

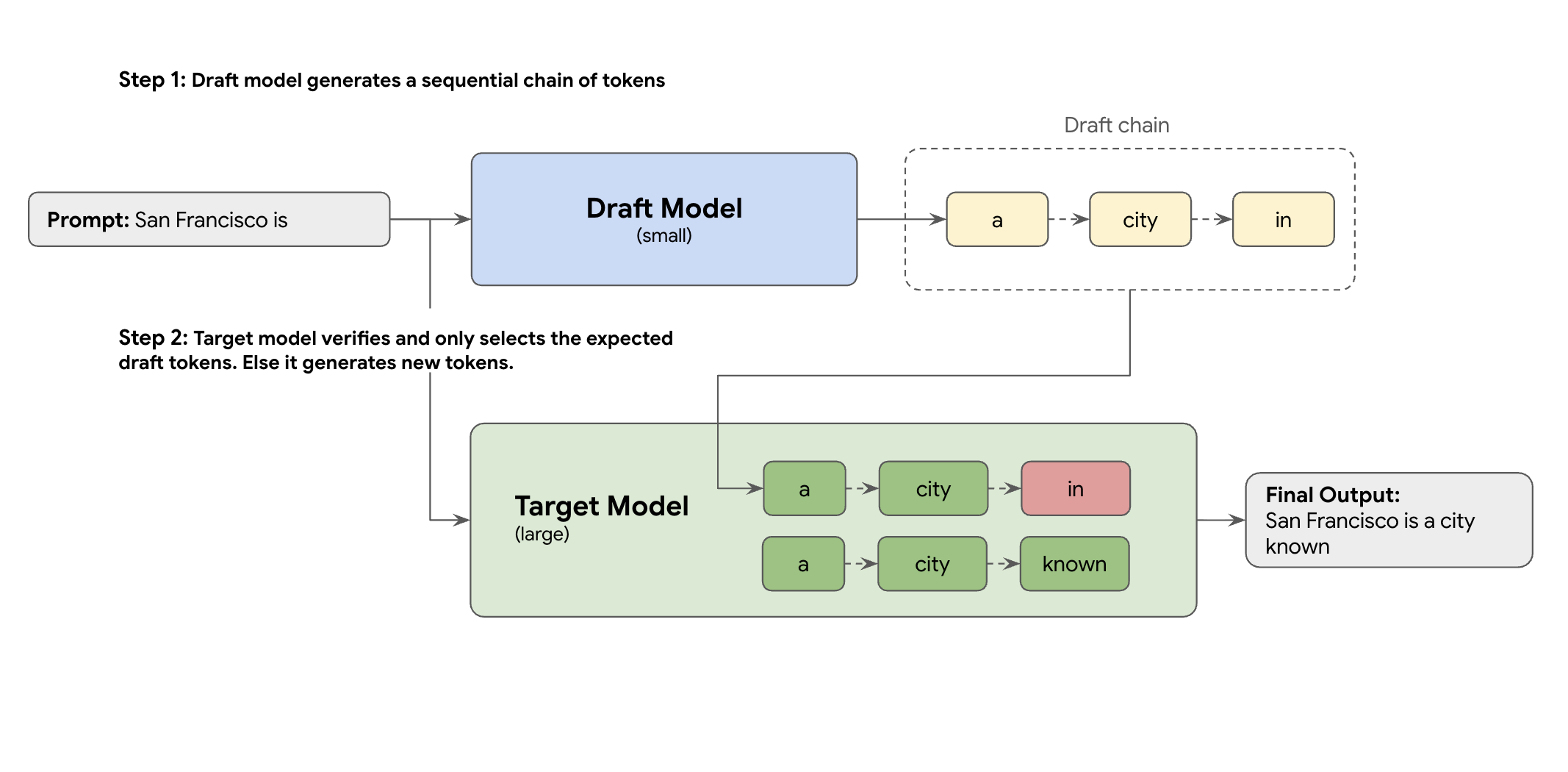
この問題を解決するのが、投機的デコーディングです。この最適化手法では、ドラフト メカニズムを導入することで、大規模な LLM(ターゲット モデル)が一度に 1 つのトークンを生成する速度の遅いシーケンシャル プロセスを高速化します。
このドラフト メカニズムは、次の複数のトークンを一度に迅速に提案します。大規模なターゲット モデルがこれらの提案を単一の並列バッチで検証します。独自の予測から最長一致プレフィックスを受け入れ、その新しいポイントから生成を続行します。
ただし、すべてのドラフト メカニズムが同じように作成されるわけではありません。従来のドラフト ターゲット アプローチでは、ドラフト作成者として別の小さな LLM モデルを使用します。つまり、より多くのサービング リソースをホストして管理する必要があるため、追加の費用が発生します。
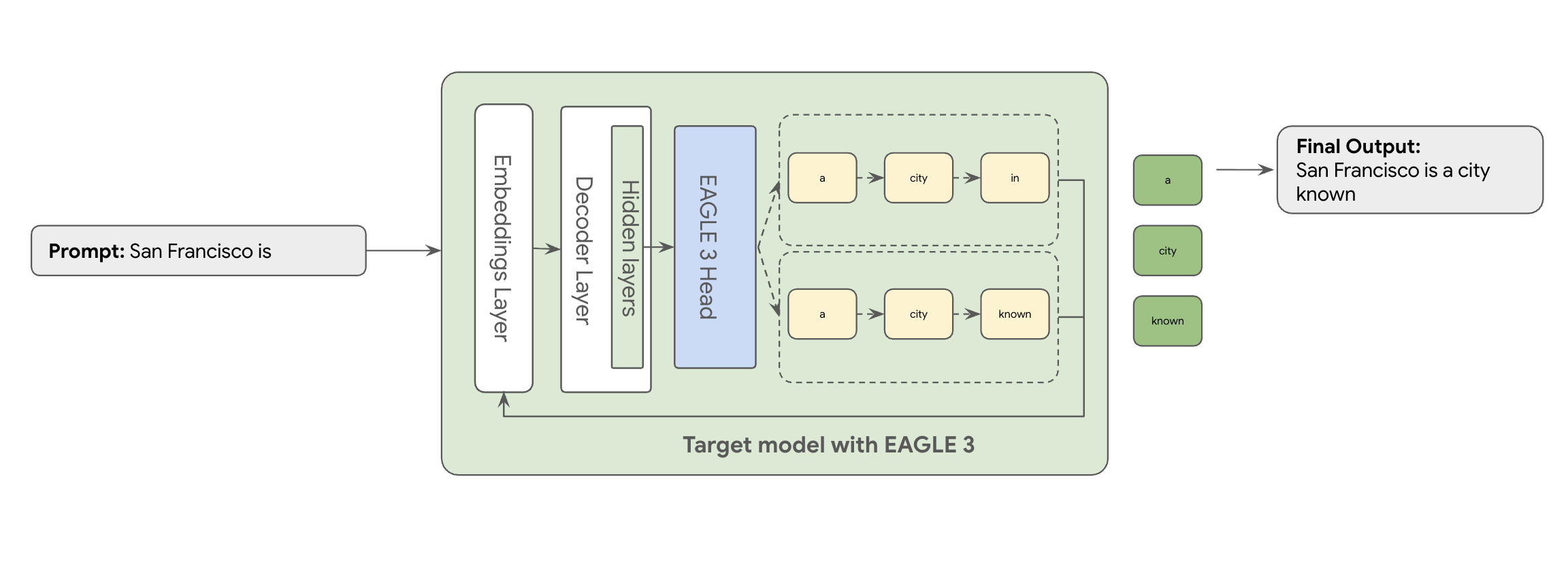
ここで EAGLE-3(Extrapolative Attention Guided LEarning)が登場します。EAGLE-3 はより高度なアプローチです。別のモデル全体ではなく、非常に軽量なドラフトヘッド(ターゲット モデルのサイズの 2~5%)を内部レイヤに直接接続します。このヘッドは特徴レベルとトークンレベルの両方で動作し、ターゲット モデルの隠れ状態から特徴を取り込み、将来のトークンのツリーを外挿して予測します。
その結果、2 つ目のモデルのトレーニングと実行のオーバーヘッドを排除しながら、投機的デコーディングのすべてのメリットを実現します。
EAGLE-3 のアプローチは、数十億ものパラメータを持つ別のドラフトモデルをトレーニングして維持するという複雑でリソースを大量に消費するタスクよりもはるかに効率的です。既存のモデルの一部として追加される軽量のドラフトヘッド(ターゲット モデルサイズの 2~5%)のみをトレーニングします。このよりシンプルで効率的なトレーニング プロセスにより、Llama 70B などのモデルでデコード パフォーマンスが 2~3 倍向上します(マルチターン、コード、長いコンテキストなどのワークロード タイプによって異なります)。
しかし、この合理化された EAGLE-3 アプローチを論文レベルからスケーリングされたプロダクション レディなクラウド サービスに移行するには、エンジニアリング上の大きな課題があります。この投稿では、Google の技術パイプライン、主な課題、そしてその過程で得られた貴重な教訓を紹介します。
課題 1: データの準備
EAGLE-3 ヘッドをトレーニングする必要があります。まず、一般的な公開データセットを取得します。これらのデータセットのほとんどには、次のような課題があります。
- 厳格な利用規約: これらのデータセットは、元のプロバイダと競合するモデルの開発に使用できないモデルを使用して生成されます。
- PII の汚染: これらのデータセットの一部には、名前、場所、財務識別子など、重要な PII が含まれています。
- 品質保証なし: 一部のデータセットは、一般的なデモのユースケースではうまく機能しますが、実際の顧客の特殊なワークロードでは最適に機能しません。
このデータをそのまま使用することはできません。
教訓 1: 合成データ生成パイプラインを構築する
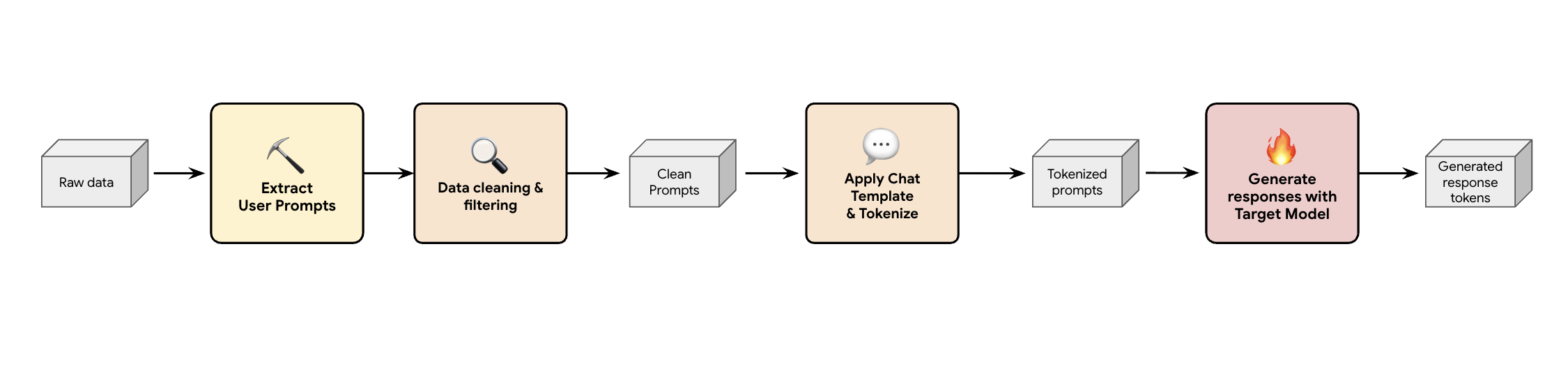
解決策の 1 つは、合成データ生成パイプラインを構築することです。お客様のユースケースに応じて、品質だけでなく、さまざまなワークロードに対してお客様の本番環境トラフィックに最も適したデータセットを選択します。次に、これらのデータセットからユーザー プロンプトのみを抽出し、厳格な DLP(データ損失防止)と PII フィルタリングを適用できます。これらのクリーンなプロンプトは、チャット テンプレートを適用してトークン化し、ターゲット モデル(Llama 3.3 70B)を使用してレスポンスを収集します。
このアプローチでは、準拠性とクリーンさを備えているだけでなく、モデルの実際の出力分布にうまく一致するターゲット生成データが提供されます。これは、ドラフトヘッドのトレーニングに最適です。
課題 2: トレーニング パイプラインのエンジニアリング
もう 1 つの重要な決定は、EAGLE-3 ヘッドにトレーニング データを供給する方法です。2 つの異なるパスがあります。エンベディングが「オンザフライで生成」されるオンライン トレーニングと、エンベディングが「トレーニング前に生成」されるオフライン トレーニングです。
今回のケースでは、オンライン トレーニングよりも必要なハードウェアがはるかに少ないため、オフライン トレーニング アプローチを選択しました。このプロセスでは、EAGLE-3 ヘッドをトレーニングする前に、すべての特徴とエンベディングを事前に計算します。これらは GCS に保存され、軽量の EAGLE-3 ヘッドのトレーニング データになります。データが揃えば、トレーニング自体は高速です。EAGLE-3 ヘッドはサイズが小さいため、元のデータセットを使用した初期トレーニングには、単一のホストで約 1 日かかりました。ただし、データセットをスケーリングするにつれて、トレーニング時間も増加し、現在では数日間に及んでいます。

このプロセスから、無視できない 2 つの教訓が得られました。
教訓 2: チャット テンプレートは必須
指示チューニング モデルのトレーニング中に、チャット テンプレートが正しくないと EAGLE-3 のパフォーマンスが大きく変動することがわかりました。ターゲット モデルの特定のチャット テンプレートLlama 3)を特徴とエンベディングを生成する前に、生のテキストを連結するだけでは、エンベディングが正しくなくなり、ヘッドが間違った分布を予測するように学習します。
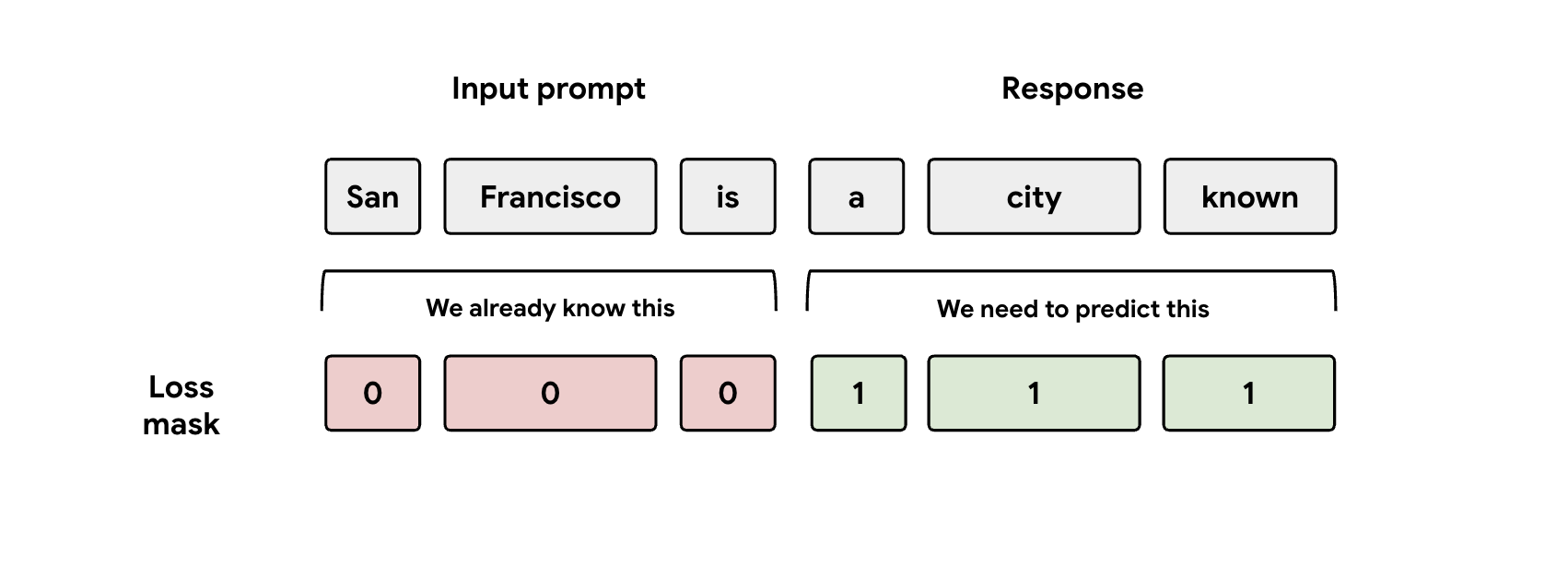
教訓 3: マスクに注意
トレーニング中、モデルにはプロンプトとレスポンスの両方の表現が入力されます。ただし、EAGLE-3 ヘッドはレスポンス表現の予測のみを学習する必要があります。損失関数でプロンプト部分を手動でマスクする必要があります。そうしないと、ヘッドはすでに与えられたプロンプトを予測するための学習に容量を浪費し、パフォーマンスが低下します。
課題 3: サービングとスケーリング
トレーニング済みの EAGLE-3 ヘッドを使用して、サービングフェーズに進みました。このフェーズでは、スケーリングに関する大きな課題が見つかりました。主な教訓は次のとおりです。
教訓 4: サービング フレームワークが重要
SGLang チームと緊密に連携することで、EAGLE-3 を最高のパフォーマンスで本番環境に導入することに成功しました。技術的な理由は、SGLang が重要なツリー アテンション カーネルを実装しているためです。この特別なカーネルは、EAGLE-3 が可能性の「ドラフトツリー」(単なる単純なチェーンではない)を生成するため、非常に重要です。SGLang のカーネルは、これらの分岐パスをすべて 1 つのステップで並行して検証するように特別に設計されています。これがないと、パフォーマンスを最大限に引き出すことができません。
教訓 5: CPU が GPU のボトルネックにならないようにする
EAGLE-3 で LLM を高速化した後でも、別のパフォーマンスの壁に直面する可能性があります。それは CPU です。GPU で LLM 推論を実行する場合、最適化されていないソフトウェアは、カーネルの起動やメタデータの管理などの CPU オーバーヘッドに膨大な時間を費やします。通常の同期スケジューラでは、GPU がステップ(ドラフトなど)を実行し、CPU が予約処理を行い、次の検証ステップを開始する間、アイドル状態になります。これらの同期が積み重なり、貴重な GPU 時間が大量に無駄になります。

この問題は、SGLang の Zero-Overhead Overlap Scheduler を使用することで解決しました。このスケジューラは、投機的デコーディングのマルチステップの「ドラフト -> 検証 -> ドラフト拡張」ワークフロー用に特別に調整されています。重要な点は、計算をオーバーラップさせることです。GPU が現在の検証ステップの実行でビジー状態になっている間、CPU はすでに並行して動作し、次のドラフト ステップとドラフト拡張ステップのカーネルを起動しています。これは、GPU の次のジョブが常に準備されていることを保証することで、アイドルバブルを排除します。FutureMap は、GPU がまだ動作している間に CPU が次のバッチを準備できるスマートなデータ構造です。

この CPU オーバーヘッドを排除することで、オーバーラップ スケジューラは全体で 10~20% の高速化を実現します。これは、優れたモデルだけでは不十分であり、それに追いつくことができるランタイムが必要であることを証明しています。
ベンチマークの結果
この過程は十分な価値があったのでしょうか。もちろんあります。
トレーニング済みの EAGLE-3 ヘッドを、Llama 4 Scout 17B Instruct を使用した SGLang で非投機的ベースラインと比較しました。わたしたちのベンチマークでは、ワークロードのタイプに応じて、デコード レイテンシが 2~3 倍高速化し、スループットが大幅に向上しています。
包括的なノートブックを使用して、詳細を確認し、ご自身でベンチマークを実施してください。
指標 1: 出力トークンあたりの時間(TPOT)の中央値
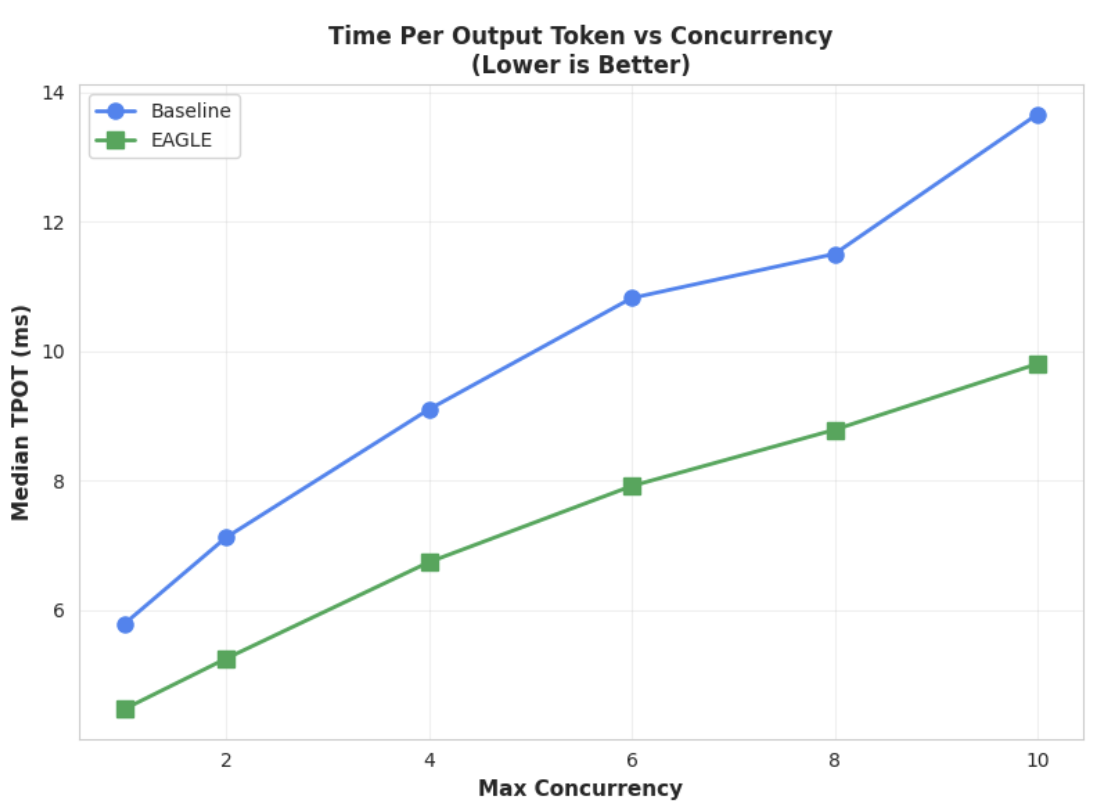
このグラフは、EAGLE-3 のレイテンシ パフォーマンスが優れていることを示しています。出力トークンあたりの時間(TPOT)グラフは、テストされたすべての同時実行レベルで、EAGLE-3 アクセラレータ モデル(緑色の線)がベースライン(青色の線)よりも常に低いレイテンシを実現していることを示しています。
指標 2: 出力スループット
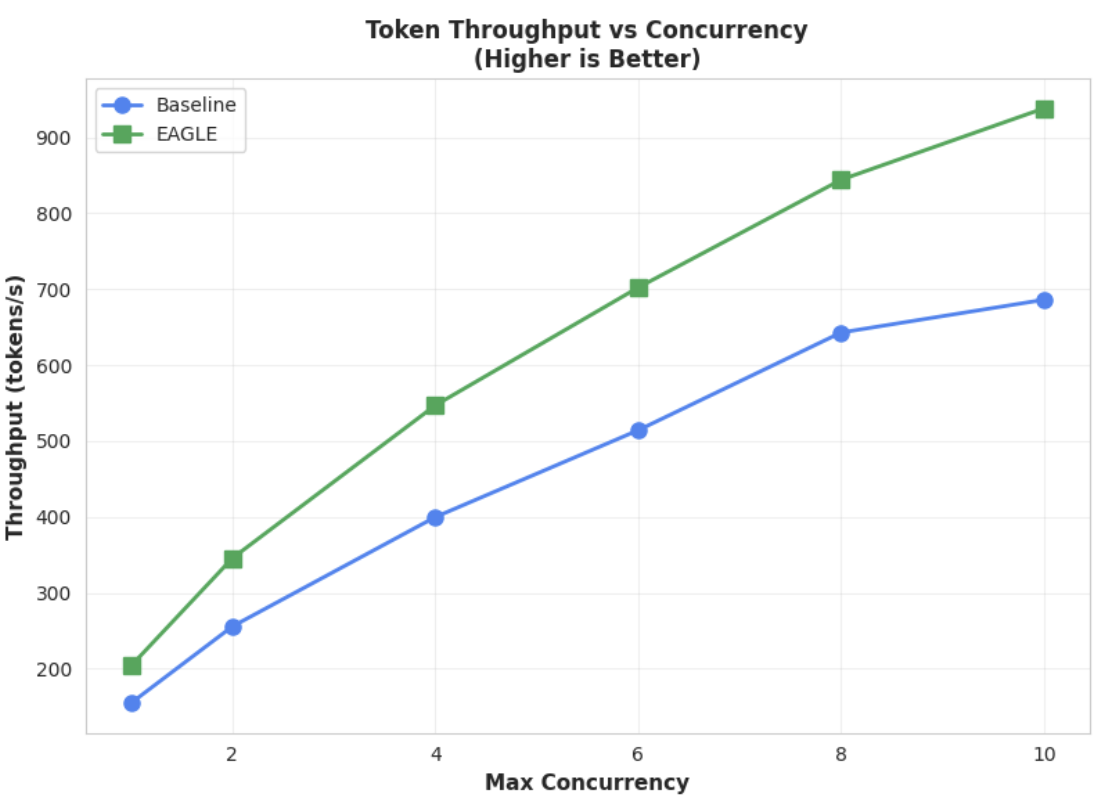
このグラフは、EAGLE-3 のスループットの優位性をさらに示しています。トークン スループットと同時実行数のグラフを見ると、EAGLE-3 アクセラレータ モデル(緑色の線)がベースライン モデル(青色の線)を常に大幅に上回っていることがわかります。
同様の観察結果は大規模なモデルにも当てはまりますが、他のパフォーマンス指標と比較して、最初のトークンまでの時間(TTFT)の増加が見られる可能性があることに注意してください。また、次の例に示すように、これらのパフォーマンスはタスクによって異なります。
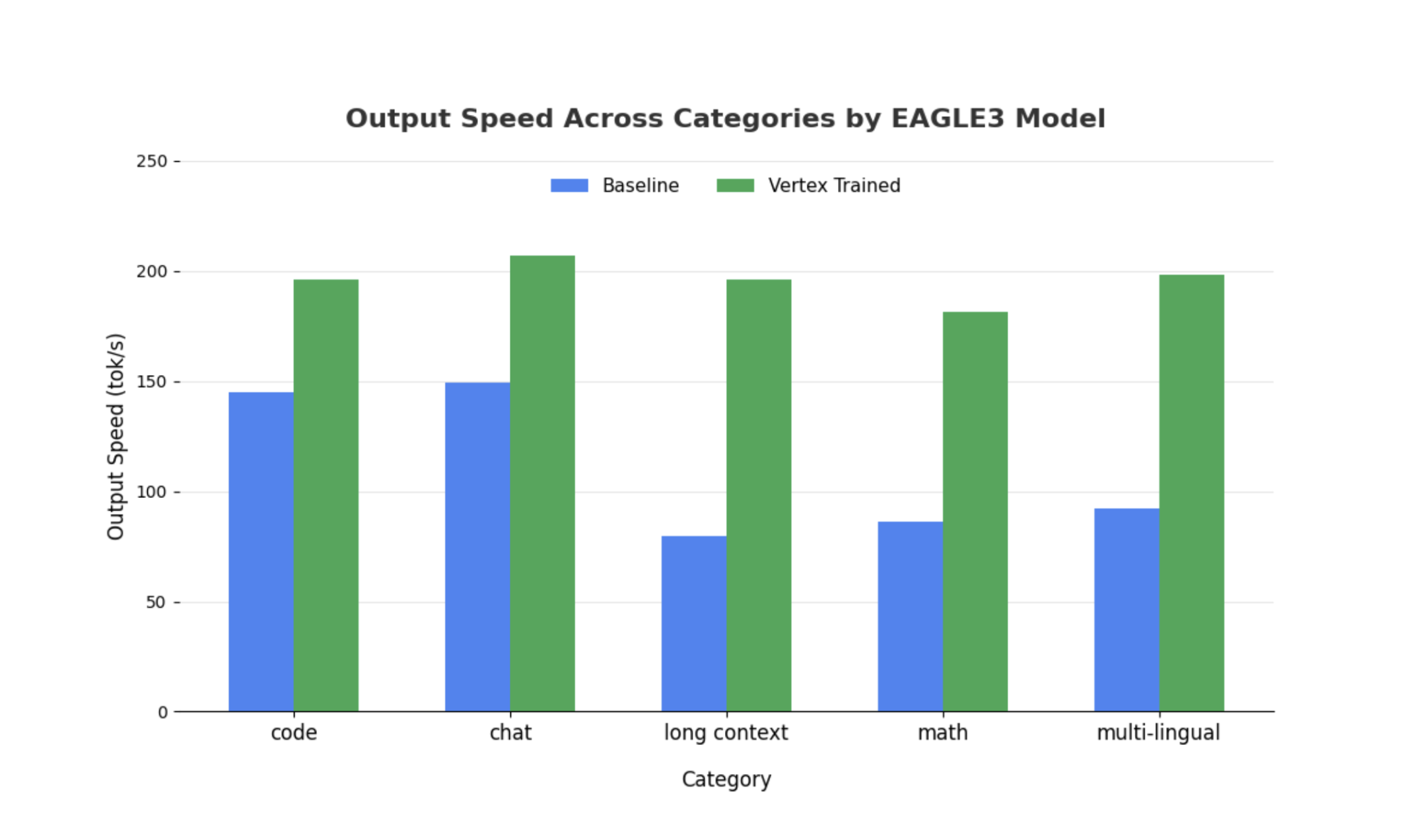
まとめ: 次は実践です
EAGLE-3 は単なる研究コンセプトではなく、デコード レイテンシを 2 倍に短縮できるプロダクション レディなパターンです。ただし、スケーリングを実現するには、エンジニアリングの努力が不可欠です。このテクノロジーをユーザーに確実にデプロイするには、次のことを行う必要があります。
- コンプライアンスに準拠した合成データ パイプラインを構築します。
- チャット テンプレートと損失マスクを正しく処理し、大規模なデータセットでモデルをトレーニングします。
Vertex AI では、このプロセス全体がすでに合理化されており、LLM ベースのアプリケーションをスケーリングするように設計され、最適化されたコンテナとインフラストラクチャが提供されています。実際にやってみるには、以下のリソースをご覧ください。
最後までお読みいただきありがとうございました
Vertex AI に関するご意見やご質問をお待ちしております。
謝辞
本プロジェクトを通じて貴重なサポートを提供してくれた SGLang チーム(Ying Sheng、Lianmin Zheng、Yineng Zhang、Xinyuan Tong、Liangsheng Yin)と SGLang/SpecForge チーム(Shenggui Li、Yikai Zhu)に心から感謝いたします。これらのチームの寛大な支援と深い技術的洞察は、このプロジェクトの成功に不可欠でした。