,请参阅测试网络性能。
- GKE 多网络:Pod 的多网络支持使您可以在 GKE 集群中的节点和 Pod 上启用多个接口。如需详细了解如何在 GPUDirect 环境中设置多网络,请参阅在 Standard 模式集群中最大限度地提高 GPU 网络带宽和使用 GPUDirect RDMA 的集群配置选项。
如需详细了解可用的软件堆栈,请参阅操作系统和 Docker 映像。
后续步骤
- 了解集群和虚拟机部署的网络服务。
- 了解 AI Hypercomputer 中的网络最佳实践。
- 了解 AI Hypercomputer 的 GPU 机器类型和存储服务。