
O Hipercomputador de IA é um sistema de supercomputação que ajuda a implantar cargas de trabalho de inteligência artificial (IA) e machine learning (ML) de vários hosts usando máquinas GPU. Os serviços de rede subjacentes usados na implantação são determinados pelo tipo de máquina GPU escolhido.
Este documento foi criado para ajudar arquitetos, engenheiros de rede e desenvolvedores a entender os serviços de rede subjacentes relacionados às máquinas GPU. Ele pressupõe que você tenha familiaridade básica com conceitos de rede de nuvem e computação distribuída.
Entender os serviços de rede de máquinas GPU é a primeira etapa para implantar e gerenciar cargas de trabalho com sucesso, além de ser essencial para otimizar o desempenho e o goodput. O goodput, ou boa capacidade de processamento, mede o progresso efetivo de um sistema em uma tarefa de treinamento de ML. Essa métrica oferece insights adicionais quando comparada a outras, como o tempo total decorrido ou a taxa de capacidade de processamento bruta.
Alguns tipos de máquinas GPU apresentam uma hierarquia distinta em camadas que otimiza a comunicação em todos os níveis. Essa hierarquia varia da malha do data center aos clusters otimizados para IA e instâncias do Compute Engine. As seções a seguir explicam esses componentes hierárquicos.
Arquitetura de rede para GPUs
O Hipercomputador de IA ajuda a implantar máquinas GPU que usam uma arquitetura de rede hierárquica e alinhada por rails. A conectividade previsível e de alto desempenho desse design minimiza o overhead de comunicação, o que melhora diretamente o goodput, permitindo que as GPUs passem mais tempo no processamento em vez de esperar por dados.
O arranjo de GPUs alinhado por rails consiste em três componentes principais:
- Sub-blocos:são unidades básicas, compostas por um grupo de hosts que estão fisicamente localizados em um único rack. Um switch top-of-rack (ToR) conecta esses hosts, permitindo uma comunicação extremamente eficiente e de salto único entre duas GPUs dentro do sub-bloco. O RDMA em Ethernet convergente (RoCE) facilita essa comunicação direta. Uma biblioteca NCCL aprimorada e otimizada para a topologia alinhada por rails do Google processa coletivos de comunicação de GPU.
- Blocos:são compostos por vários sub-blocos interconectados com uma malha não bloqueante, o que permite uma interconexão de alta largura de banda. É possível alcançar qualquer GPU dentro de um bloco com no máximo dois saltos de rede. O sistema expõe metadados de blocos e sub-blocos para permitir o posicionamento ideal do job.
- Clusters:são formados por vários blocos interconectados, que podem ser escalonados para milhares de GPUs e permitem executar cargas de trabalho de treinamento em grande escala. A comunicação entre diferentes blocos adiciona apenas mais um salto, mantendo alto desempenho e previsibilidade mesmo em escala massiva. Para permitir o posicionamento inteligente de jobs em grande escala, os metadados no nível do cluster também estão disponíveis para orquestradores.
Tecnologias de comunicação entre GPUs
As máquinas GPU usam uma combinação de tecnologias para oferecer alto desempenho, alta capacidade de processamento e baixa latência para cargas de trabalho. Exemplos dessas tecnologias são o acesso direto à memória remota (RDMA) em Ethernet convergente (RoCE), as NICs NVIDIA e a topologia de rede alinhada por rails em todo o data center do Google.
Esses tipos de máquina usam a tecnologia NVLink da NVIDIA para criar caminhos de dados diretos e de altíssima velocidade entre as NICs NVIDIA em cada máquina. Além disso, o RoCE permite RDMA eficiente entre GPUs em máquinas diferentes.
Pilhas de rede GPU
Uma pilha de rede é um conjunto de protocolos de software, drivers e camadas que trabalham juntos para implementar a comunicação entre GPUs. Diferentes tipos de máquinas GPU usam pilhas de rede diferentes. A tabela a seguir define as pilhas de rede e os tipos de máquinas associados a elas:
| Pilha de rede | Descrição | Tipo de máquina GPU |
|---|---|---|
| GPUDirect RDMA | O GPUDirect RDMA permite um caminho direto para a troca de dados entre uma GPU e outro dispositivo. Para instâncias A4X Max e A4X, essa pilha de rede usa RDMA em Ethernet convergente (RoCE). Essa tecnologia permite que dispositivos semelhantes leiam e gravem diretamente na memória da GPU, ignorando a CPU para criar uma conexão mais eficiente para a troca de dados de alto desempenho. Para mais informações, consulte Cluster opções de configuração com GPUDirect RDMA. | |
| GPUDirect-TCPXO | O GPUDirect-TCPXO melhora o GPUDirect-TCPX com a descarga do protocolo TCP. Usando o GPUDirect-TCPXO, o tipo de máquina A3 Mega dobra a largura de banda da rede em comparação com os tipos de máquina A3 High e A3 Edge types. Para informações sobre como maximizar a largura de banda da rede em clusters do GKE que usam o GPUDirect-TCPXO, consulte Maximizar a largura de banda da rede GPU em clusters do modo padrão e selecione a guia GPUDirect-TCPXO. | |
| GPUDirect-TCPX | O GPUDirect-TCPX aumenta o desempenho da rede ao permitir que os payloads dos pacotes de dados sejam transferidos diretamente da memória da GPU para a interface de rede. Para informações sobre como maximizar a largura de banda da rede em clusters do GKE que usam o GPUDirect-TCPX, consulte Maximizar a largura de banda da rede GPU em clusters do modo padrão e selecione a guia GPUDirect-TCPX. |
Rede de plano de dados de host e armazenamento
um caminho de rede separado é responsável por todo o tráfego indireto entre as GPUs. Esse tráfego inclui acesso ao Cloud Storage, gerenciamento no nível do host e comunicação com outros Google Cloud serviços. Para gerenciar esse tráfego, os tipos de máquinas GPU usam Google Titanium NICs.
As NICs Titanium descarregam tarefas de processamento da rede, liberando a CPU para se concentrar nas cargas de trabalho. Essa separação garante que o tráfego de uso geral e o tráfego dedicado de GPU para GPU usem interfaces físicas diferentes, evitando que eles disputem os mesmos recursos do sistema.
Ambiente multi-VPC
Todas as cargas de trabalho operam na nuvem privada virtual (VPC). Google Cloud
As máquinas aceleradoras de alto desempenho apresentam um design de hardware especializado que usa várias interfaces de rede físicas para processar diferentes tipos de tráfego. Para lidar com esse design de hardware especializado, é necessário um ambiente multi-VPC, independentemente de você usar o Slurm, o GKE ou o Compute Engine para executar cargas de trabalho.
A configuração multi-VPC específica depende do tipo de máquina GPU e da pilha de rede:
A4X Max, A4X, A4 e A3 Ultra com GPUDirect RDMA:essas máquinas são apoiadas por duas NICs físicas: uma que oferece suporte a tráfego de uso geral e outra que oferece suporte a tráfego RDMA. As vNICs de instância que são mapeadas para a NIC física de uso geral (a interface
nic0e uma interface de rede adicional) são anexadas a redes VPC normais. As vNICs RDMA que são mapeadas para a NIC física compatível com RDMA são anexadas a uma rede VPC separada com um perfil de rede RDMA para aproveitar o GPUDirect RDMA. No total, esses tipos de máquina exigem três redes VPC. Para saber como configurar essa infraestrutura de rede, consulte Criar VPCs e sub-redes.A3 Mega com GPUDirect-TCPXO:essas máquinas exigem oito VPCs separadas para as NICs de GPU, que são dedicadas à comunicação de alta largura de banda. Para etapas detalhadas sobre como concluir essa configuração, consulte Criar VPCs e sub-redes.
A3 High com GPUDirect-TCPX:essas máquinas exigem quatro VPCs separadas para as NICs de GPU, que são dedicadas à comunicação de alta largura de banda. Para etapas detalhadas sobre como concluir essa configuração, consulte Criar VPCs e sub-redes.
Essa configuração multi-VPC ajuda a garantir que as operações de armazenamento e outras tarefas do sistema não disputem a largura de banda com comunicações críticas de GPU para GPU.
A configuração de rede multi-VPC necessária que você precisa configurar varia de acordo com o tipo de máquina GPU. Para um guia detalhado sobre arranjo de rede, velocidades de largura de banda e NICs para todos os tipos de máquinas GPU compatíveis, consulte Redes e máquinas GPU.
O diagrama a seguir mostra a arquitetura de rede de uma máquina GPU, destacando a separação do tráfego de uso geral e do tráfego dedicado de GPU para GPU em diferentes planos de rede.
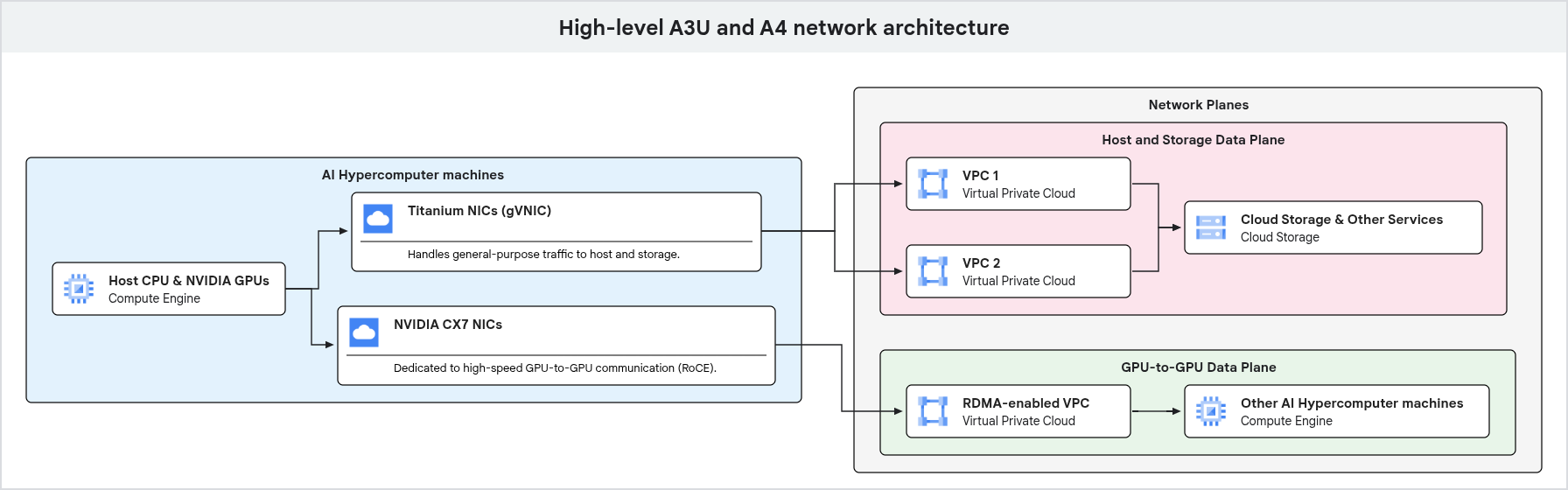
Como mostrado no diagrama anterior, as máquinas GPU usam caminhos de rede dedicados para diferentes tipos de tráfego. O tráfego de uso geral, incluindo gerenciamento e acesso ao armazenamento, flui pelas NICs Google Titanium, que estão conectadas a uma VPC. A comunicação de GPU para GPU de alto desempenho usa interfaces de rede e VPCs separadas, otimizadas com tecnologias como RDMA, garantindo alta largura de banda e baixa latência para cargas de trabalho de IA e ML.
Componentes e bibliotecas de rede
Para maximizar a largura de banda e o desempenho da rede, as bibliotecas e os componentes de rede a seguir permitem que você use GPUs com a pilha de rede do Google:
- gVNIC:a NIC virtual do Google (gVNIC) é uma interface de rede virtual projetada especificamente para o Compute Engine. A gVNIC melhora o desempenho, aumenta a consistência e reduz problemas de vizinhos barulhentos. Ela é compatível e recomendada para todas as famílias, tipos e gerações de máquinas, e é a vNIC recomendada para comunicação de host para host. Para mais informações, consulte Como usar a NIC virtual do Google.
- NCCL:a Biblioteca de Comunicação Coletiva da NVIDIA (NCCL) oferece primitivos otimizados para operações de comunicação coletiva. Ela foi projetada especificamente para ambientes com várias GPUs e vários nós, usando GPUs e redes NVIDIA. Execute testes da NCCL para avaliar o desempenho dos clusters implantados. Para mais informações, consulte Testar o desempenho da rede.
- Várias redes do GKE:o suporte a várias redes para pods permite várias interfaces em nós e pods em um cluster do GKE. Para detalhes sobre como configurar várias redes em o contexto do GPUDirect, consulte Maximizar a largura de banda da rede GPU em clusters do modo padrão e Opções de configuração de cluster com GPUDirect RDMA.
Para mais detalhes sobre as pilhas de software disponíveis, consulte Imagens de SO e do Docker.
A seguir
- Saiba mais sobre os serviços de rede para implantações de cluster e VM.
- Saiba mais sobre as práticas recomendadas para redes no Hipercomputador de IA.
- Saiba mais sobre os tipos de máquinas GPU e os serviços de armazenamento para o Hipercomputador de IA.