
このドキュメントでは、AI Hypercomputer でコンピューティング リソースを取得して使用するさまざまな方法(使用オプション)について説明します。ワークロード、その期間、コストのニーズに最適なオプションを選択してください。
各使用オプションでは、次のことを指定します。
VM またはクラスタを作成するための容量へのアクセス方法。
基盤となる プロビジョニング モデル。 VM の取得可能性、ライフサイクル、料金が決まります。
使用オプションの比較
次の表に、使用オプションの主な違いをまとめます。
| 使用オプション | AI Hypercomputer の将来の予約 | 最大 90 日間の将来の予約(カレンダー モード) | Flex Start | Spot |
|---|---|---|---|---|
| サポートされているマシン | A4X Max、A4X、A4、A3 Ultra、A3 Mega、A3 High | 8 個の GPU を搭載した A4、A3 Ultra、A3 Mega、A3 High | A4X Max と A4X 以外の GPU マシン | A4X Max と A4X 以外の GPU マシン |
| 存続期間 | 無制限 | 最長 90 日間 | 最長 7 日 | 無制限(ただし、プリエンプションの対象) |
| プリエンプティブル | ||||
| 容量保証 | 非常に高い 。 が予約リクエストを承認すると、 Compute Engine がリクエストされた容量をプロビジョニングする可能性が非常に高くなります。 Google Cloud | 非常に高い 。 が予約リクエストを承認すると、 Compute Engine がリクエストされた容量をプロビジョニングする可能性が非常に高くなります。 Google Cloud | ベスト エフォート 。Compute Engine は、リクエストされた容量のプロビジョニングをスケジュールするために ベスト エフォートで試行します。 | ベスト エフォート 。Compute Engine は、リクエストされた容量をプロビジョニングするためにベスト エフォートで試行します。 |
| Quota | 容量が提供される前に、割り当てが Google Cloud 自動的に増加します。 | 割り当ては消費されません。 | プリエンプティブル割り当てを消費します。 | プリエンプティブル割り当てを消費します。 |
| 料金 |
|
|
|
|
| リソースの割り当て | 高密度 | 高密度 | ベスト エフォートでの高密度( コンパクト ポリシーまたは ワークロード ポリシーは省略可) | 標準 (コンパクト ポリシー は省略可) |
| プロビジョニング モデル | 予約で制限 | 予約で制限 | Flex Start | Spot |
| 作成方法 |
VM を作成するには、次の操作を行う必要があります。 |
VM を作成するには、次の操作を行う必要があります。 |
Flex Start VM の作成をリクエストすると、Compute Engine スケジュールは可用性に基づいて VM の作成をスケジュールします。容量が使用可能になると、 Compute Engine は Flex Start VM をプロビジョニングします。Flex Start VM を作成するには、 デプロイ オプションの概要で説明されているいずれかの方法を使用します。 |
デプロイ オプションの概要で説明されているいずれかの方法を使用して、VM をすぐに作成できます。 |
使用オプションを選択する
次のフローチャートを使用して、ワークロードに最適な使用オプションを選択します。
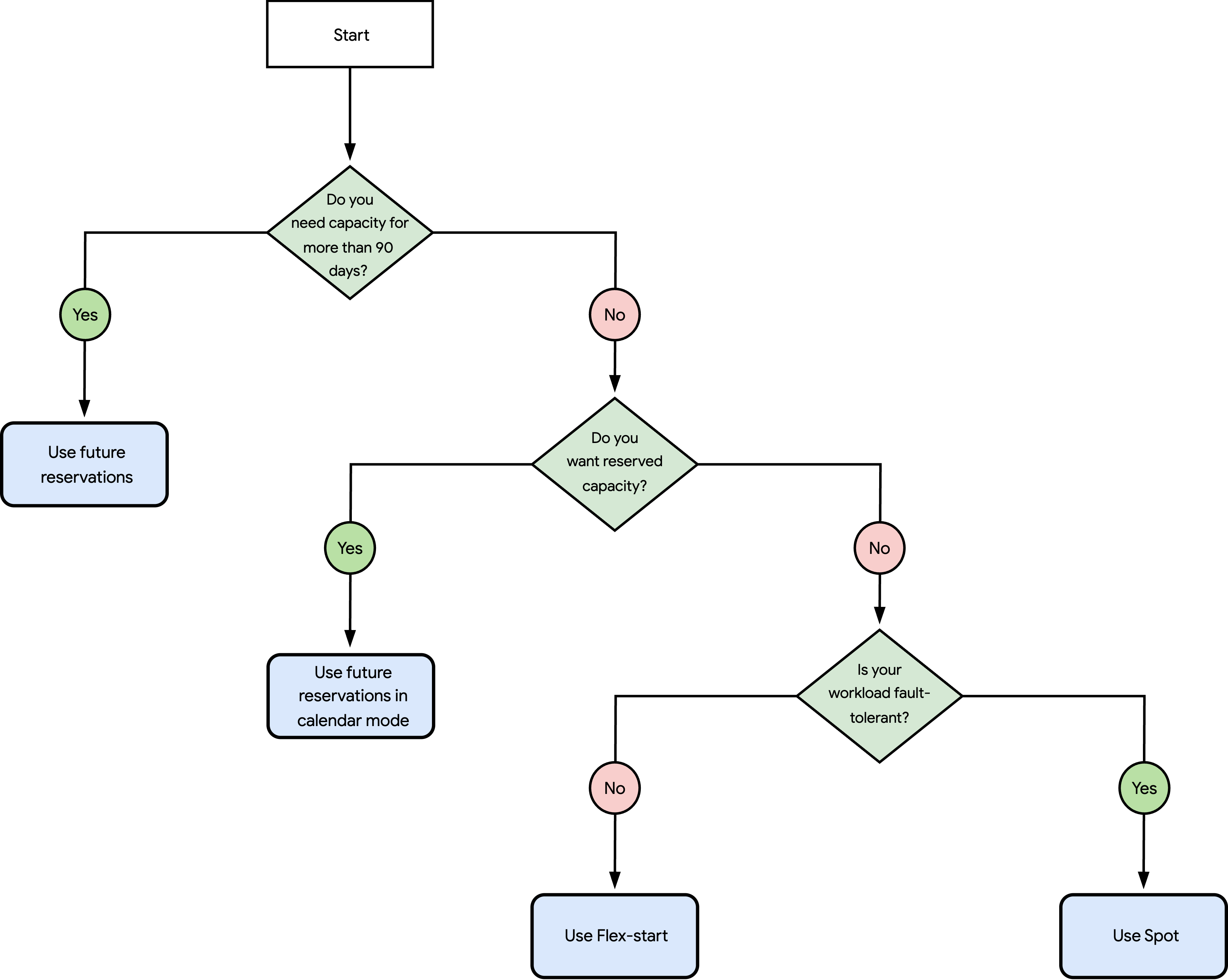
上の図の質問は次のとおりです。
90 日以上の容量が必要ですか?
はい: AI Hypercomputer で将来の予約を使用するをご覧ください。
いいえ: 質問 2 に進みます。
予約済み容量が必要ですか?
はい: カレンダー モードで将来の予約を使用するをご覧ください。
いいえ: 質問 3 に進みます。
ワークロードはフォールト トレラントですか?
いいえ: Flex Start を使用するをご覧ください。
はい: Spot を使用するをご覧ください。
AI Hypercomputer で将来の予約を使用する
リソースの密な割り当てを必要とする大規模な長時間実行分散ワークロードを実行するには、 将来の特定の期間のコンピューティングリソースをリクエストできます。その期間は予約済みリソースに排他的にアクセスでき、リソースを使用して VM または クラスタを作成できます。予約期間の終了時に、Compute Engine は次の処理を行います。
- Compute Engine は予約を削除します。
- VM に指定した 終了アクション に基づいて、Compute Engine は予約を使用する VM を停止または削除します。
AI Hypercomputer の将来の予約に適したワークロード
将来の予約は、次のワークロードに最適です。
基盤モデルの事前トレーニング
マルチホスト基盤モデルの推論
AI Hypercomputer の将来の予約の主な特性
将来の予約には次の特性があります。
-
A4X Max、A4X、A4、A3 Ultra、A3 Mega、A3 High(8 個の GPU)マシンタイプを予約できます。 ネットワーク レイテンシを最小限に抑えるために、マシンは高密度で割り当てられます。
-
将来の日付から任意の期間、任意の数の VM を予約できます。予約期間が終了するまで、 予約済みリソースを使用して VM を作成して実行します。1 年以上リソースを予約する場合は、リソースベースのコミットメントを購入して関連付ける必要があります。
-
予約期間が開始されたら、自動作成された予約を次のように変更できます。
-
予約で制限されたプロビジョニング モデルを使用します。これには次の利点があります。
GPU を取得できる可能性が高くなります。
VM に関連付けられたコミットメントに加えて、vCPU と GPU の割引率は最大 53% です。
AI Hypercomputer で将来の予約を使用する方法
将来の予約を使用して VM またはクラスタを作成するには、次の操作を行う必要があります。
-
容量の予約をリクエストする 。アカウント チームに連絡して、予約する リソースを指定します。可用性に基づいて、予約リクエストのドラフトが作成されます 。正しく入力されていることを確認したら、送信します。 Google Cloud が 予約リクエストをすぐに承認します。
手順については、 容量を予約するをご覧ください。
-
予約済みリソースを使用する 。選択した予約期間の開始時に、 予約を使用して VM またはクラスタを作成できます。
VM またはクラスタを作成するさまざまな方法については、 デプロイ オプションの概要をご覧ください。
カレンダー モードで将来の予約を使用する
リソースの密な割り当てを必要とする短時間実行の分散ワークロードを実行するには、最大 90 日間のコンピューティング リソースをリクエストできます。その期間は予約済みリソース に排他的にアクセスでき、リソースを使用して VM またはクラスタを作成できます。予約期間の終了時に、Compute Engine は次の処理を行います。
- Compute Engine は予約を削除します。
- VM に指定した 終了アクション に基づいて、Compute Engine は予約を使用する VM を停止または削除します。
カレンダー モードの将来の予約に適したワークロード
カレンダー モードの将来の予約は、次のワークロードに最適です。
モデルの事前トレーニング
モデルの微調整
シミュレーション
推論
カレンダー モードの将来の予約の主な特性
カレンダー モードの将来の予約には次の特性があります。
-
A4、A3 Ultra、A3 Mega、A3 High(8 個の GPU)マシンタイプを予約できます。ネットワーク レイテンシを最小限に抑えるために、これらのマシン は高密度で割り当てられます。
-
将来の可用性を確認し、最大 90 日間、最大 80 個の VM を予約できます。予約期間が終了するまで、予約済みリソースを使用して VM を作成できます。
-
予約期間が開始されたら、自動作成された予約を次のように変更できます。
-
予約で制限されたプロビジョニング モデルを使用します。これには次の利点があります。
GPU を取得できる可能性が高くなります。
vCPU と GPU の割引率は最大 53% です。
カレンダー モードで将来の予約を使用する方法
カレンダー モードで将来の予約を使用して VM またはクラスタを作成するには、次の操作を行う必要があります。
-
リソースの可用性を確認する 。予約するリソースの将来の可用性を確認できます。予約リクエストを作成するときに、使用可能であることを確認したリソースの 数、タイプ、予約期間を指定できます。この操作により、 がリクエストを承認する可能性が高くなります。 Google Cloud
手順については、 リソースの将来の可用性を確認するをご覧ください。
-
容量を予約する 。将来の日時の予約リクエストを作成します。 Google Cloud は 2 分以内に予約リクエストを承認します。承認されると、 Compute Engine は容量を予約します。選択したお届け日に、予約済みリソースを使用して VM またはクラスタを作成できます。
手順については、 GPU VM または TPU の予約リクエストを作成するをご覧ください。
-
予約済みリソースを使用する 。選択した予約期間の開始時に、 予約を使用して VM またはクラスタを作成できます。
VM またはクラスタを作成するさまざまな方法については、以下をご覧ください。
- A4、A3 Ultra、A3 Mega、A3 High(8 個の GPU)VM を作成するには、 デプロイ オプションの概要をご覧ください。
- GPUDirect-TCPX を有効にして A3 Mega または A3 High(8 個の GPU)VM を作成するには、 GPUDirect-TCPX を有効にして A3 VM を作成するをご覧ください。
Flex Start を使用する
リソースの密な割り当てを必要とする短期間のワークロードを実行するには、Flex Start を使用して最大 7 日間のコンピューティング リソースをリクエストできます。リソースが使用可能になると、 Compute Engine はリクエストされた数の VM を作成します。スタンドアロンの Flex Start VM は停止できますが、マネージド インスタンス グループ(MIG)がサイズ変更リクエストで作成した Flex Start VM は停止できません。Flex Start VM は、ユーザーが削除するか、Compute Engine が実行期間の終了時に VM を削除するまで存在します。
Flex Start に適したワークロード
Flex Start は、次のような、いつでも開始できるワークロードに最適です。
小規模モデルの事前トレーニング
モデルの微調整
シミュレーション
バッチ推論
Flex Start の主な特性
Flex Start には次の特性があります。
-
A4X Max と A4X を除く任意の GPU マシンタイプをリクエストできます。Compute Engine は、マシンを高密度で割り当てるために ベスト エフォートで試行します。これにより、 Flex Start VM が同じゾーン内で離れた場所に配置される可能性があります。VM の配置を制御してネットワーク レイテンシを最小限に抑えるには、次の操作を行います。
- スタンドアロンの Flex Start VM の場合は、 VM にコンパクト プレースメント ポリシーを適用します。
- ターゲット サイズの MIG の場合は、 ワークロード ポリシーを適用します。
Flex Start プロビジョニング モデルを使用します。これには次の利点があります。
GPU を取得できる可能性が高くなります。
vCPU、メモリ、GPU の割引率は最大 53% です。
Flex Start を使用する方法
Flex Start を使用して VM またはクラスタを作成するには、次の操作を行う必要があります。
-
省略可: コンパクト プレースメント ポリシーまたはワークロード ポリシーを作成する 。コンパクト プレースメント ポリシー(スタンドアロン VM または VM の一括処理用)またはワークロード ポリシー(MIG 用)を作成して、VM の近接性を指定できます。選択した構成は、ポリシーでサポートされるマシンタイプと VM の数に影響します。
-
Flex Start VM を作成する 。VM の作成をリクエストすると、 Compute Engine は可用性に基づいて VM の作成をスケジュールします。容量が使用可能になると、Compute Engine は Flex Start VM をプロビジョニングします。VM は、ユーザーが停止または削除するまで、または実行期間の終了まで実行されます。
手順については、デプロイ オプション の概要をご覧ください。
Spot を使用する
フォールト トレラントなワークロードを実行するには、 可用性に基づいてコンピューティング リソースをすぐに取得できます。リソースを可能な限り低価格で取得できます。ただし、Compute Engine は 容量を再利用するために、VM を任意のタイミングでプリエンプトする場合があります。
Spot に適したワークロード
Spot は、次のような中断が許容されるワークロードに最適です。
バッチ処理
ハイ パフォーマンス コンピューティング(HPC)
継続的インテグレーションと継続的デプロイ(CI / CD)
データ分析
メディアのエンコード
オンライン推論
Spot の主な特性
Spot には次の特性があります。
-
A4X Max と A4X を除く任意の GPU マシンタイプを作成できます。高密度の割り当ては リソースの可用性に依存します。より近い割り当てを確保するには、VM に コンパクト プレースメント ポリシー を適用します。
-
VM をすぐに作成できます。VM は、ユーザーが停止または削除するまで、または Compute Engine が容量を再利用するために VM をプリエンプトするまで実行されます。
-
Spot プロビジョニング モデルを使用します。これには次の利点があります。
GPU を取得できる可能性が高くなります。
多くのマシンタイプ、GPU、TPU、ローカル SSD ディスクで最大 91% の割引が適用されます。
Spot を使用する方法
Spot を使用して VM またはクラスタを作成するには、次の操作を行う必要があります。
-
リソースの可用性を確認する 。Spot VM を作成するリージョンまたはゾーンのリソースの可用性を確認できます。この操作により、リソースの可用性エラーが発生する可能性を減らすことができます。
手順については、 Spot VM の可用性を確認するをご覧ください。
-
省略可: プリエンプション率と料金を確認する 。さまざまなマシンタイプとゾーンの過去と 現在のプリエンプション率と料金を確認できます。この情報 は、ワークロードと予算に最適なマシンタイプとロケーションを選択するのに役立ちます。
手順については、 Spot VM のプリエンプション率と 料金を確認するをご覧ください。
-
省略可: コンパクト プレースメント ポリシーまたはワークロード ポリシーを作成する 。コンパクト プレースメント ポリシー(スタンドアロン VM または VM の一括処理用)またはワークロード ポリシー(MIG 用)を作成して、VM の近接性を指定できます。選択した構成は、ポリシーでサポートされるマシンタイプと VM の数に影響します。
手順については、 コンパクト プレースメント ポリシーを使用してレイテンシを短縮するまたは MIG のワークロード ポリシーを作成するをご覧ください。
-
Spot VM を作成する 。可用性に基づいて、必要な数の VM を作成できます。VM は、ユーザーが停止または削除するまで、または Compute Engine が容量を再利用するために VM をプリエンプトするまで実行されます。
手順については、 デプロイ オプションの概要をご覧ください。