
AI Hypercomputer 是超級運算系統,可協助您使用 GPU 機器部署多主機人工智慧 (AI) 和機器學習 (ML) 工作負載。部署作業中使用的基礎網路服務取決於您選擇的 GPU 機型。
本文旨在協助架構師、網路工程師和開發人員瞭解與 GPU 機器相關的基礎網路服務。本文假設您對雲端網路和分散式運算概念有基本認識。
瞭解 GPU 機器網路服務,是成功部署及管理工作負載的第一步,也是提升效能和有效輸送量的必要條件。有效處理量 (或有效處理量) 可衡量系統在機器學習訓練工作方面的有效進度。與總經過時間或原始輸送量等指標相比,這項指標可提供額外的洞察資訊。
部分 GPU 機型具有獨特的層疊式階層,可最佳化各層級的通訊。這個階層範圍從資料中心架構到 AI 最佳化叢集和 Compute Engine 執行個體。以下各節將說明這些階層式元件。
GPU 網路架構
AI Hypercomputer 可協助您部署 GPU 電腦,這些電腦採用階層式、符合軌道的網路架構。這種設計可預測的高效能連線可盡量降低通訊負擔,讓 GPU 將更多時間用於運算,而非等待資料,進而直接提高有效處理量。
符合軌道架構的 GPU 排列方式包含三大元件:
- 子區塊:這些是基礎單位,由實體位於同一機架上的主機群組組成。機架頂端 (ToR) 交換器會連線至這些主機,在子區塊中的任意兩個 GPU 之間,提供極高效率的單一躍點通訊。基於融合乙太網路的遠端直接記憶體存取 (RDMA) 可促成這項直接通訊。經過強化的 NCCL 程式庫已根據 Google 的符合軌道拓撲調整,可處理 GPU 通訊集合。
- 模塊:由多個子模塊組成,並透過非模塊架構互連,實現高頻寬互連。在模塊中,最多只需兩個網路躍點,就能觸及任何 GPU。系統會公開區塊和子區塊中繼資料,以實現最佳工作分配。
- 叢集:由多個互連區塊組成,可擴充至數千個 GPU,並執行大規模訓練工作負載。不同區塊之間的通訊僅會額外增加一個躍點,即使規模龐大,也能維持高效能和可預測性。為啟用智慧型大規模工作分配,自動調度管理工具也能存取叢集層級的中繼資料。
GPU 對 GPU 通訊技術
GPU 電腦會結合多種技術,為工作負載提供高效能、高處理量和低延遲。這些技術包括基於融合乙太網路的 RDMA (RoCE)、NVIDIA NIC,以及 Google 的全資料中心符合軌道的網路拓撲。
這些機器類型會使用 NVIDIA 的 NVLink 技術,在每部機器的 NVIDIA NIC 之間建立超高速直接資料路徑。此外,RoCE 可在不同機器的 GPU 之間高效率通訊。
GPU 網路堆疊
網路堆疊是一組軟體通訊協定、驅動程式和層,可共同輔助 GPU 對 GPU 通訊。不同 GPU 機型使用的網路堆疊不同。下表定義網路堆疊及其相關聯的機器類型:
| 網路堆疊 | 說明 | GPU 機型 |
|---|---|---|
| GPUDirect RDMA | GPUDirect RDMA 可在 GPU 和其他裝置之間建立資料交換的直接路徑。對於 A4X Max 和 A4X 執行個體,這個網路堆疊會使用基於融合乙太網路的 RDMA (RoCE)。這項技術可讓對等裝置直接讀取及寫入 GPU 的記憶體,略過 CPU,建立更有效率的連線,以進行高效能的資料交換。詳情請參閱「叢集設定選項 (使用 GPUDirect RDMA)」。 | |
| GPUDirect-TCPXO | GPUDirect-TCPXO 透過卸載 TCP 通訊協定,改善 GPUDirect-TCPX。使用 GPUDirect-TCPXO 時,A3 Mega 機型與 A3 High 和 A3 Edge 機型相比,網路頻寬增加一倍。如要瞭解如何在採用 GPUDirect-TCPXO 的 GKE 叢集上,盡量提高網路頻寬,請參閱「在標準模式叢集中盡量提高 GPU 網路頻寬」,然後選取「GPUDirect-TCPXO」分頁標籤。 | |
| GPUDirect-TCPX | GPUDirect-TCPX 可讓資料封包酬載直接從 GPU 記憶體傳輸至網路介面,進而提升網路效能。如要瞭解如何在採用 GPUDirect-TCPX 的 GKE 叢集上盡量提高網路頻寬,請參閱「在標準模式叢集中盡量提高 GPU 網路頻寬」,然後選取「GPUDirect-TCPX」分頁標籤。 |
主機和儲存空間資料層網路
不會導向 GPU 對 GPU 通訊的流量均由一個獨立網路路徑處理。這類流量包括存取 Cloud Storage、主機層級管理,以及與其他 Google Cloud 服務的通訊。為管理這類流量,GPU 機型使用 Google Titanium NIC。
Titanium 網路介面卡會卸載 CPU 的網路處理工作,釋出 CPU 資源,讓系統專注處理工作負載。這種分離方式可確保一般用途流量和專屬 GPU 對 GPU 流量使用不同的實體介面,避免競爭相同的系統資源。
多虛擬私有雲環境
所有工作負載都在 Google Cloud的虛擬私有雲 (VPC) 中運作。
高效能加速器機器的硬體設計經過特別調整,可使用多個實體網路介面處理不同類型的流量。無論您使用 Slurm、GKE 或 Compute Engine 執行工作負載,都必須採用多個 VPC 環境,才能處理這種專用硬體設計。
具體的多重虛擬私有雲設定取決於 GPU 機型及其網路堆疊:
A4X Max、A4X、A4 和 A3 Ultra (搭配 GPUDirect RDMA):這些機器由兩個實體 NIC 支援:一個支援一般用途流量,另一個支援 RDMA 流量。對應至一般用途實體 NIC (
nic0介面和額外網路介面) 的執行個體 vNIC 會連結至一般 VPC 網路。對應至支援 RDMA 的實體 NIC 的 RDMA vNIC,會附加至具有 RDMA 網路設定檔的獨立虛擬私有雲網路,以運用 GPUDirect RDMA。這些機型總共需要三個虛擬私有雲網路。如要瞭解如何設定這個網路基礎架構,請參閱「建立虛擬私有雲和子網路」。搭載 GPUDirect-TCPXO 的 A3 Mega:這些機器需要八個獨立的 VPC,用於 GPU NIC,專門用於高頻寬通訊。如需完成這項設定的詳細步驟,請參閱「建立虛擬私有雲和子網路」。
A3 High (搭配 GPUDirect-TCPX):這些機器需要四個獨立的虛擬私有雲,用於 GPU NIC,專門處理高頻寬通訊。如需完成這項設定的詳細步驟,請參閱「建立虛擬私有雲和子網路」。
這項多 VPC 設定可確保儲存空間作業和其他系統工作不會與重要的 GPU 對 GPU 通訊爭奪頻寬。
您需要設定的多重虛擬私有雲網路設定,會因 GPU 機型而異。如需所有支援的 GPU 機型適用的網路配置、頻寬速度和 NIC 詳細指南,請參閱「網路和 GPU 機器」。
下圖顯示 GPU 機器的網路架構,並強調一般用途流量和專屬 GPU 對 GPU 流量在不同網路平面上的分離。
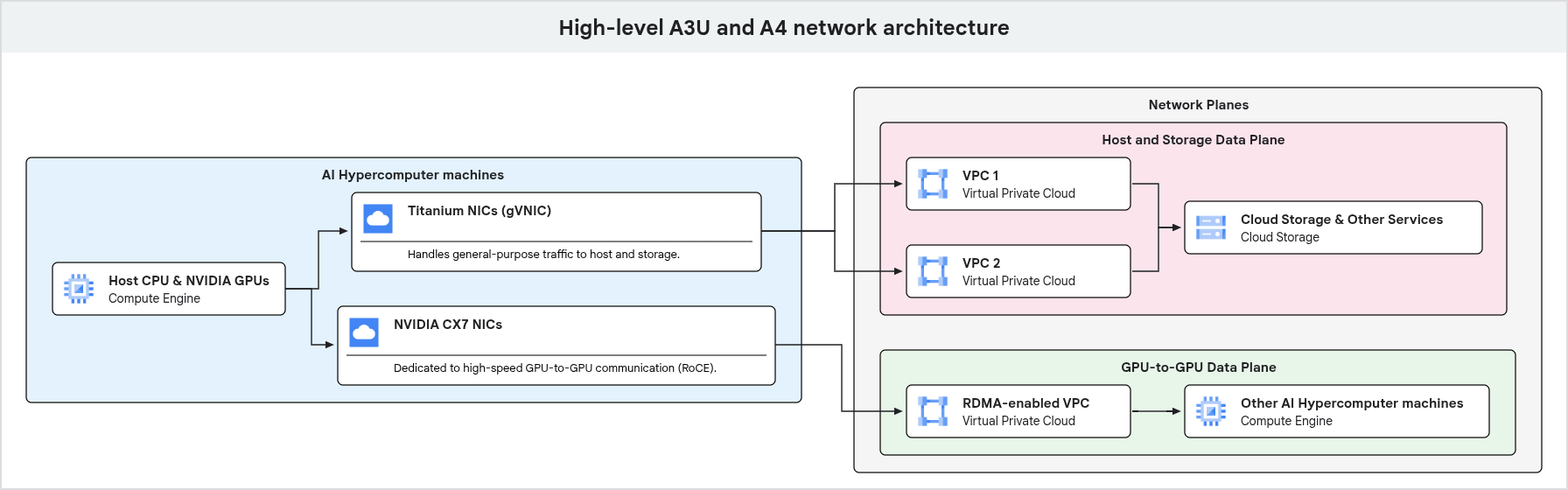
如上圖所示,GPU 機器會為不同類型的流量使用專屬網路路徑。一般用途流量 (包括管理和儲存空間存取) 會透過連線至虛擬私有雲的 Google Titanium NIC 傳輸。高效能 GPU 對 GPU 通訊使用個別網路介面和虛擬私有雲,並透過 RDMA 等技術進行最佳化,確保 AI 和 ML 工作負載的高頻寬和低延遲。
網路資料庫和元件
如要盡量提高網路頻寬和效能,下列網路程式庫和元件可讓您搭配使用 GPU 和 Google 的網路堆疊:
- gVNIC:Google Virtual NIC (gVNIC) 是專為 Compute Engine 設計的虛擬網路介面。gVNIC 可提升效能、提高一致性,並減少資源爭奪問題。所有機器系列、機器類型和世代都支援並建議使用,也是主機對主機通訊的建議 vNIC。詳情請參閱「使用 Google 虛擬 NIC」。
- NCCL:NVIDIA Collective Communications Library (NCCL) 提供最佳化基元,用於集體通訊作業。專為多 GPU 和多節點環境設計,使用 NVIDIA GPU 和網路。執行 NCCL 測試,評估已部署叢集的效能。 詳情請參閱「測試網路效能」。
- GKE 多網路:Pod 支援多網路功能之後,您就能在 GKE 叢集的節點和 Pod 中啟用多個介面。如要瞭解如何在 GPUDirect 環境中設定多重網路,請參閱「在標準模式叢集中盡量提高 GPU 網路頻寬」和「搭配 GPUDirect RDMA 的叢集設定選項」。
如要進一步瞭解可用的軟體堆疊,請參閱「作業系統和 Docker 映像檔」。
後續步驟
- 瞭解叢集和 VM 部署作業的網路服務。
- 瞭解 AI Hypercomputer 網路的最佳做法。
- 瞭解 AI Hypercomputer 的 GPU 機型和儲存空間服務。