

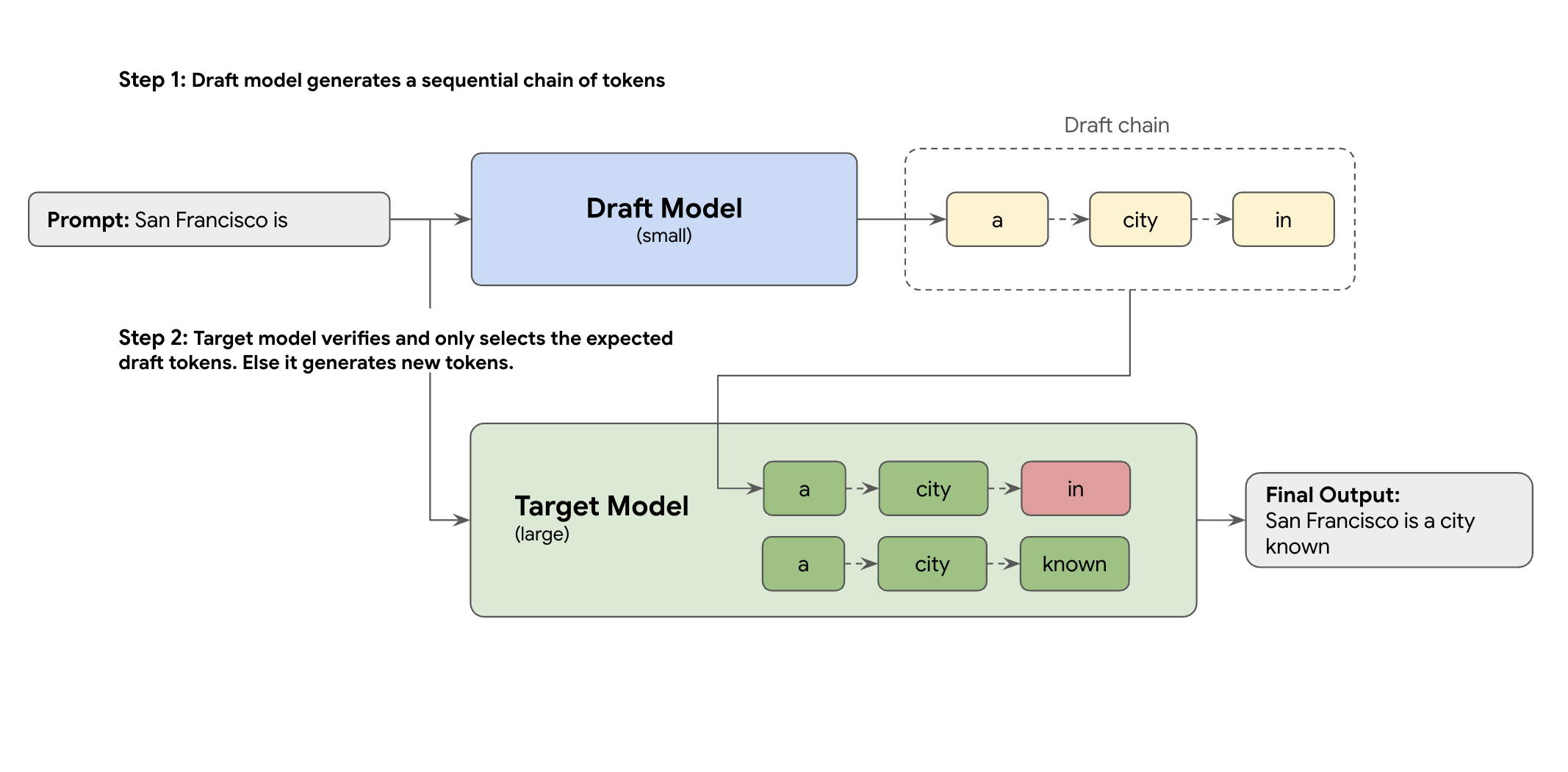
A solução é a descodificação especulativa. Esta técnica de otimização acelera o processo lento e sequencial do seu GML grande (o modelo de destino) que gera um token de cada vez, através da introdução de um mecanismo de rascunho.
Este mecanismo de rascunho propõe rapidamente vários tokens seguintes de uma só vez. O modelo de destino grande valida estas propostas num único lote paralelo. Aceita o prefixo correspondente mais longo das suas próprias previsões e continua a geração a partir desse novo ponto.
No entanto, nem todos os mecanismos de rascunho são criados da mesma forma. A abordagem clássica de rascunho-alvo usa um modelo de MDG separado e mais pequeno como o criador de rascunhos, o que significa que tem de alojar e gerir mais recursos de publicação, o que causa custos adicionais.
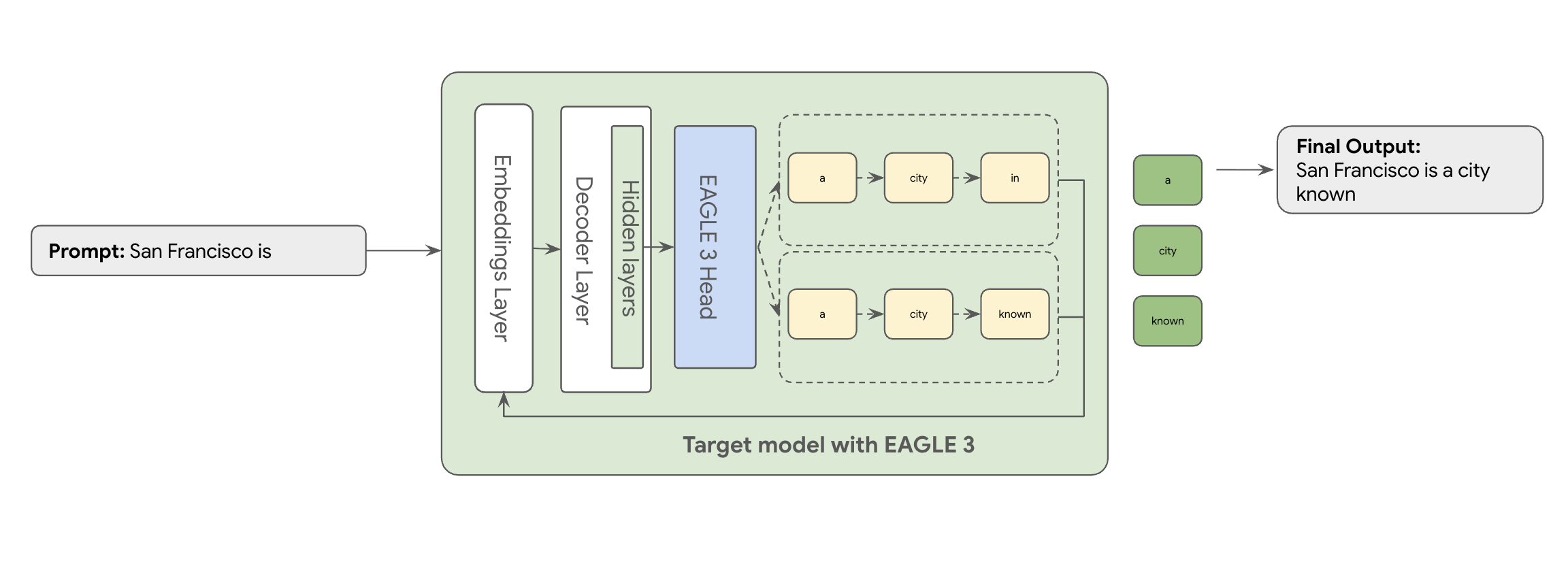
É aqui que entra o EAGLE-3 (Extrapolative Attention Guided LEarning). O EAGLE-3 é uma abordagem mais avançada. Em vez de um modelo totalmente separado, anexa um "cabeçalho de rascunho" extremamente leve, apenas 2 a 5% do tamanho do modelo de destino, diretamente às respetivas camadas internas. Este cabeçalho funciona ao nível das funcionalidades e dos tokens, incorporando funcionalidades dos estados ocultos do modelo de destino para extrapolar e prever uma árvore de tokens futuros.
O resultado? Todas as vantagens da descodificação especulativa, ao mesmo tempo que elimina a sobrecarga da preparação e execução de um segundo modelo.
A abordagem do EAGLE-3 é muito mais eficiente do que a tarefa complexa e com utilização intensiva de recursos de formar e manter um modelo de rascunho separado com vários milhares de milhões de parâmetros. Prepara apenas um "esboço" simples, que representa apenas 2% a 5% do tamanho do modelo de destino, e que é adicionado como parte do seu modelo existente. Este processo de preparação mais simples e eficiente oferece um aumento significativo de 2 a 3 vezes no desempenho da descodificação para modelos como o Llama 70B (dependendo dos tipos de carga de trabalho, por exemplo, de várias interações, código, contexto longo e muito mais).
No entanto, a mudança desta abordagem EAGLE-3 simplificada de um papel para um serviço na nuvem dimensionado e pronto para produção é um verdadeiro percurso de engenharia. Esta publicação partilha o nosso pipeline técnico, os principais desafios e as lições que aprendemos ao longo do caminho.
Desafio n.º 1: preparar os dados
O cabeçalho EAGLE-3 tem de ser preparado. O primeiro passo óbvio é obter um conjunto de dados genérico disponível publicamente. A maioria destes conjuntos de dados apresenta desafios, incluindo:
- Termos de Utilização rigorosos: estes conjuntos de dados são gerados através de modelos que não permitem a sua utilização para desenvolver modelos que concorram com os fornecedores originais.
- Contaminação por IIP: alguns destes conjuntos de dados contêm IIP significativas, incluindo nomes, localizações e até identificadores financeiros.
- Qualidade não garantida: alguns conjuntos de dados só funcionam bem para exemplos de utilização de "demonstração" gerais, mas não funcionam melhor para a carga de trabalho especializada de clientes reais.
Não é possível usar estes dados tal como estão.
Lição 1: crie um pipeline de geração de dados sintéticos
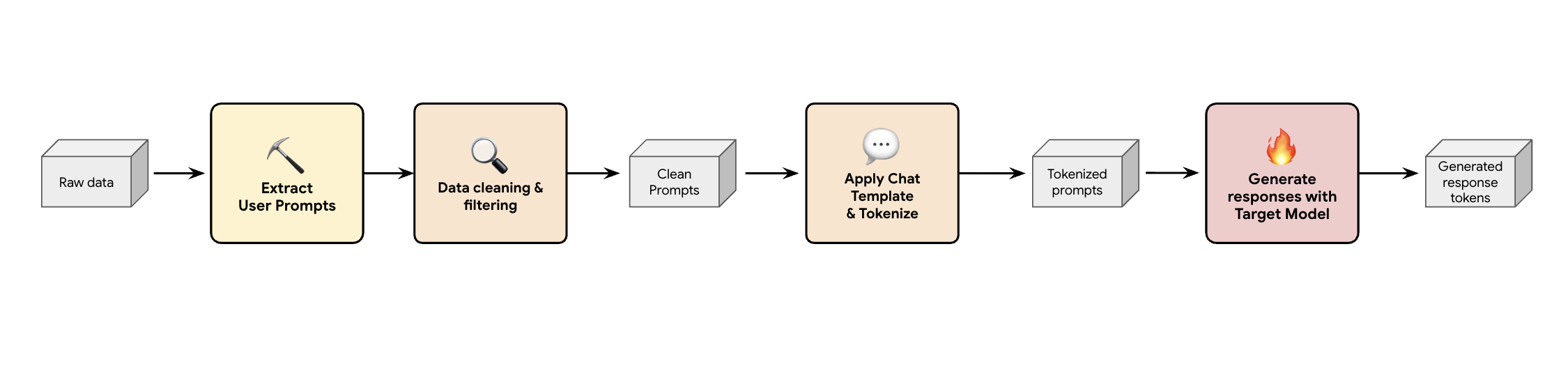
Uma solução é criar um pipeline de geração de dados sintéticos. Consoante os exemplos de utilização dos nossos clientes, selecionamos o conjunto de dados certo não só com boa qualidade, mas também que corresponda melhor ao tráfego de produção dos nossos clientes para várias cargas de trabalho diferentes. Em seguida, pode extrair apenas os comandos do utilizador destes conjuntos de dados e aplicar uma filtragem rigorosa de DLP (prevenção contra a perda de dados) e PII. Estes comandos limpos aplicam um modelo de chat, tokenizam-nos e, em seguida, podem ser introduzidos no modelo de destino (por exemplo, Llama 3.3 70B) para recolher as respetivas respostas.
Esta abordagem fornece dados gerados pelo destino que não são apenas conformes e limpos, mas também bem adequados à distribuição de resultados real do modelo. Isto é ideal para preparar o cabeçalho do rascunho.
Desafio n.º 2: criar o pipeline de preparação
Outra decisão fundamental é como fornecer os dados de preparação ao cabeçalho do EAGLE-3. Tem dois caminhos distintos: formação online, onde as incorporações são "geradas em tempo real", e formação offline, onde "as incorporações são geradas antes da formação".
No nosso caso, escolhemos uma abordagem de formação offline porque requer muito menos hardware do que a formação online. Este processo envolve o pré-cálculo de todas as funcionalidades e incorporações antes de prepararmos o EAGLE-3. Guardamo-los no GCS e tornam-se os dados de preparação para a nossa arquitetura EAGLE-3 simplificada. Depois de ter os dados, a preparação em si é rápida. Dado o tamanho diminuto da cabeça do EAGLE-3, a preparação inicial com o nosso conjunto de dados original demorou aproximadamente um dia num único anfitrião. No entanto, à medida que dimensionámos o nosso conjunto de dados, os tempos de preparação aumentaram proporcionalmente, abrangendo agora vários dias.

Este processo ensinou-nos duas lições importantes que deve ter em atenção.
Lição 2: os modelos de chat não são opcionais
Durante a preparação do modelo ajustado às instruções, verificámos que o desempenho do EAGLE-3 pode variar muito quando o modelo de chat não está correto. Tem de aplicar o modelo de chat específico do modelo de destino (por exemplo, Llama 3) antes de gerar as funcionalidades e as incorporações. Se apenas concatenar texto inserido, as incorporações vão estar incorretas e o seu cabeçalho vai aprender a prever a distribuição errada.
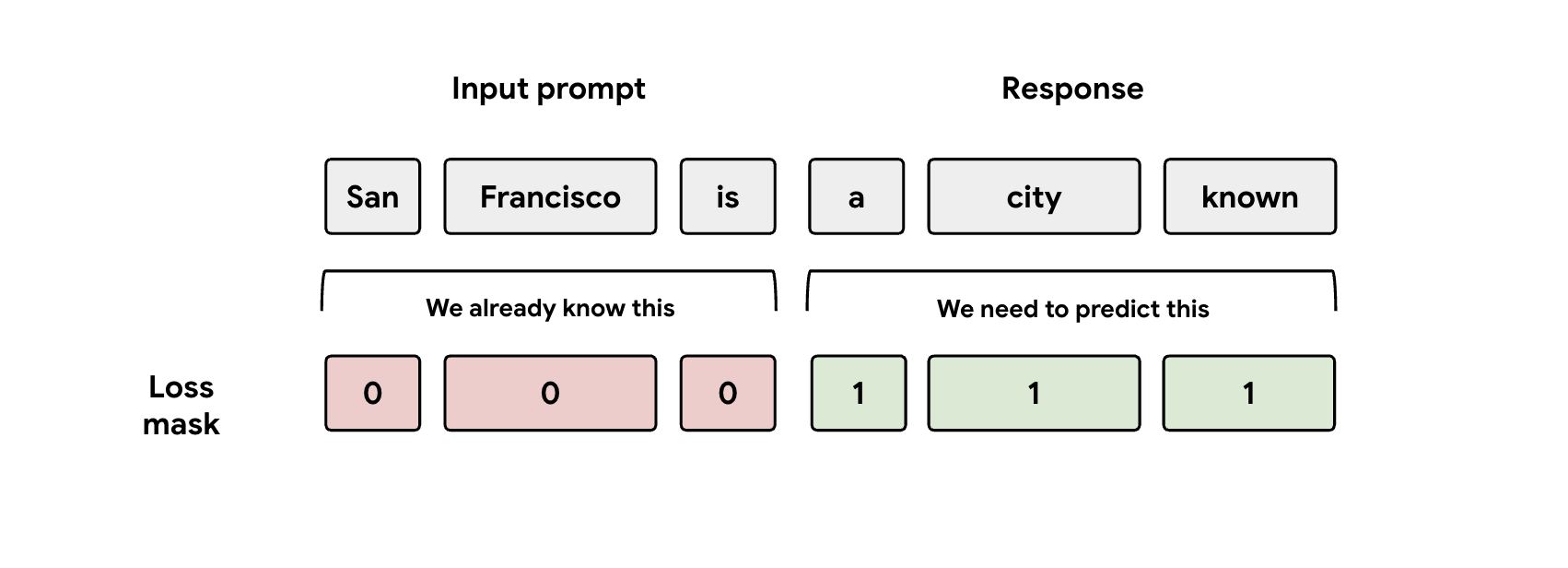
Lição 3: tenha cuidado com a máscara
Durante a preparação, o modelo recebe as representações do comando e da resposta. No entanto, o cabeçalho do EAGLE-3 só deve aprender a prever a representação da resposta. Tem de mascarar manualmente a parte do comando na função de perda. Se não o fizer, o cabeçalho desperdiça capacidade de aprendizagem para prever o comando que já lhe foi dado, e o desempenho vai sofrer.
Desafio n.º 3: publicação e escalabilidade
Com um cabeçalho EAGLE-3 preparado, avançámos para a fase de publicação. Esta fase introduziu desafios de escalabilidade significativos. Seguem-se as nossas principais aprendizagens.
Lição 4: a sua estrutura de publicação é fundamental
Ao trabalhar em estreita colaboração com a equipa do SGLang, implementámos com êxito o EAGLE-3 na produção com o melhor desempenho. O motivo técnico é que o SGLang implementa um kernel de atenção de árvore crucial. Este kernel especial é crucial porque o EAGLE-3 gera uma "árvore de rascunho" de possibilidades (não apenas uma simples cadeia) e o kernel do SGLang foi concebido especificamente para validar todos esses caminhos ramificados em paralelo num único passo. Sem esta, está a perder desempenho.
Lição 5: não deixe que a CPU limite o desempenho da GPU
Mesmo depois de acelerar o seu MDG com o EAGLE-3, pode atingir outro limite de desempenho: a CPU. Quando as suas GPUs estão a executar a inferência de MDIs, o software não otimizado desperdiça uma grande quantidade de tempo na sobrecarga da CPU, como o lançamento do kernel e a gestão de metadados. Num agendador síncrono normal, a GPU executa um passo (como Rascunho) e, em seguida, fica inativa enquanto a CPU faz o seu trabalho administrativo e inicia o passo Validar seguinte. Estas bolhas de sincronização acumulam-se, desperdiçando grandes quantidades de tempo valioso da GPU.

Resolvi este problema usando o Zero-Overhead Overlap Scheduler do SGLang. Este agendador está especificamente otimizado para o fluxo de trabalho de descodificação especulativa de vários passos Rascunho -> Verificar -> Extensão do rascunho . O importante é sobrepor a computação. Enquanto a GPU está ocupada a executar o passo Validar atual, a CPU já está a trabalhar em paralelo para iniciar os núcleos dos passos seguintes Rascunho e Estender rascunho .
Isto elimina a bolha inativa, garantindo que a próxima tarefa da GPU está sempre pronta, usando uma FutureMap, uma estrutura de dados inteligente que permite à CPU preparar o próximo lote ENQUANTO a GPU ainda está a funcionar.

Ao eliminar esta sobrecarga da CPU, o programador de sobreposição oferece-nos um aumento de velocidade de 10% a 20% em geral. Isto prova que um excelente modelo é apenas metade da batalha. Precisa de um tempo de execução que consiga acompanhar.
Resultados de testes de referência
Depois desta viagem, valeu a pena? Claro.
Comparámos o nosso modelo EAGLE-3 treinado com a base não especulativa usando o SGLang com o Llama 4 Scout 17B Instruct. Os nossos testes de referência mostram um aumento de 2 a 3 vezes na latência de descodificação e ganhos significativos de débito, consoante os tipos de carga de trabalho.
Veja os detalhes completos e faça o teste de referência você mesmo com o nosso notebook abrangente.
Métrica 1: tempo mediano por token de saída (TPOT)
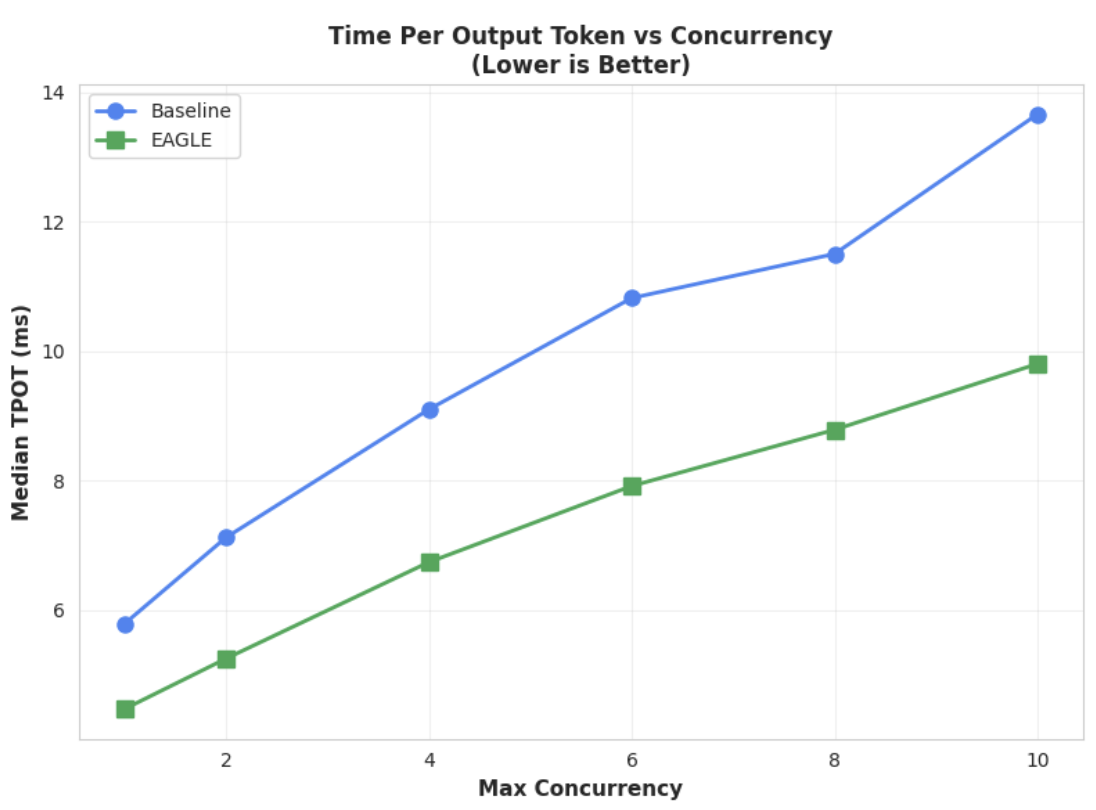
Este gráfico mostra o melhor desempenho de latência do EAGLE-3. O gráfico Tempo por token de saída (TPOT) mostra que o modelo acelerado EAGLE-3 (linha verde) atinge consistentemente uma latência inferior (mais rápida) do que a base (linha azul) em todos os níveis de concorrência testados.
Métrica 2: débito de saída
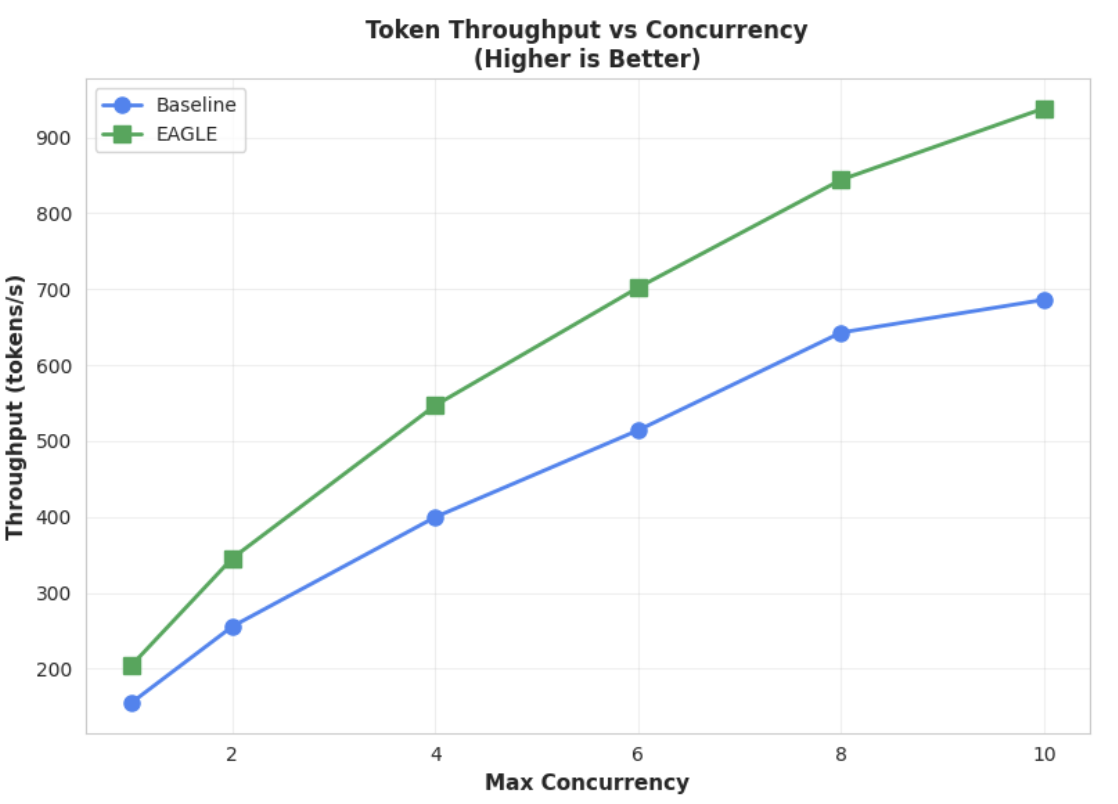
Este gráfico realça ainda mais a vantagem de débito do EAGLE-3. O gráfico de débito de tokens vs. concorrência demonstra claramente que o modelo acelerado EAGLE-3 (linha verde) supera de forma consistente e substancial o modelo de base (linha azul).
Embora as observações semelhantes se mantenham verdadeiras para modelos maiores, vale a pena notar que pode observar um aumento no tempo até ao primeiro token (TTFT) em comparação com outras métricas de desempenho. Além disso, estes desempenhos variam consoante a tarefa, como ilustrado pelos seguintes exemplos:
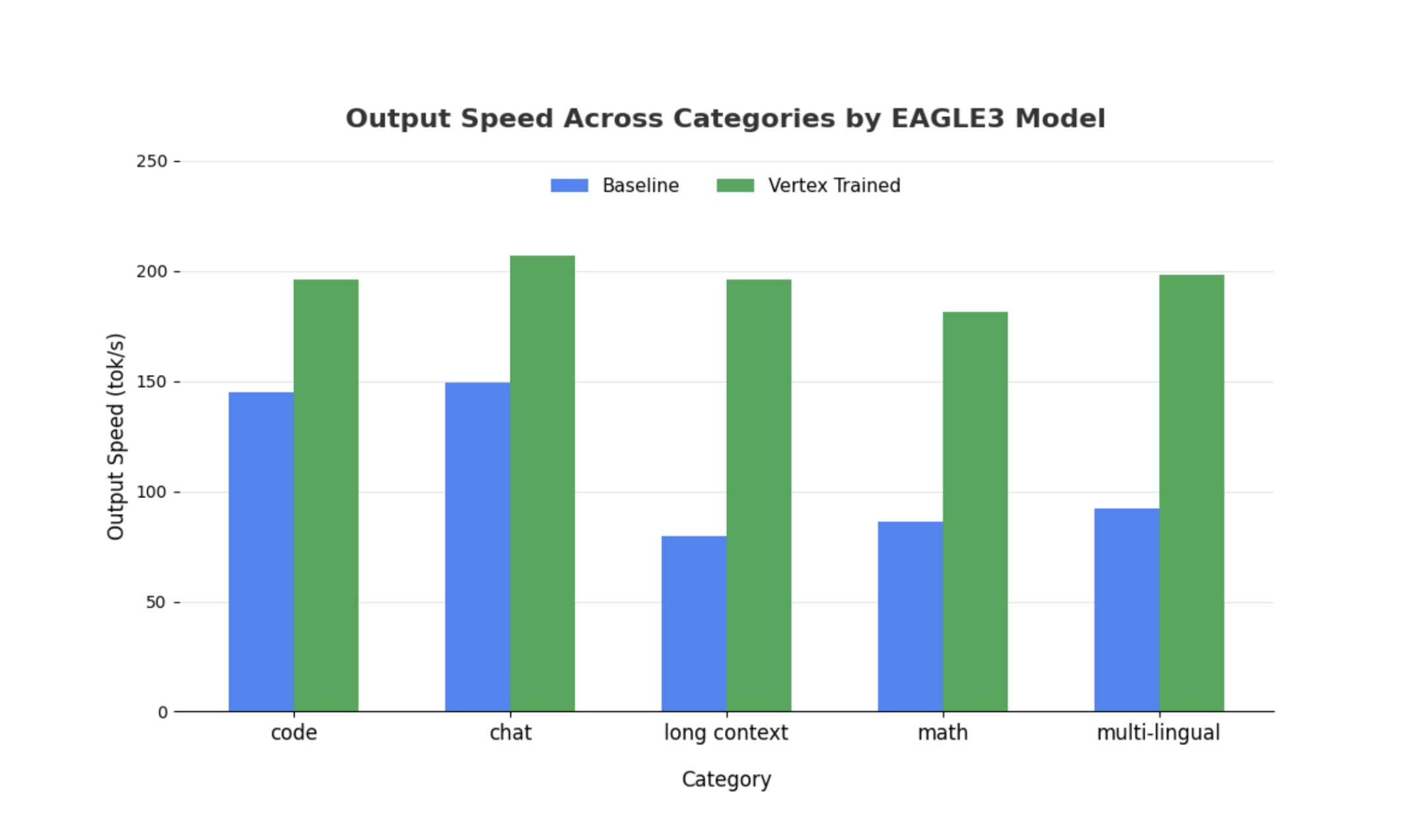
Conclusão: agora é a sua vez
O EAGLE-3 não é apenas um conceito de investigação, mas um padrão pronto para produção que pode oferecer um aumento tangível de 2x na latência de descodificação. No entanto, para o expandir, é necessário um verdadeiro esforço de engenharia. Para implementar esta tecnologia de forma fiável para os seus utilizadores, tem de:
- Crie um pipeline de dados sintéticos em conformidade.
- Processar corretamente modelos de chat e máscaras de perda, e formar o modelo numa grande escala de conjunto de dados.
No Vertex AI, já simplificámos todo este processo para si, oferecendo-lhe um contentor e uma infraestrutura otimizados concebidos para dimensionar as suas aplicações baseadas em MDIs. Para começar, consulte os seguintes recursos:
Agradecemos a leitura
Agradecemos o seu feedback e perguntas sobre a Vertex AI.
Confirmações
Gostaríamos de expressar a nossa sincera gratidão à equipa da SGLang, especificamente a Ying Sheng, Lianmin Zheng, Yineng Zhang, Xinyuan Tong e Liangsheng Yin, bem como à equipa da SGLang/SpecForge, especificamente a Shenggui Li e Yikai Zhu, pelo seu apoio inestimável ao longo deste projeto. A sua generosa assistência e estatísticas técnicas detalhadas foram fundamentais para o sucesso deste projeto.