

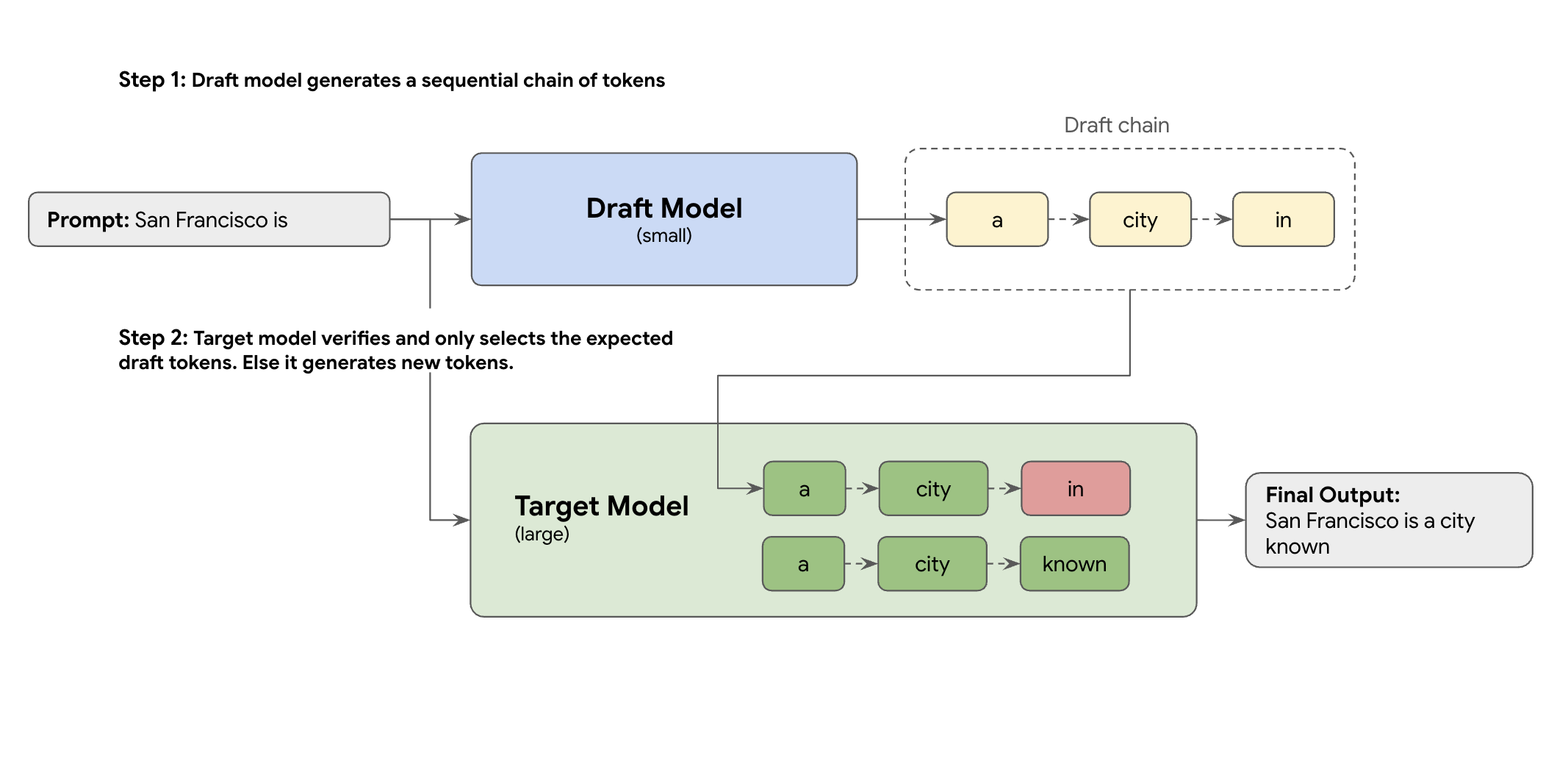
解决方案是推测解码。这种优化技术通过引入草稿机制,加快了大型 LLM(目标模型)一次生成一个 token 的缓慢顺序过程。
这种草稿机制可快速一次性提出多个下一个 token。然后,大型目标模型会在单个并行批次中验证这些提议。它会接受来自自身预测的最长匹配前缀,并从该新点继续生成。
但并非所有草稿机制都一样。传统的草稿-目标方法使用单独的较小 LLM 模型作为起草者,这意味着您必须托管和管理更多服务资源,从而产生额外费用。
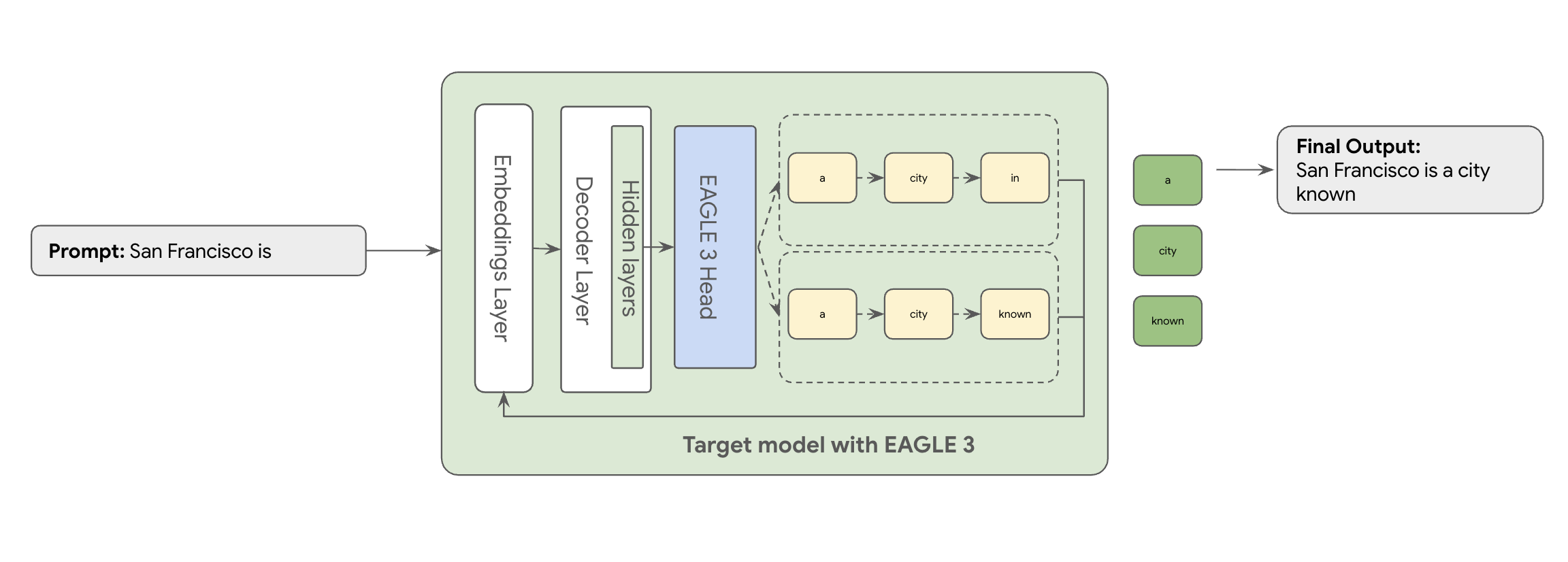
这正是 EAGLE-3(外推注意力引导学习)的用武之地。EAGLE-3 是一种更高级的方法。 它不会使用完全独立的模型,而是将极其轻量级的“草稿头”(仅占目标模型大小的 2-5%)直接附加到其内部层。此头在特征级和令牌级运行,从目标模型的隐藏状态提取特征,以推断和预测未来的令牌树。
结果如何呢?在消除训练和运行第二个模型的开销的同时,获得推测性解码的所有优势。
与训练和维护一个单独的、具有数十亿参数的草稿模型这一复杂且资源密集型任务相比,EAGLE-3 的方法效率更高。您只需训练一个轻量级“草稿头”(仅占目标模型大小的 2% 到 5%),该草稿头会作为一部分添加到现有模型中。这种更简单、更高效的训练流程可为 Llama 70B 等模型带来显著的 2 倍到 3 倍解码性能提升(具体取决于工作负载类型,例如多轮对话、代码、长上下文等)。
不过,即使是这种简化的 EAGLE-3 方法,从纸面到可大规模投入生产的云服务,也需要经历一段真正的工程之旅。本文将分享我们的技术流水线、关键挑战以及我们在这一过程中学到的宝贵经验。
挑战 1:准备数据
EAGLE-3 头需要训练。显而易见的第一步是获取可公开访问的通用数据集。这些数据集中的大多数都存在挑战,包括:
- 严格的使用条款:这些数据集是使用不允许将其用于开发与原始提供商竞争的模型的模型生成的。
- PII 污染:其中一些数据集包含大量 PII,包括姓名、位置信息,甚至财务标识符。
- 无法保证质量:某些数据集仅适用于一般“演示”用例,但无法最好地满足真实客户的专业工作负载需求。
无法直接使用这些数据。
课程 1:构建合成数据生成流水线
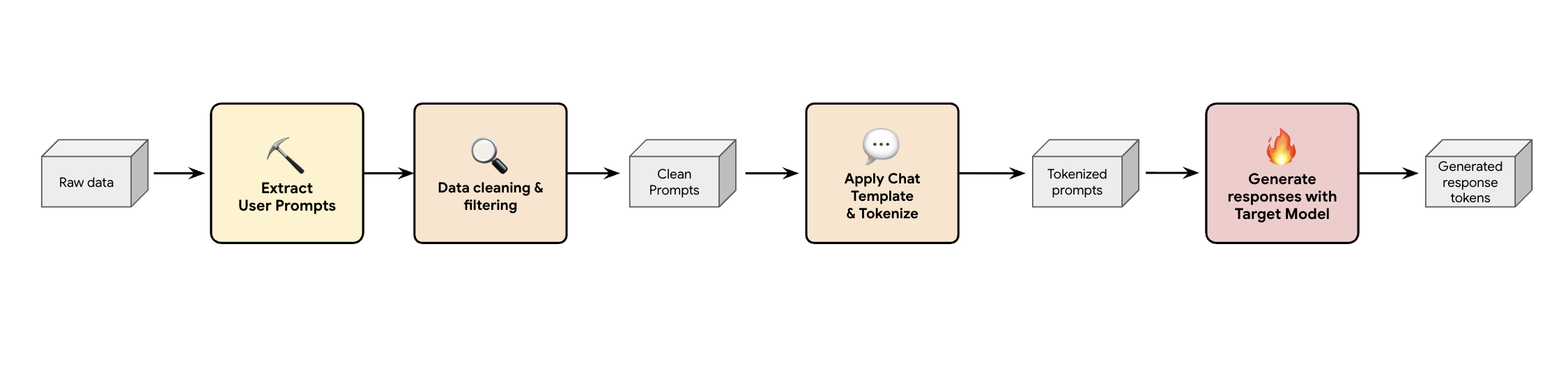
一种解决方案是构建合成数据生成流水线。我们会根据客户的使用情形选择合适的数据集,不仅要保证数据质量,还要确保数据集与客户的生产流量最匹配,以适应各种不同的工作负载。然后,您可以仅从这些数据集中提取用户提示,并应用严格的 DLP(数据泄露防护)和 PII 过滤。这些清理后的提示会应用聊天模板,对其进行分词,然后将其馈送到目标模型(例如Llama 3.3 70B)来收集其回答。
这种方法可提供目标生成的数据,这些数据不仅合规且干净,而且与模型的实际输出分布高度匹配。这非常适合训练选秀热门人选。
挑战 2:设计训练流水线
另一个关键决策是如何向 EAGLE-3 头提供训练数据。您有两条不同的途径:在线训练(即“即时生成”嵌入)和离线训练(即“在训练之前生成”嵌入)。
在本例中,我们选择了离线训练方法,因为与在线训练相比,它所需的硬件少得多。此过程涉及在训练 EAGLE-3 头之前预先计算所有特征和嵌入内容。我们将它们保存到 GCS,然后它们会成为轻量级 EAGLE-3 头的训练数据。获得数据后,训练本身会很快。鉴于 EAGLE-3 头部的尺寸非常小,使用原始数据集进行初始训练大约需要在一台主机上花费一天时间。不过,随着数据集规模的扩大,训练时间也相应增加,现在需要几天时间。

此过程让我们学到了两点不可忽视的经验,您需要牢记在心。
课程 2:聊天模板不是可选的
在训练指令调优模型时,我们发现当聊天模板不正确时,EAGLE-3 的性能可能会有很大差异。您必须应用目标模型的特定聊天模板(例如,在生成特征和嵌入之前,请先对 Llama 3 进行 token 化。如果您只是连接原始文本,则嵌入内容会不正确,并且您的头会学习预测错误的分布。
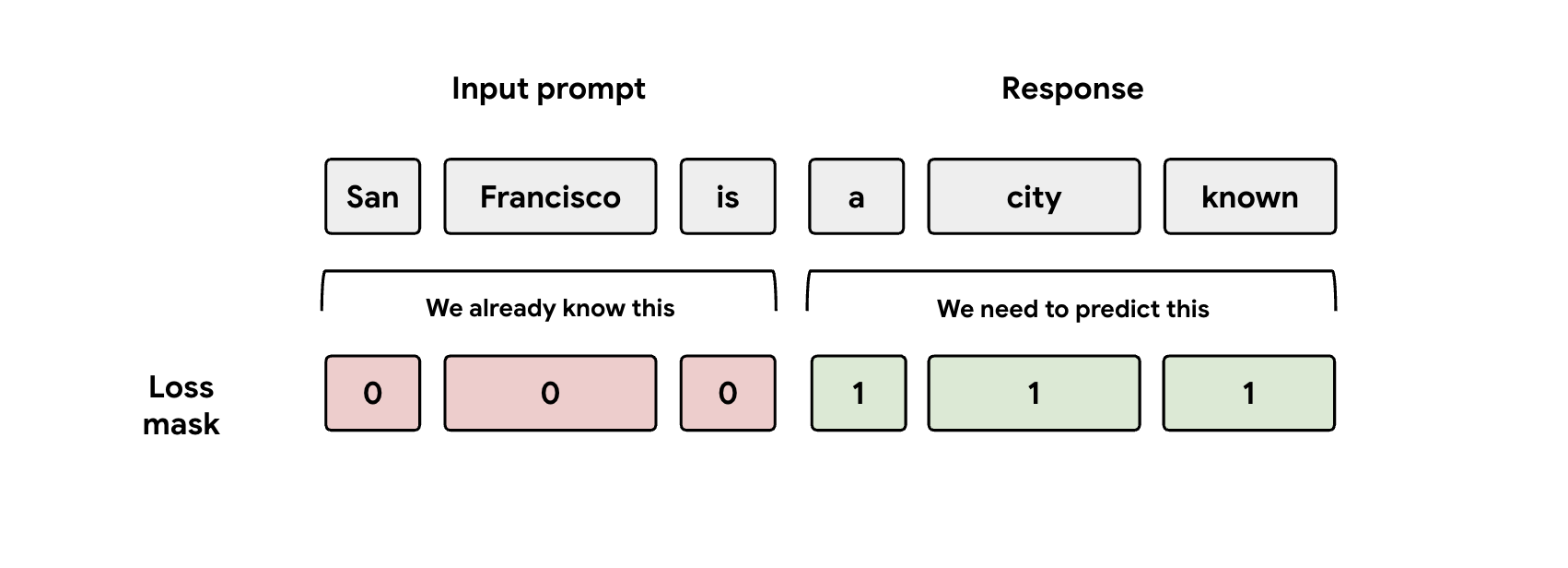
课程 3:注意遮盖
在训练期间,模型会同时接收提示和回答表示形式。但 EAGLE-3 头应该只学习预测回答表示。您必须在损失函数中手动遮盖提示部分。如果您不这样做,模型头会浪费容量来学习预测已给出的提示,从而导致性能下降。
挑战 3:提供服务和扩缩
在训练好 EAGLE-3 头部后,我们进入了提供阶段。此阶段带来了巨大的规模化挑战。以下是我们总结出的关键经验。
课程 4:服务框架至关重要
通过与 SGLang 团队密切合作,我们成功将 EAGLE-3 投入生产,并实现了最佳性能。从技术角度来看,这是因为 SGLang 实现了一个关键的树注意力内核。此特殊内核至关重要,因为 EAGLE-3 会生成一个可能的“草稿树”(而不仅仅是一个简单的链),而 SGLang 的内核专门设计用于在单个步骤中并行验证所有这些分支路径。否则,您将错失提升效果的机会。
课程 5:不要让 CPU 成为 GPU 的瓶颈
即使使用 EAGLE-3 加速 LLM 后,您也可能会遇到另一个性能瓶颈:CPU。当 GPU 运行 LLM 推理时,未优化的软件会在 CPU 开销(例如内核启动和元数据簿记)上浪费大量时间。在正常的同步调度器中,GPU 运行一个步骤(例如 Draft),然后在 CPU 执行其簿记并启动下一个 Verify 步骤时处于空闲状态。这些同步气泡会累积起来,浪费大量宝贵的 GPU 时间。

我们通过使用 SGLang 的零开销重叠调度器解决了这个问题。此调度器专门针对推测性解码的多步草稿 -> 验证 -> 草稿扩展工作流进行了调整。关键在于重叠计算。当 GPU 忙于运行当前的验证步骤时,CPU 已经并行工作,为下一个草稿和草稿扩展步骤启动内核。这可确保 GPU 的下一个作业始终处于就绪状态,从而消除空闲气泡。为此,我们使用 FutureMap(一种智能数据结构,可让 CPU 在 GPU 仍在工作时准备下一批数据)。

通过消除这种 CPU 开销,重叠调度器可全面提升 10% 到 20% 的速度。这证明,出色的模型只是成功的一半;您还需要能够跟上节奏的运行时。
基准结果
这段旅程是否值得?当然可以。
我们使用 SGLang 和 Llama 4 Scout 17B Instruct 对训练后的 EAGLE-3 头与非推测性基准进行了基准比较。我们的基准比较结果显示,根据工作负载类型的不同,解码延迟缩短了 2 倍到 3 倍,吞吐量也显著提升。
如需查看完整详情,请使用我们的全面笔记本自行进行基准比较。
指标 1:每个输出 token 的中位时间 (TPOT)
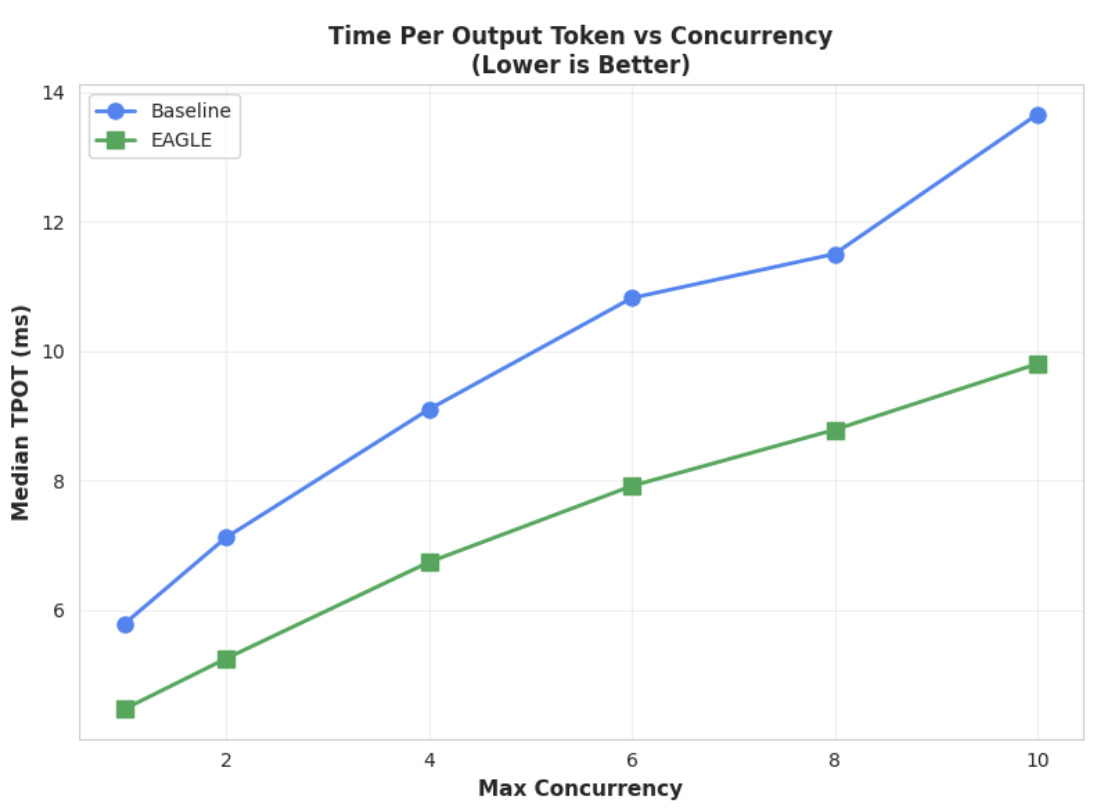
此图表显示了 EAGLE-3 更好的延迟时间性能。每个输出令牌的时间 (TPOT) 图表显示,在所有测试的并发级别下,EAGLE-3 加速模型(绿线)始终比基准模型(蓝线)实现了更低的(更快的)延迟时间。
指标 2:输出吞吐量
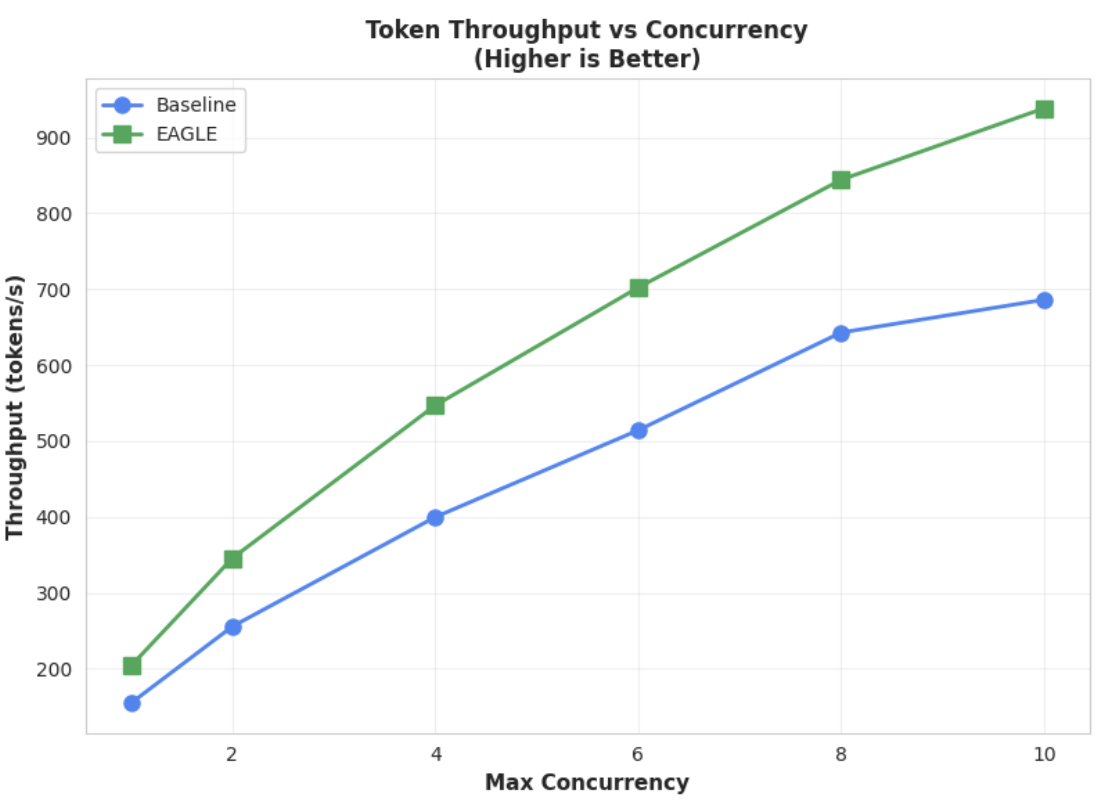
此图表进一步突显了 EAGLE-3 的吞吐量优势。“令牌吞吐量与并发性”图表清楚地表明,EAGLE-3 加速模型(绿线)始终大幅优于基准模型(蓝线)。
虽然对于更大的模型,类似的观察结果也成立,但值得注意的是,与其他性能指标相比,第一个 token 的时间 (TTFT) 可能会增加。此外,这些性能因任务而异,如以下示例所示:
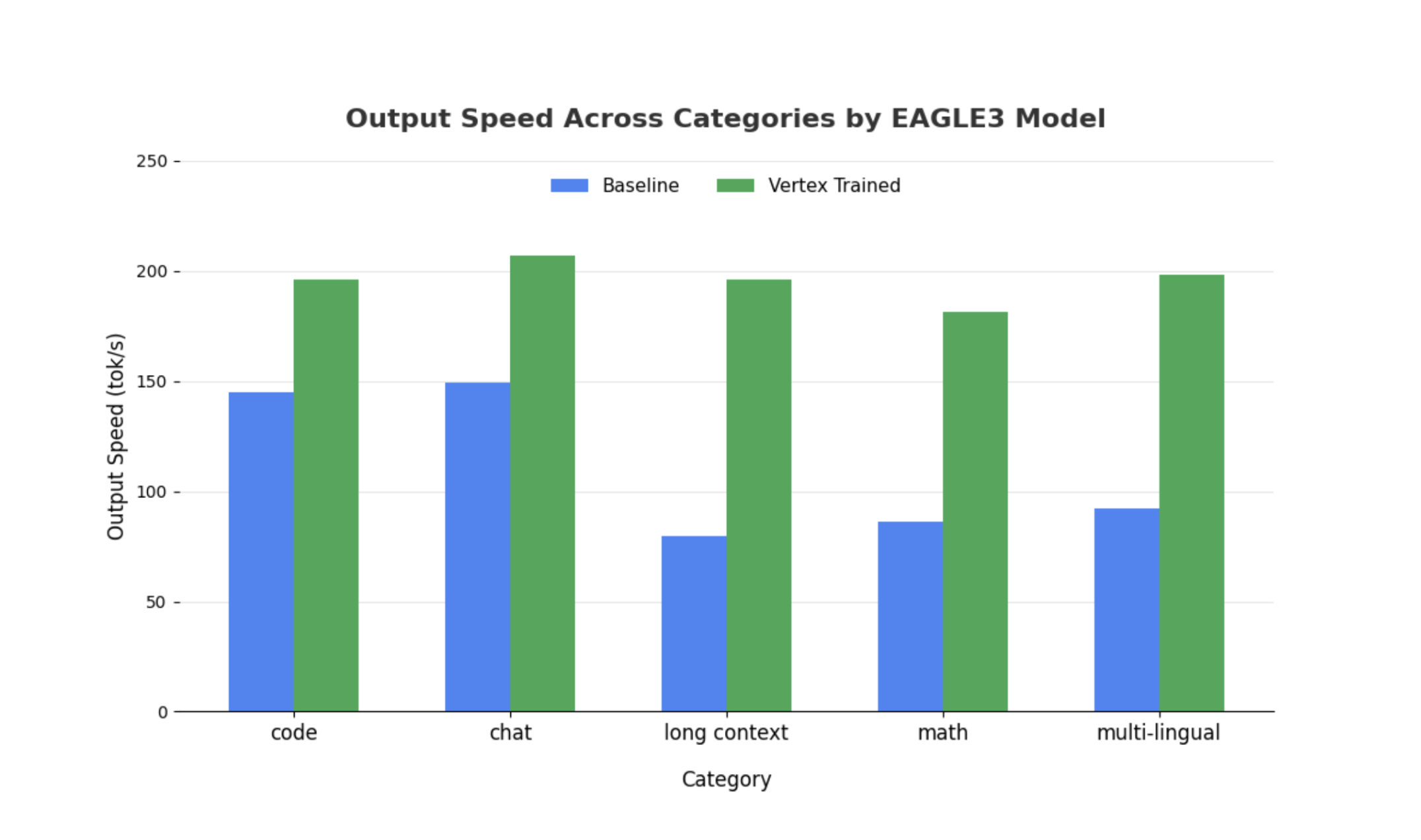
结尾:现在,轮到您大显身手了
EAGLE-3 不仅仅是一个研究概念,更是一种可用于生产环境的模式,可将解码延迟时间缩短一半。但要实现大规模应用,需要付出真正的工程努力。如需为用户可靠地部署此技术,您必须:
- 构建合规的合成数据流水线。
- 正确处理聊天模板和损失掩码,并在大规模数据集上训练模型。
在 Vertex AI 上,我们已经为您简化了整个流程,提供了一个经过优化的容器和基础设施,旨在扩缩基于 LLM 的应用。如需开始使用,请参阅以下资源:
感谢阅读
欢迎您就 Vertex AI 向我们提供反馈和提出问题。
致谢
我们要向 SGLang 团队(尤其是 Ying Sheng、Lianmin Zheng、Yineng Zhang、Xinyuan Tong、Liangsheng Yin)以及 SGLang/SpecForge 团队(尤其是 Shenggui Li、Yikai Zhu)表示衷心的感谢,感谢他们在整个项目过程中提供的宝贵支持。 他们慷慨的帮助和深入的技术见解对本项目的成功至关重要。