

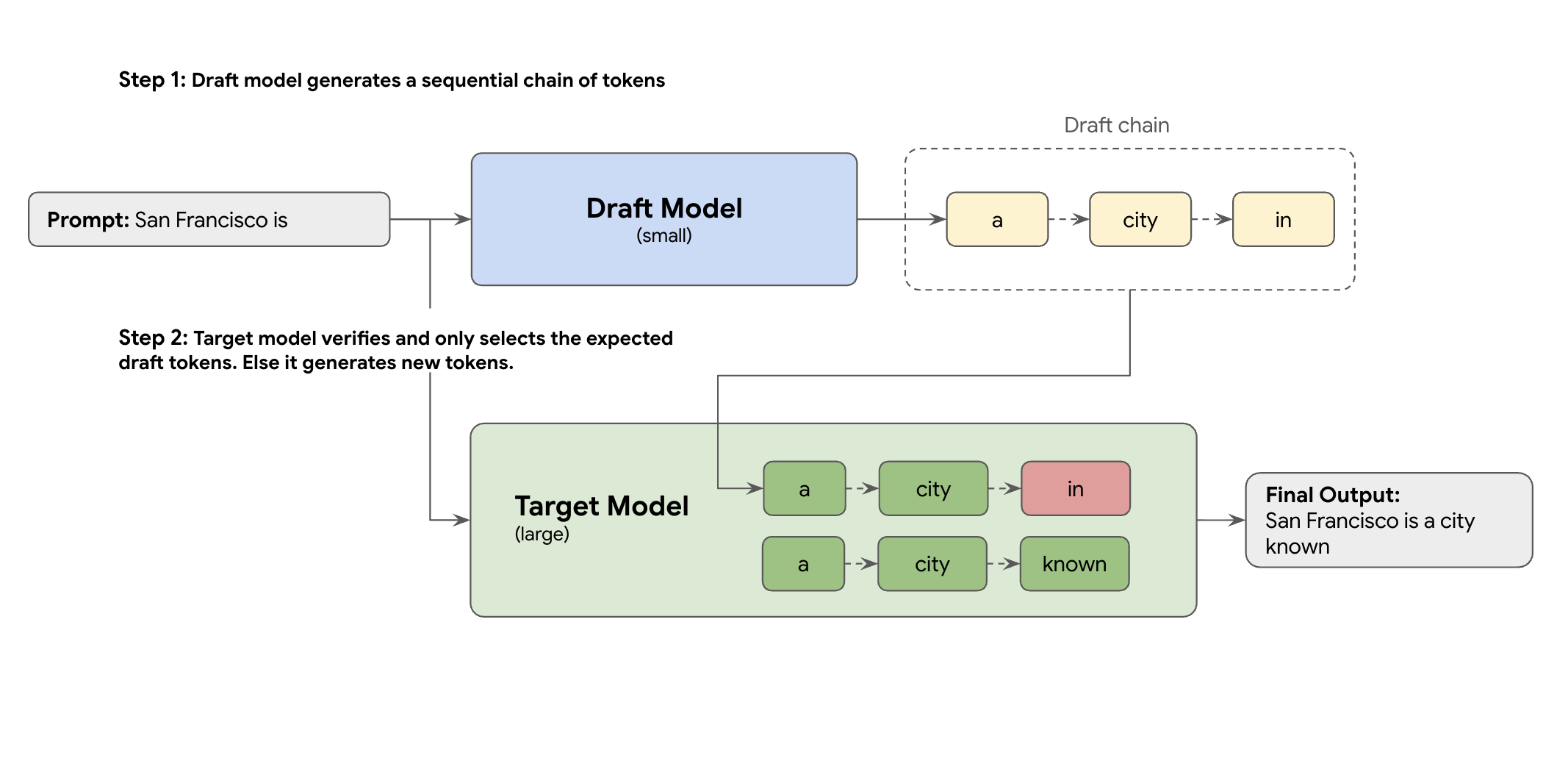
해결 방법은 추측 디코딩입니다. 이 최적화 기법은 초안 메커니즘을 도입하여 대규모 LLM(대상 모델)이 토큰을 한 번에 하나씩 생성하는 느리고 순차적인 프로세스를 가속화합니다.
이 초안 메커니즘은 한 번에 여러 개의 다음 토큰을 신속하게 제안합니다. 그러면 대규모 대상 모델은 이러한 제안들을 단일 병렬 배치로 검증합니다. 모델은 자체 예측에서 일치하는 가장 긴 프리픽스를 선택하고, 해당 지점부터 생성을 계속합니다.
하지만 모든 초안 메커니즘이 동일하게 만들어지는 것은 아닙니다. 기존의 초안-타겟 접근 방식은 초안 작성자가 별도의 소규모 LLM 모델을 사용하기 때문에 더 많은 서비스 리소스를 호스팅하고 관리해야 하므로 추가 비용이 발생합니다.
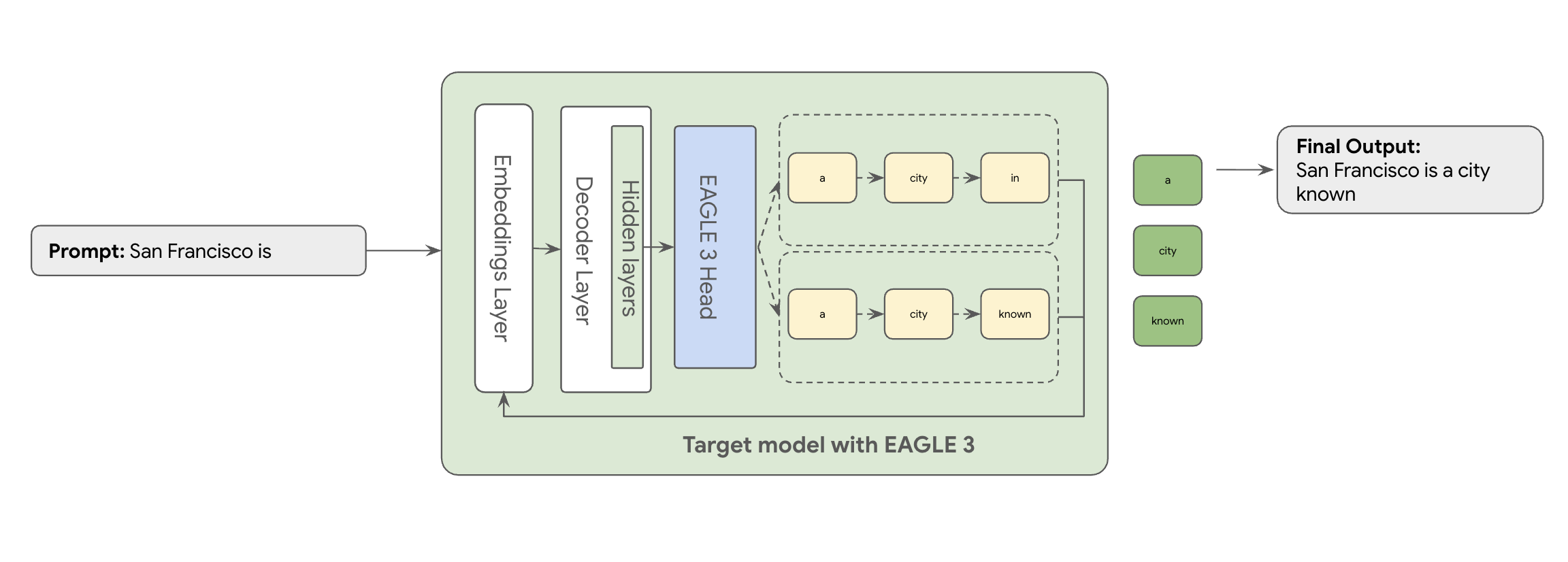
이때 EAGLE-3(Extrapolative Attention Guided LEarning)가 사용됩니다. EAGLE-3는 더 발전된 접근 방식입니다. 완전히 별개의 모델을 사용하는 대신, 타겟 모델 크기의 2~5%에 불과한 매우 가벼운 '초안 헤드'를 타겟 모델의 내부 레이어에 직접 연결합니다. 이 헤드는 특성 수준과 토큰 수준 모두에서 작동하며, 타겟 모델의 은닉 상태에서 특성을 수집하여 미래 토큰의 트리 구조를 예측합니다.
그 결과 두 번째 모델을 학습하고 실행하는 오버헤드를 제거하면서 추측 디코딩의 모든 이점을 누릴 수 있습니다.
EAGLE-3의 접근 방식은 수십억 개의 파라미터가 있는 별도의 초안 모델을 학습하고 유지 관리하는 복잡하고 리소스 집약적인 태스크보다 훨씬 효율적입니다. 기존 모델의 일부로 추가되는 가벼운 '초안 헤드'(타겟 모델 크기의 2~5%)만 학습합니다. 이처럼 간단하고 효율적인 학습 프로세스는 Llama 70B와 같은 모델에서 작업 부하 유형(예: 멀티턴, 코드, 긴 텍스트 등)에 따라 디코딩 성능을 2~3배 향상시킵니다.
하지만 이처럼 간소화된 EAGLE-3 접근 방식조차도 이론 단계에서 확장 가능한 프로덕션 레디 클라우드 서비스로 구현하는 것은 실제 엔지니어링 여정입니다. 이 글에서는 기술 파이프라인, 주요 과제, 그리고 그 과정에서 얻은 유용한 교훈을 공유합니다.
과제 #1: 데이터 준비
EAGLE-3 헤드를 학습시켜야 합니다. 당연히 가장 먼저 해야 할 일은 일반적인 공개 데이터 세트를 확보하는 것입니다. 이러한 데이터 세트 대부분은 다음과 같은 문제를 안고 있습니다.
- 엄격한 이용약관: 이러한 데이터 세트는 원래 제공업체와 경쟁하는 모델을 개발하는 데 사용할 수 없도록 설계된 모델을 사용하여 생성됩니다.
- PII 오염: 이러한 데이터 세트 중 일부에는 이름, 위치, 금융 식별자를 비롯한 상당한 PII가 포함되어 있습니다.
- 품질 보장 불가: 일부 데이터 세트는 일반적인 '데모' 사용 사례에 적합하며 실제 고객의 특수 워크로드에는 적합하지 않습니다.
이 데이터를 그대로 사용하는 것은 불가능합니다.
강의 1: 합성 데이터 생성 파이프라인 빌드
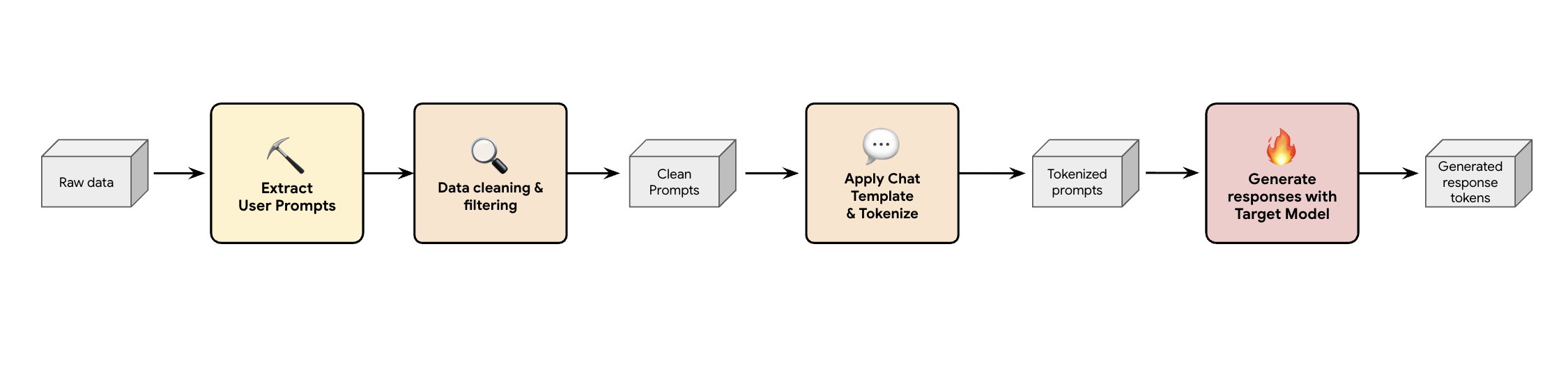
한 가지 해결 방법은 합성 데이터 생성 파이프라인을 빌드하는 것입니다. Google은 고객의 사용 사례에 따라 품질이 우수할 뿐만 아니라 다양한 워크로드에 대해 고객의 프로덕션 트래픽과 가장 잘 일치하는 적절한 데이터 세트를 선택합니다. 그런 다음 이러한 데이터 세트에서 사용자 프롬프트만 추출하고 엄격한 DLP(데이터 손실 방지) 및 PII 필터링을 적용할 수 있습니다. 이러한 정리 프롬프트는 채팅 템플릿을 적용하고 토큰화한 후 타겟 모델 (예: Llama 3.3 70B)에 입력하여 대답을 수집합니다.
이 접근 방식은 규정을 준수하는 정리된 데이터뿐만 아니라 모델의 실체 출력 분포와도 잘 일치하는 타겟 생성 데이터를 제공합니다. 이 방식은 초안 헤드 학습에 적합합니다.
과제 #2: 학습 파이프라인 엔지니어링
또 다른 중요한 결정 사항은 EAGLE-3 헤드에 학습 데이터를 제공하는 방법입니다. 크게 두 가지 방식이 있는데, 하나는 임베딩이 '실시간으로 생성되는' 온라인 학습이고, 다른 하나는 '학습 전에 임베딩이 생성되는' 오프라인 학습입니다.
여기에서는 온라인 학습보다 하드웨어가 훨씬 적게 필요한 오프라인 학습을 선택했습니다. 이 과정은 EAGLE-3 헤드를 학습시키기 전에 모든 특성과 임베딩을 미리 계산하는 것을 포함합니다. 계산된 데이터는 GCS에 저장되며 경량형 EAGLE-3 헤드의 학습 데이터로 활용됩니다. 데이터 준비가 완료되면 학습 자체는 신속하게 진행됩니다. EAGLE-3 헤드의 크기가 작기 때문에 초기 학습은 단일 호스트에서 기존 데이터 세트 기준으로 약 하루가 소요되었습니다. 그러나 데이터 세트 규모가 확장됨에 따라 학습 시간도 비례하여 증가하여 현재는 며칠이 소요됩니다.

이 과정에서 반드시 명심해야 할 두 가지 중요한 교훈을 얻었습니다.
강의 2: 채팅 템플릿은 선택사항이 아님
요청 사항 조정이 적용된 모델을 학습하는 과정에서 채팅 템플릿이 올바르지 않으면 EAGLE-3의 성능이 크게 달라질 수 있다는 것을 확인했습니다. 특성과 임베딩을 생성하기 전에 타겟 모델(예: Llama 3)에 맞는 특정 채팅 템플릿을 반드시 적용해야 합니다. 원시 텍스트를 연결하기만 하면 임베딩이 잘못 생성되며 헤드가 잘못된 분포를 예측하게 됩니다.
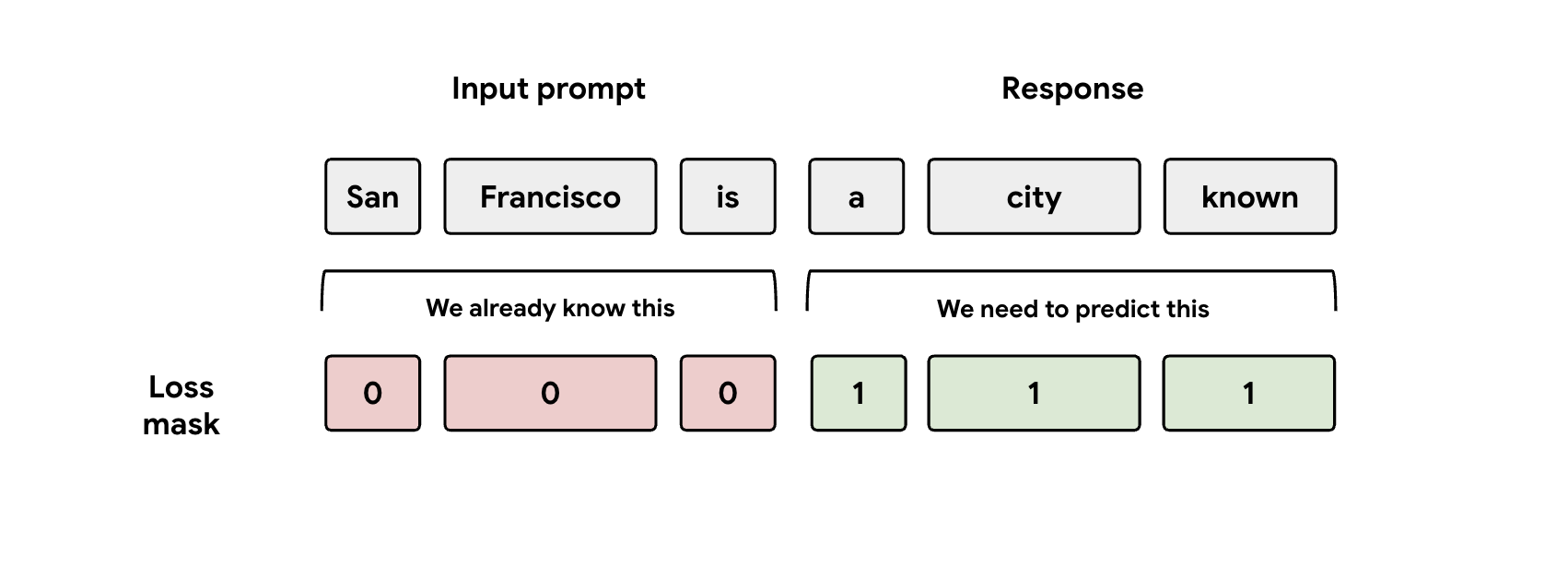
강의 3: 마스크에 유의하기
학습 중 모델에는 프롬프트와 응답 표현이 모두 입력됩니다. 하지만 EAGLE-3 헤드는 대답 표현만 예측하도록 학습해야 합니다. 따라서 손실 함수에서 프롬프트 부분을 수동으로 마스킹해야 합니다. 그렇지 않으면 헤드가 이미 입력된 프롬프트를 예측하는 데 용량을 낭비하게 되어 성능이 저하됩니다.
과제 #3: 서빙 및 확장
EAGLE-3 헤드를 학습시킨 후 서빙 단계로 넘어갔습니다. 이 단계에서는 상당한 확장성 문제가 발생했습니다. 주요 학습 내용은 다음과 같습니다.
강의 4: 서빙 프레임워크가 핵심임
SGLang 팀과의 긴밀한 협력을 통해 EAGLE-3를 최상의 성능으로 성공적으로 프로덕션 환경에 적용했습니다. 기술적인 이유는 SGLang에 핵심적인 트리 어텐션 커널을 구현했기 때문입니다. 이 특수 커널이 중요한 이유는 EAGLE-3가 단순한 연결 고리가 아닌, 다양한 가능성을 담은 '초안 트리'를 생성하기 때문이며, SGLang의 커널은 이러한 분기 경로를 모두 한 번에 병렬로 검증하도록 특별히 설계되었습니다. 이 커널이 없으면 성능 저하가 불가피합니다.
강의 5: CPU가 GPU의 병목 현상을 일으키지 않도록 방지
EAGLE-3를 사용하여 LLM을 가속화한 후에도 또 다른 성능 문제에 부딪힐 수 있습니다. 바로 CPU입니다. GPU가 LLM 추론을 실행할 때 최적화되지 않은 소프트웨어는 커널 실행 및 메타데이터 관리와 같은 CPU 오버헤드에 막대한 시간을 낭비합니다. 일반적인 동기식 스케줄러에서는 GPU가 한 단계(예: 초안)를 실행한 후 CPU가 관리 작업을 수행하고 다음 검증 단계를 시작하는 동안 유휴 상태가 됩니다. 이러한 동기화 버블이 누적되면서 귀중한 GPU 시간이 엄청나게 낭비됩니다.

이 문제는 SGLang의 제로 오버헤드 오버랩 스케줄러를 사용하여 해결했습니다. 이 스케줄러는 추측 디코딩의 다단계 워크플로(초안 -> 검증 -> 초안 확장)에 특화되어 있습니다. 핵심은 계산을 중첩하는 것입니다. GPU가 현재 검증 단계를 실행하는 동안 CPU는 이미 다음 초안 및 초안 확장 단계에 필요한 커널을 병렬로 실행합니다.
이렇게 하면 GPU가 항상 다음 작업을 처리할 수 있도록 FutureMap이라는 스마트 데이터 구조를 활용하여 GPU가 아직 작동 중일 때 CPU가 다음 배치를 준비할 수 있도록 함으로써 유휴 시간을 없앨 수 있습니다.

이 CPU 오버헤드를 제거함으로써 오버랩 스케줄러는 전반적인 속도를 10~20% 더 향상시킵니다. 이는 훌륭한 모델만으로는 충분하지 않으며, 그에 걸맞은 런타임이 필요하다는 것을 증명합니다.
벤치마크 결과
이 여정을 마치고 나니, 그럴 만한 가치가 있었을까요? 물론입니다.
SGLang 및 Llama 4 Scout 17B Instruct를 사용하여 학습된 EAGLE-3 헤드를 비추측 기준 모델과 비교 벤치마킹했습니다. 벤치마크 결과, 워크로드 유형에 따라 디코딩 지연 시간이 2~3배 단축되었고, 처리량도 크게 향상되었습니다.
자세한 내용은 포괄적인 노트북을 통해 확인하고 직접 벤치마킹해 보세요.
측정항목 1: 출력 토큰당 시간(TPOT) 중앙값
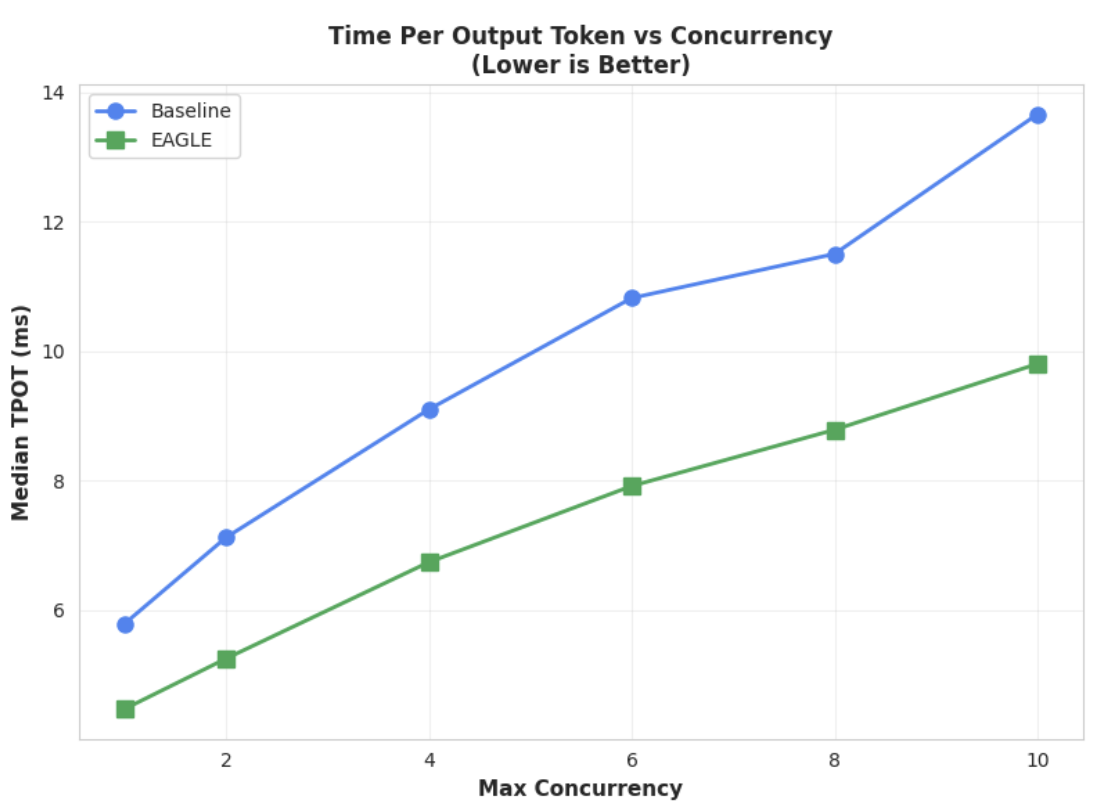
이 차트는 EAGLE-3의 더 짧아진 지연 시간을 보여줍니다. 출력 토큰당 시간(TPOT) 차트를 보면 EAGLE-3 가속 모델(녹색 선)의 지연 시간이 테스트된 모든 동시 실행 수준에서 기준 모델(파란색 선)보다 일관되게 낮다(빠르다)는 것을 알 수 있습니다.
측정항목 2: 출력 처리량
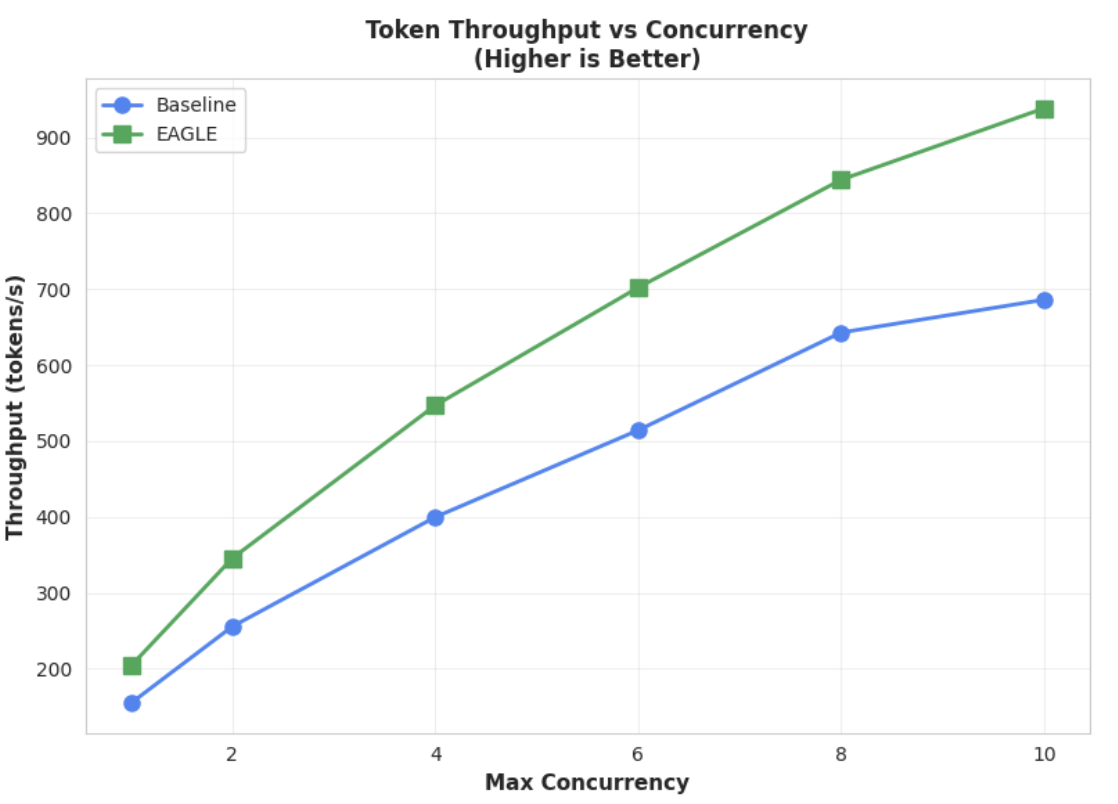
이 차트는 EAGLE-3의 처리량 이점을 더욱 명확하게 보여줍니다. 토큰 처리량 대 동시 실행 차트를 보면 EAGLE-3 가속 모델(녹색 선)이 기준 모델(파란색 선)보다 일관되게 그리고 상당히 우수한 성능을 보이는 것을 알 수 있습니다.
더 큰 모델에서도 유사한 결과가 나타나지만, 다른 성능 측정항목에 비해 첫 번째 토큰을 생성하는 시간(TTFT)이 증가할 수 있다는 점에 유의해야 합니다. 또한 이러한 성능은 다음 예시에서 볼 수 있듯이 태스크에 따라 달라집니다.
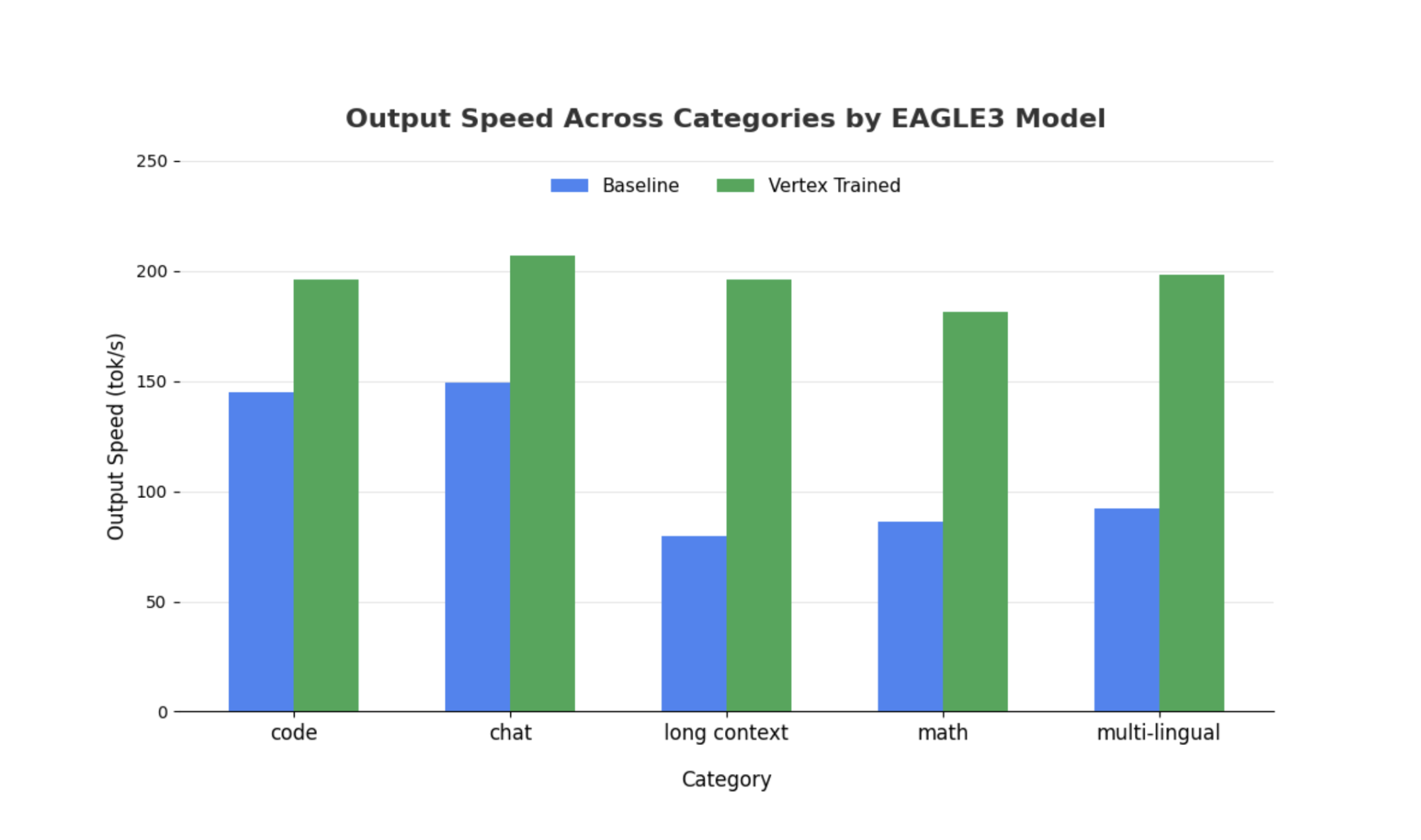
결론: 이제 여러분의 차례입니다
EAGLE-3는 단순한 연구 개념이 아니라, 디코딩 지연 시간을 2배까지 단축할 수 있고 프로덕션에 즉시 사용 가능한 패턴입니다. 하지만 이를 확장하려면 상당한 엔지니어링이 필요합니다. 사용자를 위해 이 기술을 안정적으로 배포하려면 다음 단계를 수행해야 합니다.
- 규정을 준수하는 합성 데이터 파이프라인 빌드
- 채팅 템플릿과 손실 마스크를 올바르게 처리하고 대규모 데이터 세트를 기반으로 모델 학습
Vertex AI에서는 LLM 기반 애플리케이션의 확장성을 고려하여 최적화된 컨테이너와 인프라를 제공하여 이 모든 프로세스를 이미 간소화했습니다. 시작하려면 다음 리소스를 확인하세요.
읽어 주셔서 감사합니다.
Vertex AI에 대한 의견이나 질문이 있으면 언제든지 알려주시기 바랍니다.
감사의 말씀
본 프로젝트 전반에 걸쳐 아낌없는 지원을 해주신 SGLang 팀(특히 Ying Sheng, Lianmin Zheng, Yineng Zhang, Xinyuan Tong, Liangsheng Yin)과 SGLang/SpecForge 팀(특히 Shenggui Li, Yikai Zhu)에게 진심으로 감사드립니다. 이분들의 아낌없는 도움과 심층적인 기술 인사이트는 본 프로젝트의 성공에 매우 중요한 역할을 했습니다.