
AI Hypercomputer adalah sistem superkomputer yang membantu Anda men-deploy workload kecerdasan buatan (AI) dan machine learning (ML) multi-host menggunakan mesin GPU. Layanan jaringan dasar yang Anda gunakan dalam deployment ditentukan oleh jenis mesin GPU yang Anda pilih.
Dokumen ini ditujukan untuk membantu arsitek, engineer jaringan, dan developer memahami layanan jaringan dasar yang terkait dengan mesin GPU. Dokumen ini mengasumsikan bahwa Anda memiliki pemahaman dasar tentang konsep jaringan cloud dan komputasi terdistribusi.
Memahami layanan jaringan mesin GPU adalah langkah pertama untuk berhasil men-deploy dan mengelola workload Anda, serta penting untuk mengoptimalkan performa dan goodput. Goodput, atau throughput yang baik, mengukur kemajuan efektif yang dicapai oleh suatu sistem dalam tugas pelatihan ML. Metrik ini menawarkan insight tambahan jika dibandingkan dengan metrik seperti total waktu yang berlalu atau kecepatan throughput mentah.
Beberapa jenis mesin GPU memiliki hierarki berlapis yang berbeda dan mengoptimalkan komunikasi di setiap level. Hierarki ini berkisar dari fabric pusat data hingga cluster yang dioptimalkan AI dan instance Compute Engine. Bagian berikut menjelaskan komponen hierarkis ini.
Arsitektur jaringan GPU
AI Hypercomputer membantu Anda men-deploy mesin GPU yang menggunakan arsitektur jaringan hierarkis yang sesuai jalur. Konektivitas berperforma tinggi dan dapat diprediksi dari desain ini meminimalkan overhead komunikasi, yang secara langsung meningkatkan goodput dengan memungkinkan GPU menghabiskan lebih banyak waktu untuk komputasi daripada menunggu data.
Pengaturan GPU yang sesuai jalur terdiri dari tiga komponen utama:
- Sub-blok: Ini adalah unit dasar, yang terdiri dari sekelompok host yang secara fisik berada di rak yang sama. Switch pada rak teratas (ToR) menghubungkan host ini, sehingga memungkinkan komunikasi satu hop yang sangat efisien antara dua GPU mana pun di dalam sub-blok. RDMA over Converged Ethernet (RoCE) memfasilitasi komunikasi langsung ini. Library NCCL yang ditingkatkan dan dioptimalkan untuk topologi Google yang sesuai jalur menangani kolektif komunikasi GPU.
- Blok: Blok terdiri dari beberapa sub-blok yang saling terhubung dengan fabric non-blok, yang memungkinkan interkoneksi berbandwidth tinggi. Setiap GPU di dalam blok dapat dijangkau dalam maksimal dua hop jaringan. Sistem mengekspos metadata blok dan sub-blok untuk memungkinkan penempatan tugas yang optimal.
- Cluster: Cluster dibentuk oleh beberapa blok yang saling terhubung, yang dapat diskalakan hingga ribuan GPU, dan memungkinkan Anda menjalankan workload pelatihan skala besar. Komunikasi di berbagai blok hanya menambahkan satu hop tambahan, sehingga tetap mempertahankan performa tinggi dan prediktabilitas bahkan pada skala masif. Untuk mengaktifkan penempatan tugas skala besar yang cerdas, metadata tingkat cluster juga tersedia untuk orchestrator.
Teknologi untuk komunikasi GPU-ke-GPU
Mesin GPU menggunakan kombinasi teknologi untuk memberikan performa tinggi, throughput tinggi, dan latensi rendah untuk workload. Teknologi ini mencakup RDMA over Converged Ethernet (RoCE), NIC NVIDIA, dan topologi jaringan yang sesuai jalur di seluruh pusat data Google.
Jenis mesin ini menggunakan teknologi NVLink NVIDIA untuk membuat jalur data langsung berkecepatan ultra-tinggi antar-NIC NVIDIA di setiap mesin. Selain itu, RoCE memungkinkan RDMA yang efisien antar-GPU di mesin yang berbeda.
Stack jejaring GPU
Stack jejaring adalah kumpulan protokol software, driver, dan lapisan yang bekerja sama untuk menerapkan komunikasi GPU-ke-GPU. Jenis mesin GPU yang berbeda menggunakan stack jejaring yang berbeda. Tabel berikut menentukan stack jejaring dan jenis mesin terkait:
| Stack jejaring | Deskripsi | Jenis mesin GPU |
|---|---|---|
| GPUDirect RDMA | GPUDirect RDMA memungkinkan jalur langsung untuk pertukaran data antara GPU dan perangkat lain. Untuk instance A4X Max dan A4X, stack jejaring ini menggunakan RDMA over Converged Ethernet (RoCE). Teknologi ini memungkinkan perangkat peer membaca dari dan menulis langsung ke memori GPU, tanpa melalui CPU untuk membuat koneksi yang lebih efisien untuk pertukaran data berperforma tinggi. Untuk mengetahui informasi selengkapnya, lihat Opsi konfigurasi cluster dengan GPUDirect RDMA. | |
| GPUDirect-TCPXO | GPUDirect-TCPXO meningkatkan GPUDirect-TCPX dengan mengurangi beban protokol TCP. Dengan menggunakan GPUDirect-TCPXO, jenis mesin A3 Mega menggandakan bandwidth jaringan dibandingkan dengan jenis mesin A3 High dan A3 Edge types. Untuk mengetahui informasi tentang cara memaksimalkan bandwidth jaringan di cluster GKE yang menggunakan GPUDirect-TCPXO, lihat Memaksimalkan bandwidth jaringan GPU dalam cluster mode Standar dan pilih tab GPUDirect-TCPXO. | |
| GPUDirect-TCPX | GPUDirect-TCPX meningkatkan performa jaringan dengan memungkinkan payload paket data mentransfer secara langsung dari memori GPU ke antarmuka jaringan. Untuk mengetahui informasi tentang cara memaksimalkan bandwidth jaringan di cluster GKE yang menggunakan GPUDirect-TCPX, lihat Memaksimalkan bandwidth jaringan GPU dalam cluster mode Standar dan pilih tab GPUDirect-TCPX. |
Jaringan data plane host dan penyimpanan
Jalur jaringan terpisah menangani semua traffic yang bukan termasuk komunikasi langsung GPU-ke-GPU. Traffic ini mencakup akses ke Cloud Storage, pengelolaan tingkat host, dan komunikasi dengan layanan lain Google Cloud . Untuk mengelola traffic ini, jenis mesin GPU menggunakan NIC Titanium Google.
NIC Titanium mengurangi beban tugas pemrosesan jaringan dari CPU, sehingga CPU dapat fokus pada workload Anda. Pemisahan ini memastikan bahwa traffic tujuan umum dan traffic GPU-ke-GPU khusus menggunakan antarmuka fisik yang berbeda, sehingga mencegahnya bersaing untuk resource sistem yang sama.
Lingkungan multi-VPC
Semua workload beroperasi dalam Google Cloud's Virtual Private Cloud (VPC).
Mesin akselerator berperforma tinggi memiliki desain hardware khusus yang menggunakan beberapa antarmuka jaringan fisik untuk menangani berbagai jenis traffic. Untuk menangani desain hardware khusus ini, lingkungan multi-VPC diperlukan, terlepas dari apakah Anda menggunakan Slurm, GKE, atau Compute Engine untuk menjalankan workload.
Konfigurasi multi-VPC spesifik bergantung pada jenis mesin GPU dan stack jejaringnya:
A4X Max, A4X, A4, dan A3 Ultra dengan GPUDirect RDMA: Mesin ini didukung oleh dua NIC fisik: satu yang mendukung traffic tujuan umum dan satu yang mendukung traffic RDMA. vNIC instance yang dipetakan ke NIC fisik tujuan umum (antarmuka
nic0dan antarmuka jaringan tambahan) terlampir ke jaringan VPC reguler. vNIC RDMA yang dipetakan ke NIC fisik yang mendukung RDMA terlampir ke jaringan VPC terpisah dengan profil jaringan RDMA untuk memanfaatkan GPUDirect RDMA. Secara total, jenis mesin ini memerlukan tiga jaringan VPC. Untuk mempelajari cara menyiapkan infrastruktur jaringan ini, lihat Membuat VPC dan subnet.A3 Mega dengan GPUDirect-TCPXO: Mesin ini memerlukan delapan VPC terpisah untuk NIC GPU, yang dikhususkan untuk komunikasi berbandwidth tinggi. Untuk mengetahui langkah-langkah mendetail tentang cara menyelesaikan konfigurasi ini, lihat Membuat VPC dan subnet.
A3 High dengan GPUDirect-TCPX: Mesin ini memerlukan empat VPC terpisah untuk NIC GPU, yang dikhususkan untuk komunikasi berbandwidth tinggi. Untuk mengetahui langkah-langkah mendetail tentang cara menyelesaikan konfigurasi ini, lihat Membuat VPC dan subnet.
Konfigurasi multi-VPC ini membantu memastikan bahwa operasi penyimpanan dan tugas sistem lainnya tidak bersaing untuk bandwidth dengan komunikasi GPU-ke-GPU yang penting.
Konfigurasi jaringan multi-VPC yang diperlukan yang perlu Anda siapkan berbeda-beda berdasarkan jenis mesin GPU Anda. Untuk panduan mendetail tentang pengaturan jaringan, kecepatan bandwidth, dan NIC untuk semua jenis mesin GPU yang didukung, lihat Jaringan dan mesin GPU.
Diagram berikut menunjukkan arsitektur jaringan untuk mesin GPU, yang menyoroti pemisahan traffic tujuan umum dan traffic GPU-ke-GPU khusus ke bidang jaringan yang berbeda.
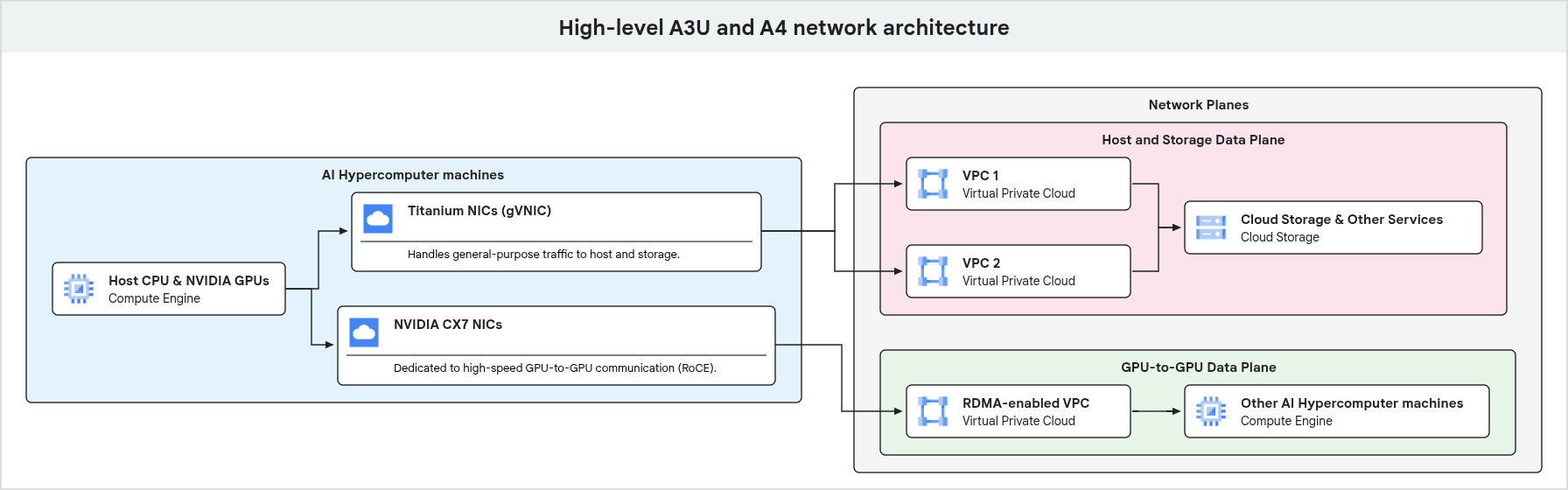
Seperti ditunjukkan dalam diagram sebelumnya, mesin GPU menggunakan jalur jaringan khusus untuk berbagai jenis traffic. Traffic tujuan umum, termasuk akses penyimpanan dan pengelolaan, mengalir melalui NIC Titanium Google yang terhubung ke VPC. Komunikasi GPU-ke-GPU berperforma tinggi menggunakan antarmuka jaringan dan VPC terpisah, yang dioptimalkan dengan teknologi seperti RDMA, sehingga memastikan bandwidth tinggi dan latensi rendah untuk workload AI dan ML.
Library dan komponen jejaring
Untuk memaksimalkan bandwidth dan performa jaringan, library dan komponen jejaring berikut memungkinkan Anda menggunakan GPU dengan stack jejaring Google:
- gVNIC: NIC Virtual Google (gVNIC) adalah antarmuka jaringan virtual yang dirancang khusus untuk Compute Engine. gVNIC meningkatkan performa, meningkatkan konsistensi, dan mengurangi masalah tetangga yang berisik. gVNIC didukung dan direkomendasikan di semua kelompok mesin, jenis mesin, dan generasi, serta merupakan vNIC yang direkomendasikan untuk komunikasi host-ke-host. Untuk mengetahui informasi selengkapnya, lihat Menggunakan NIC Virtual Google.
- NCCL: NVIDIA Collective Communications Library (NCCL) menyediakan primitif yang dioptimalkan untuk operasi komunikasi kolektif. NCCL dirancang khusus untuk lingkungan multi-GPU dan multi-node, menggunakan GPU dan jaringan NVIDIA. Jalankan pengujian NCCL untuk mengevaluasi performa cluster yang di-deploy. Untuk mengetahui informasi selengkapnya, lihat Menguji performa jaringan.
- Multi-jaringan GKE: Dukungan multi-jaringan untuk Pod memungkinkan beberapa antarmuka pada node dan Pod di cluster GKE. Untuk mengetahui detail tentang cara menyiapkan multi-jaringan dalam konteks GPUDirect, lihat Memaksimalkan bandwidth jaringan GPU dalam cluster mode Standar dan Opsi konfigurasi cluster dengan GPUDirect RDMA.
Untuk mengetahui detail selengkapnya tentang stack software yang tersedia, lihat Image OS dan Docker.
Langkah berikutnya
- Pelajari tentang layanan jaringan untuk deployment cluster dan VM deployments.
- Pelajari tentang praktik terbaik untuk jaringan di AI Hypercomputer.
- Pelajari tentang jenis mesin GPU dan layanan penyimpanan untuk AI Hypercomputer.