

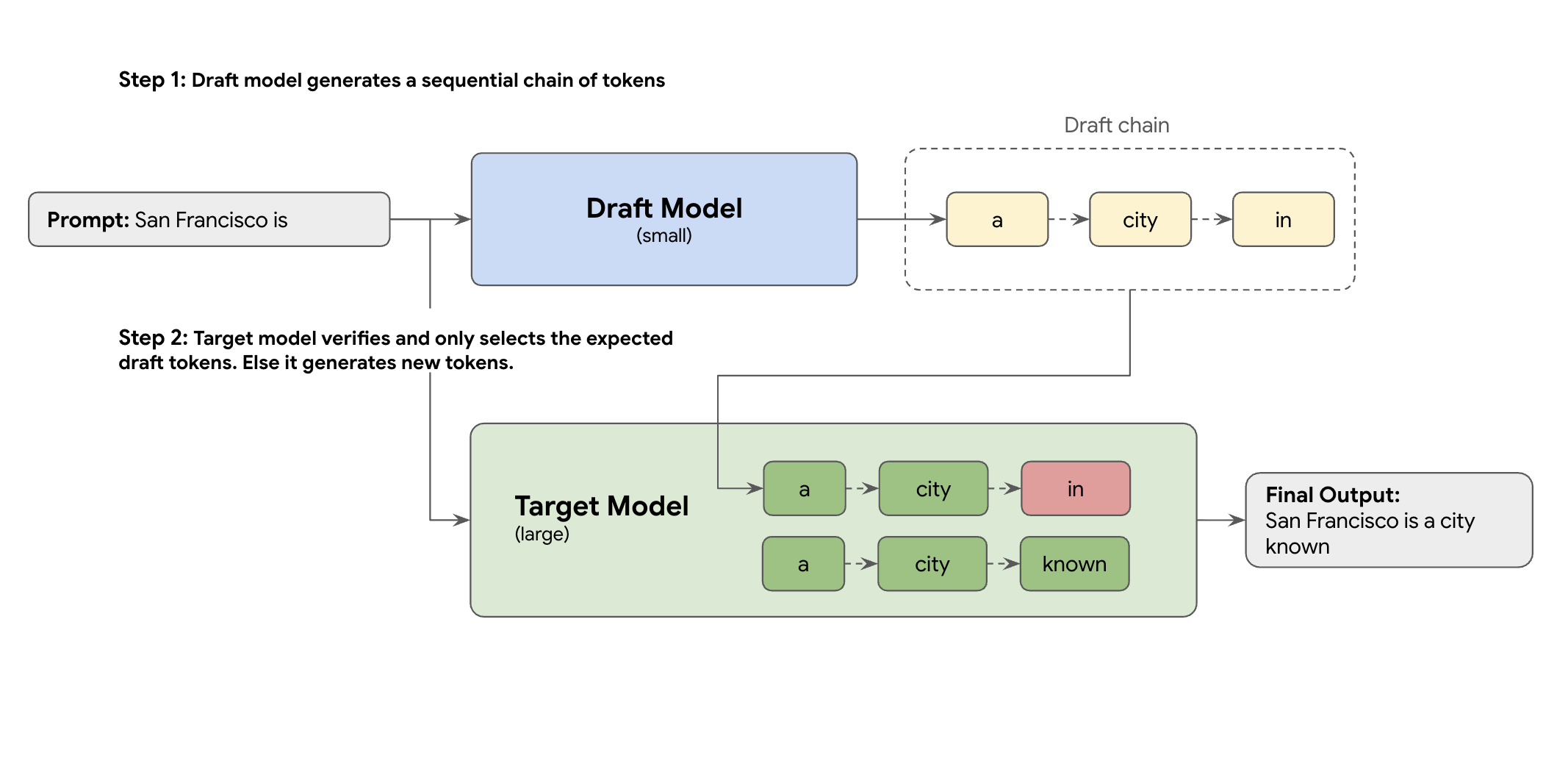
解決方法是推測解碼。這項最佳化技術會導入草稿機制,加快大型 LLM (目標模型) 緩慢的循序程序,一次生成一個權杖。
這項草稿機制會一次快速建議多個後續詞元。大型目標模型接著會以單一平行批次驗證這些提案。它會接受自身預測中最長的前置字串,並從該新點繼續生成內容。
不過,並不是所有草稿機制都相同。傳統的草稿目標方法會使用獨立的較小型 LLM 模型做為草稿撰寫者,這表示您必須代管及管理更多服務資源,因而產生額外費用。
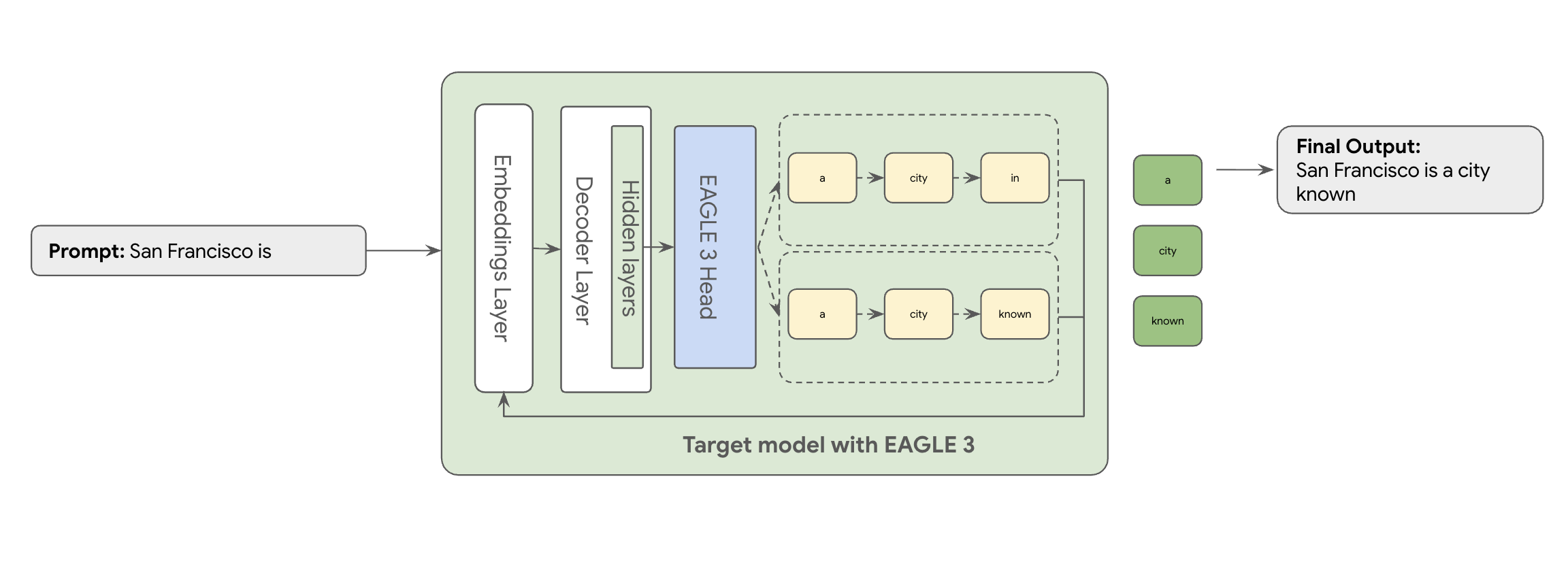
這時 EAGLE-3 (Extrapolative Attention Guided LEarning) 就能派上用場。EAGLE-3 則採用更先進的方法。 這項技術不會另外建立模型,而是直接在內部層附加極輕量的「草稿頭」,大小僅占目標模型的 2% 到 5%。這個標頭會在特徵和權杖層級運作,從目標模型的隱藏狀態擷取特徵,藉此推斷及預測未來的權杖樹狀結構。
因此,享有推測解碼的所有優點,同時消除訓練及執行第二個模型的額外負擔。
相較於訓練及維護獨立的數十億參數草稿模型,EAGLE-3 的方法更有效率,且不會耗用大量資源。您只需訓練輕量級的「草稿頭」,也就是目標模型大小的 2% 到 5%,並將其新增為現有模型的一部分。這個更簡單有效率的訓練程序,可為 Llama 70B 等模型帶來顯著的 2 到 3 倍解碼效能提升 (視工作負載類型而定,例如多輪對話、程式碼、長內容等)。
但即使是這種簡化的 EAGLE-3 方法,要從紙上談兵變成可大規模部署的雲端服務,仍是一段漫長的工程旅程。本文將分享我們的技術管道、主要挑戰,以及我們在過程中學到的寶貴經驗。
挑戰 1:準備資料
EAGLE-3 頭部需要訓練。顯而易見的第一步是取得可公開使用的通用資料集。大多數資料集都會帶來挑戰,包括:
- 嚴格的使用條款:這些資料集是使用模型生成,因此不得用於開發會與原始供應商競爭的模型。
- 個人識別資訊汙染:部分資料集含有大量個人識別資訊,包括姓名、位置,甚至是財務識別資訊。
- 無法保證品質:部分資料集只適用於一般「示範」用途,不適合實際客戶的專業工作負載。
無法直接使用這項資料。
第 1 課:建構合成資料生成管道
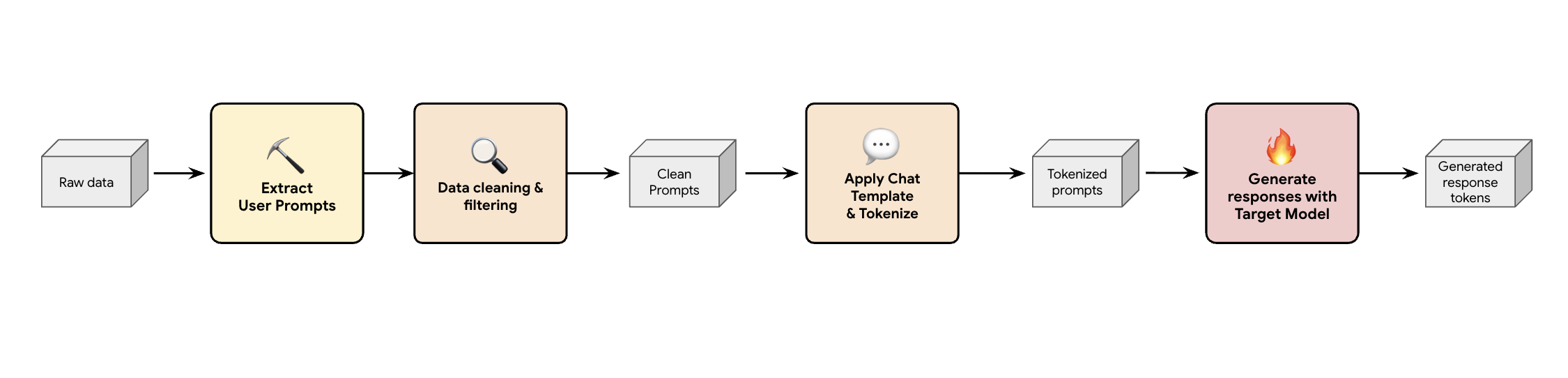
其中一個解決方案是建立合成資料生成管道。我們會根據客戶的使用案例,選擇不僅品質良好,而且最符合客戶生產流量的資料集,以因應各種不同的工作負載。然後,您就可以只從這些資料集擷取使用者提示,並套用嚴格的 DLP (資料遺失防護) 和 PII 篩選。這些乾淨的提示會套用即時通訊範本、將提示權杖化,然後提供給目標模型 (例如 Llama 3.3 70B) 收集回應。
這種做法不僅能產生符合規定且乾淨的目標資料,還能與模型的實際輸出分配情形相符。這非常適合訓練草稿標題。
挑戰 #2:設計訓練管道
另一個重要決策是,如何將訓練資料提供給 EAGLE-3 標頭。您有兩種不同的路徑:線上訓練 (即「即時產生」嵌入),以及離線訓練 (即「在訓練前產生」嵌入)。
在本例中,我們選擇離線訓練方法,因為與線上訓練相比,這種方法所需的硬體少得多。這個程序會在訓練 EAGLE-3 標題前,預先計算所有特徵和嵌入。我們會將這些資料儲存到 GCS,並做為輕量型 EAGLE-3 標頭的訓練資料。取得資料後,訓練過程本身很快。由於 EAGLE-3 磁頭體積小巧,使用原始資料集進行初始訓練時,單一主機約需一天時間。不過,隨著資料集規模擴大,訓練時間也相應增加,現在需要好幾天才能完成。

這個過程讓我們學到兩項不容忽視的教訓,請務必牢記在心。
第 2 課:聊天範本為必填項目
在訓練指令微調模型時,我們發現如果聊天範本不正確,EAGLE-3 的效能可能會大幅變動。您必須套用目標模型的特定即時通訊範本 (例如 Llama 3) 之前,請先生成特徵和嵌入。如果只是串連原始文字,內嵌表示就會不正確,且模型頭會學到預測錯誤的分布。
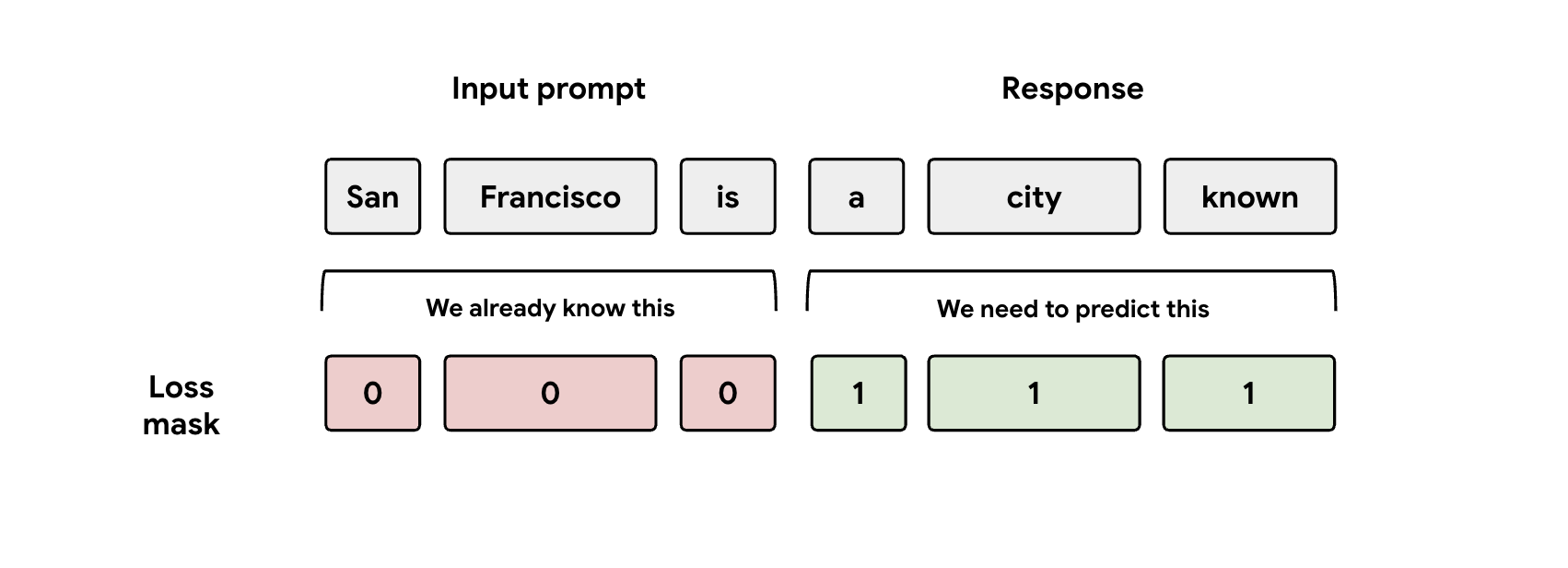
第 3 課:注意遮罩
在訓練期間,模型會同時接收提示和回覆的表示法。 但 EAGLE-3 標頭只應學習預測回應表示法。您必須在損失函式中手動遮蓋提示部分。如果沒有,模型就會浪費容量來預測已收到的提示,導致成效不佳。
挑戰 #3:服務和資源調度
訓練 EAGLE-3 標頭後,我們接著進入服務階段。這個階段帶來了重大的擴充難題。以下是我們的主要發現。
第 4 課:服務架構是關鍵
我們與 SGLang 團隊密切合作,成功將 EAGLE-3 投入生產,並達到最佳效能。技術原因在於 SGLang 實作了重要的樹狀結構注意力核心。這個特殊核心至關重要,因為 EAGLE-3 會生成可能的「草稿樹狀結構」(不只是簡單的鏈結),而 SGLang 的核心專門用於在單一步驟中,平行驗證所有分支路徑。否則就如同白白放棄可能的成效。
第 5 課:避免 CPU 成為 GPU 的效能瓶頸
即使使用 EAGLE-3 加速 LLM,您仍可能遇到另一個效能瓶頸:CPU。GPU 執行 LLM 推論時,未經最佳化的軟體會浪費大量時間處理 CPU 負擔,例如核心啟動和中繼資料記錄。在一般的同步排程器中,GPU 會執行一個步驟 (例如「草稿」),然後在 CPU 執行記帳作業並啟動下一個「驗證」步驟時閒置。這些同步泡泡會累積,浪費大量寶貴的 GPU 時間。

我們使用 SGLang 的「零負擔重疊排程器」解決了這個問題。這個排程器專為推測解碼的多步驟「草稿 -> 驗證 -> 草稿擴充」工作流程進行調整。關鍵在於重疊運算。GPU 忙於執行目前的「驗證」步驟時,CPU 已經開始平行運作,為下一個「草稿」和「草稿擴充」步驟啟動核心。這項技術可確保 GPU 的下一個工作隨時準備就緒,藉此消除閒置泡泡,並使用 FutureMap (一種智慧型資料結構),讓 CPU 在 GPU 仍在運作時準備下一個批次。

消除這項 CPU 負擔後,重疊排程器可全面提升 10% 至 20% 的速度。這證明瞭出色的模型只是成功的一半,您還需要能跟上腳步的執行階段。
基準測試結果
經過這段歷程,你覺得值得嗎?當然可以!
我們使用 SGLang 和 Llama 4 Scout 17B Instruct,針對非推測性基準測試訓練的 EAGLE-3 標頭。我們的基準測試顯示,視工作負載類型而定,解碼延遲時間可縮短 2 到 3 倍,且輸送量顯著提升。
如要查看完整詳細資料並自行進行基準測試,請使用我們的完整筆記本。
指標 1:每個輸出權杖的時間中位數 (TPOT)
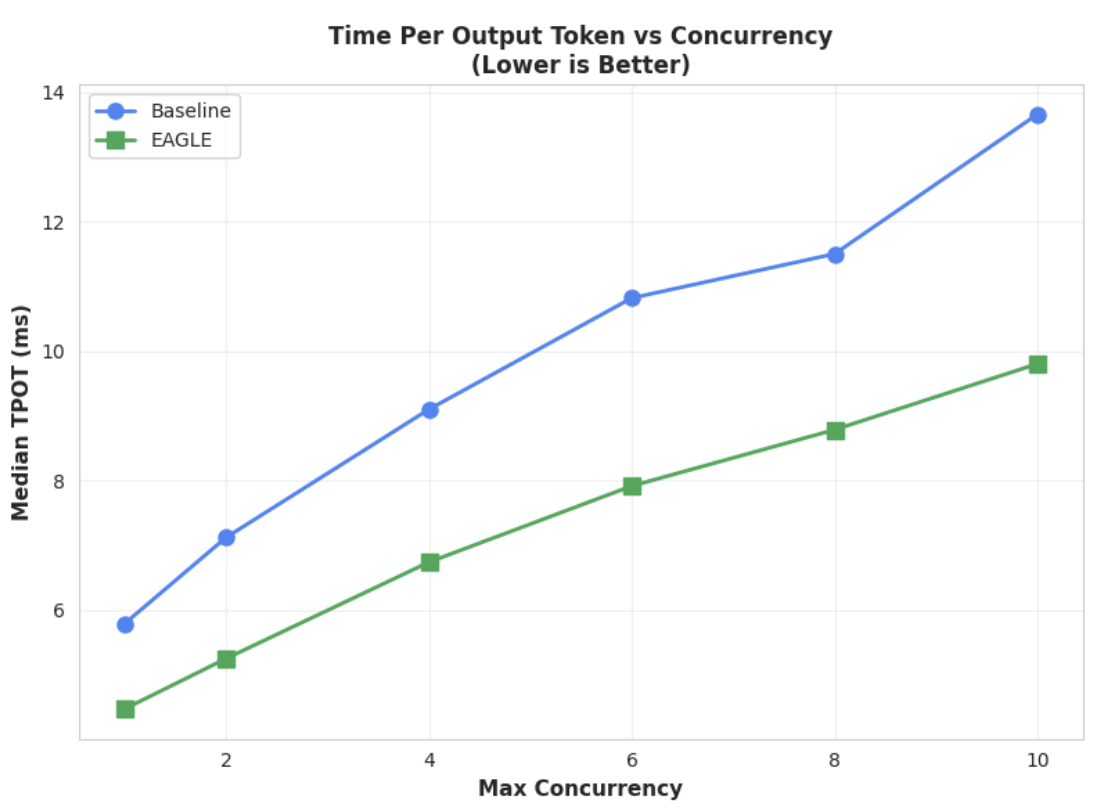
這張圖表顯示 EAGLE-3 的延遲效能較佳。每個輸出權杖的時間 (TPOT) 圖表顯示,在所有測試的並行層級中,EAGLE-3 加速模型 (綠線) 的延遲時間一律比基準 (藍線) 短 (速度較快)。
指標 2:輸出處理量
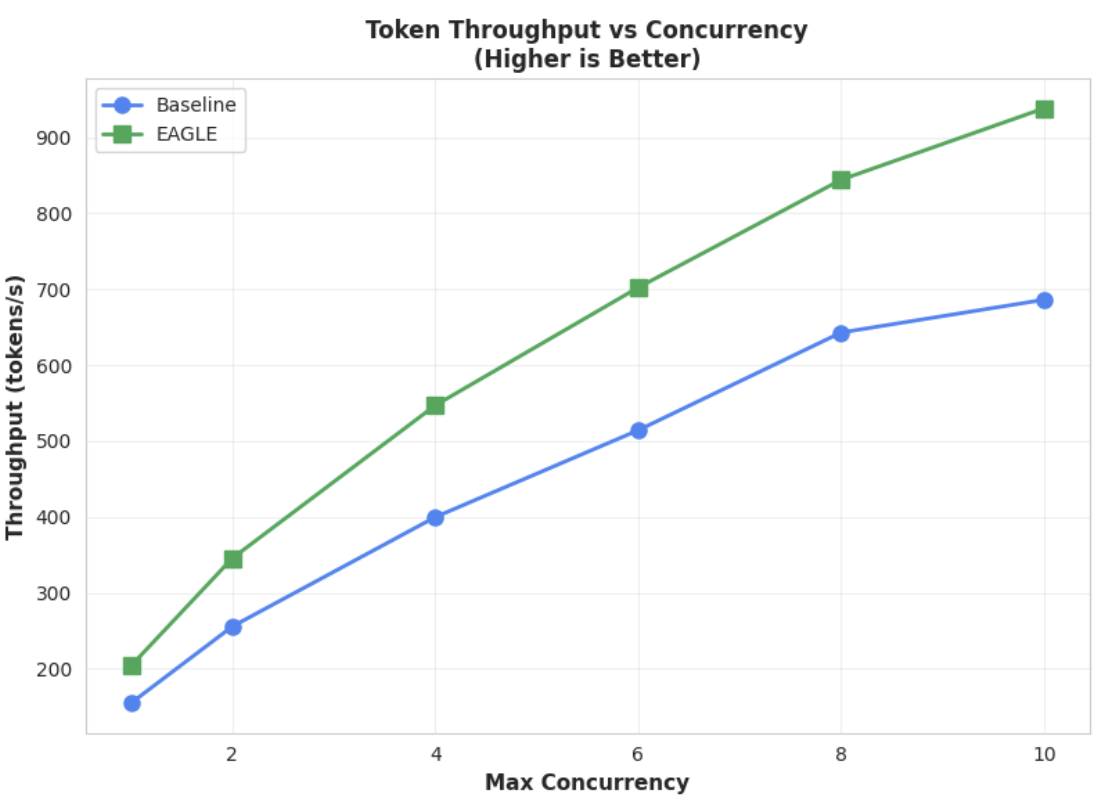
這張圖表進一步凸顯 EAGLE-3 的處理量優勢。並行數與權杖輸送量圖表清楚顯示,EAGLE-3 加速模型 (綠線) 持續大幅優於基準模型 (藍線)。
雖然大型模型也有類似的觀察結果,但值得注意的是,與其他效能指標相比,首次權杖時間 (TTFT) 可能會增加。此外,這些效能會因工作而異,如下列範例所示:
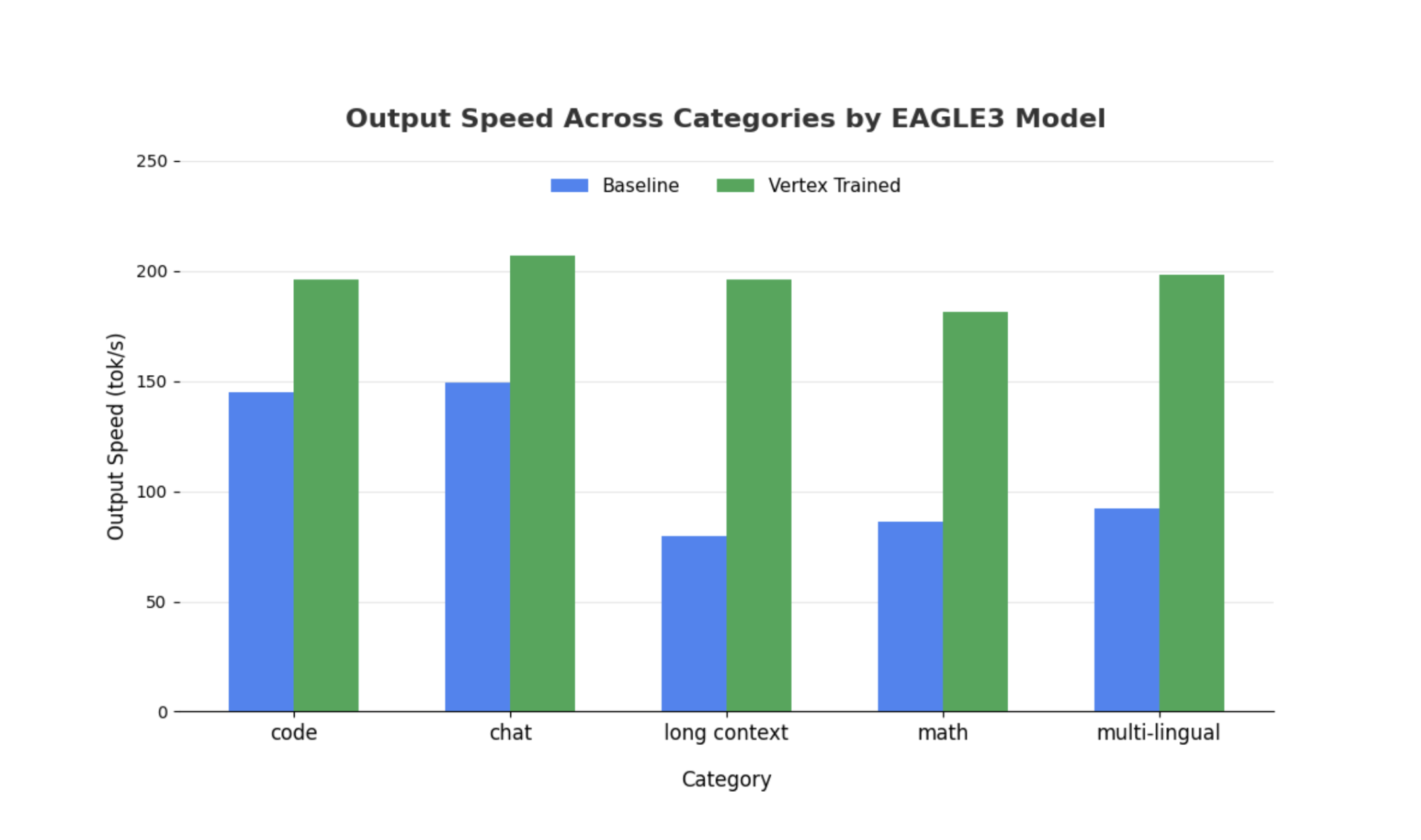
結語:現在輪到你了
EAGLE-3 不只是研究概念,更是可直接用於正式環境的模式,能實際將解碼延遲時間縮短 2 倍。但要大規模採用,需要投入大量工程資源。如要為使用者穩定部署這項技術,請務必:
- 建構符合規定的合成資料管道。
- 正確處理對話範本和損失遮罩,並在大型資料集上訓練模型。
在 Vertex AI 上,我們已為您簡化整個程序,提供最佳化容器和基礎架構,可擴充以 LLM 為基礎的應用程式。如要開始使用,請參閱下列資源:
感謝閱讀
歡迎提供有關 Vertex AI 的意見回饋或提出問題。
特別銘謝
我們衷心感謝 SGLang 團隊 (尤其是 Ying Sheng、Lianmin Zheng、Yineng Zhang、Xinyuan Tong、Liangsheng Yin) 和 SGLang/SpecForge 團隊 (尤其是 Shenggui Li、Yikai Zhu) 在這個專案中提供的寶貴支援。他們慷慨提供協助,並分享深入的技術洞察資料,對這項專案的成功至關重要。