
最新の ML フレームワークでは多くの場合、GPU 間通信プリミティブに NVIDIA Collective Communications Library(NCCL) を使用しています。
Google の拡張版 NCCL は NCCL/gIB と呼ばれ、 Google Cloudの A3 Ultra、A4、A4X VM で使用できます。NCCL/gIB は、Google インフラストラクチャ上のアップストリーム NCCL よりもパフォーマンスが優れていることがよくあります。NCCL のパフォーマンスはワークロード全体のパフォーマンスに影響する可能性があるため、NCCL/gIB を使用することをおすすめします。
NCCL/gIB には、次のような Google 固有の機能と最適化が含まれています。
- gIB ネットワーク プラグイン は、Google のネットワークでロード バランシングを改善し、グループ オペレーション中に高スループットと低レイテンシをより一貫して実現します。
- VM で最適なチューニング オプションを選択するカスタム チューナー プラグイン。 Google Cloud
- CoMMA プロファイラ プラグイン は、ワークロードの詳細なパフォーマンス指標と診断データを提供します。
- env プラグイン は、VM 全体でプラットフォーム固有の変数構成を提供します。 Google Cloud
NCCL/gIB アーキテクチャ
NCCL/gIB は、次の図に示すように、ML フレームワークとクラスタ上の NVIDIA GPU と連携して、パフォーマンスを最適化し、テレメトリーを収集します。
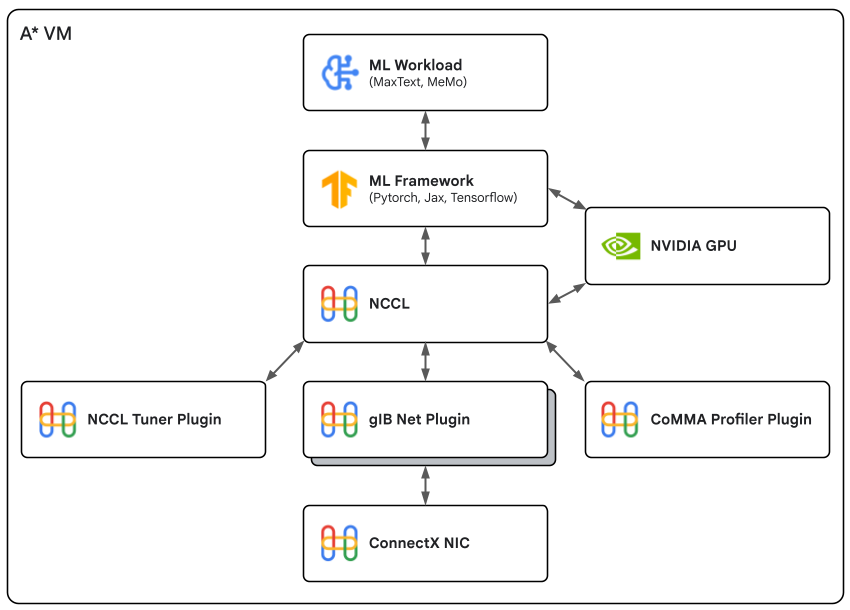
NCCL/gIB を使用するメリット
VM でアップストリームの NVIDIA Collective Communications Library を使用しても安定性の問題は発生しませんが、NCCL/gIB は Google Cloud 向けに最適化されています。 Google Cloud 同じ NCCL パラメータでも、特定の通信パターンではパフォーマンスの差が非常に大きくなる可能性があります。
たとえば、次のグラフは、AllReduce パフォーマンスにおける NCCL/gIB とアップストリーム NCCL の比較を示しています。NCCL/gIB は、特定のメッセージ サイズでアップストリーム NCCL より最大 12 倍優れたパフォーマンスを発揮します。
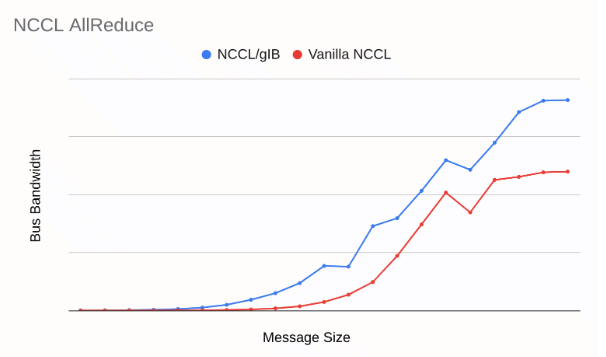
バックグラウンド トラフィックのない A3 Ultra(H200)を使用した 32 ノードの NCCL AllReduce パフォーマンス。
同様に、バックグラウンド トラフィックがある AllGather パフォーマンスにおける NCCL/gIB とアップストリーム NCCL の比較では、次のグラフに示すように、NCCL/gIB は大きなメッセージ サイズでアップストリーム NCCL より約 50% 優れたパフォーマンスを発揮します。
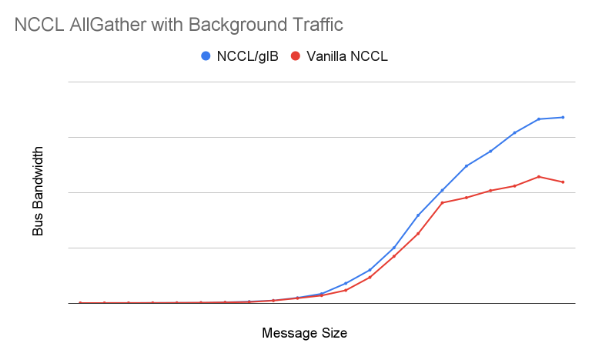
ノイズの多いバックグラウンドで共有ファブリック上の A3 Ultra(H200)を使用した 32 ノードの NCCL AllGather パフォーマンス。
さらに、CoMMA プロファイラ プラグイン により、Google はカスタム テレメトリーを改善し、ワークロード レベルの問題が発生した場合に、より適切にサポートできるようになりました。
NCCL/gIB をインストールする
NCCL テストを実行する前に、ランタイム環境に NCCL/gIB をインストールする必要があります。
NCCL/gIB を使用する
クラスタで NCCL/gIB テストを実行するには、要件に最も適した次のページを選択します。
- NVIDIA NGC コンテナで gIB NCCL プラグインを使用する
- Compute Engine VM で NCCL テストを実行する
- デフォルト構成を使用する GKE クラスタで NCCL を実行する
- A4X を使用するカスタム GKE クラスタで NCCL を実行する
- A4 または A3 Ultra を使用するカスタム GKE クラスタで NCCL を実行する
- Slurm クラスタで NCCL テストを実行する
- Cluster Director で NCCL テストを実行する
テストの実行後にクラスタで発生した問題に対処する方法については、トラブルシューティングのために NCCL/gIB ログを収集して理解するをご覧ください。