

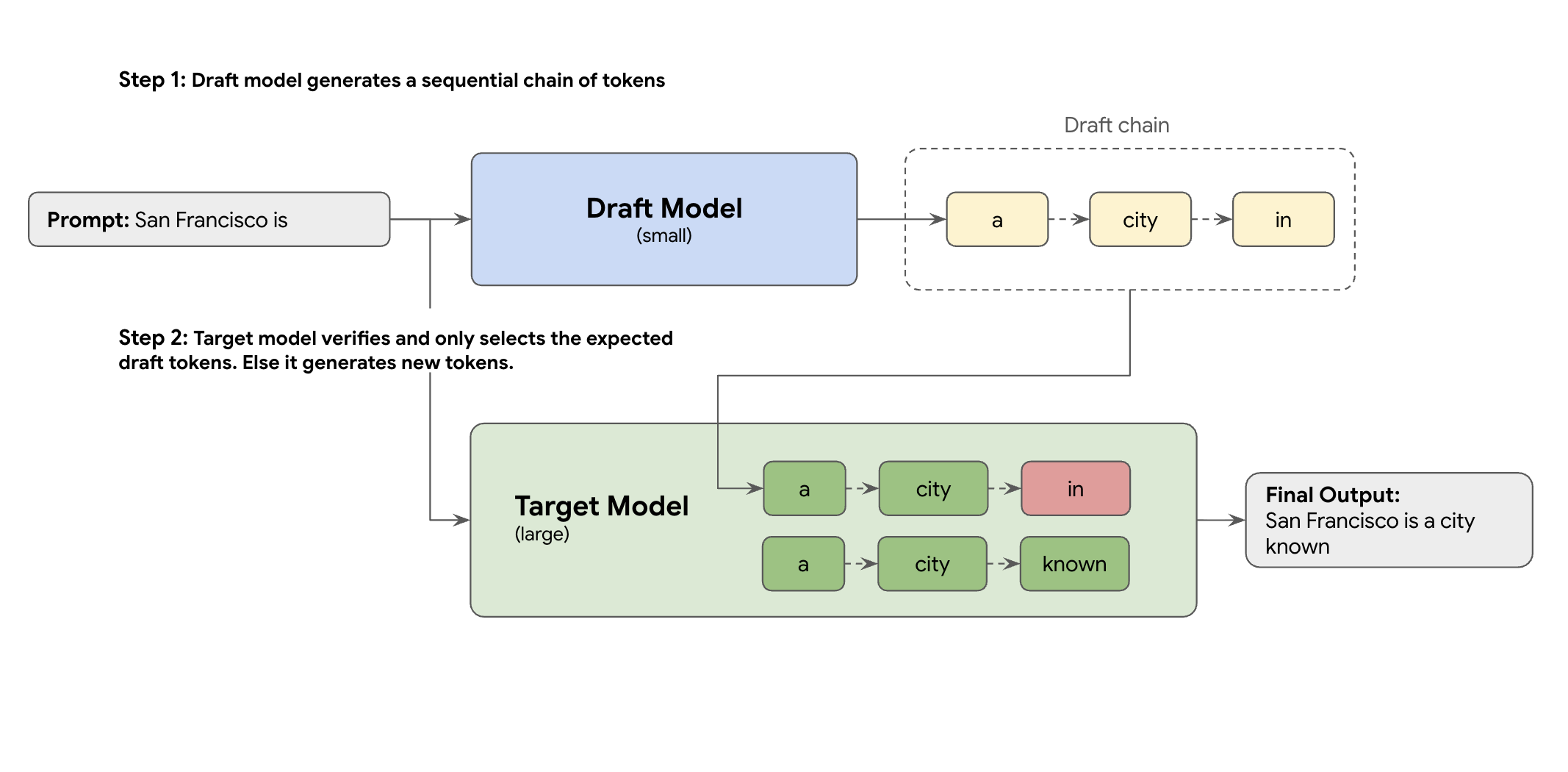
La soluzione è la decodifica speculativa. Questa tecnica di ottimizzazione accelera il processo lento e sequenziale di generazione di un token alla volta del tuo LLM di grandi dimensioni (il modello di destinazione) introducendo un meccanismo di bozza.
Questo meccanismo di bozza propone rapidamente diversi token successivi contemporaneamente. Il modello di targeting di grandi dimensioni verifica quindi queste proposte in un unico batch parallelo. Accetta il prefisso di corrispondenza più lungo dalle proprie previsioni e continua la generazione da quel nuovo punto.
Tuttavia, non tutti i meccanismi di bozza sono uguali. L'approccio classico di bozza-target utilizza un modello LLM separato e più piccolo come bozza, il che significa che devi ospitare e gestire più risorse di pubblicazione, causando costi aggiuntivi.
Fai clic per ingrandire l'immagine
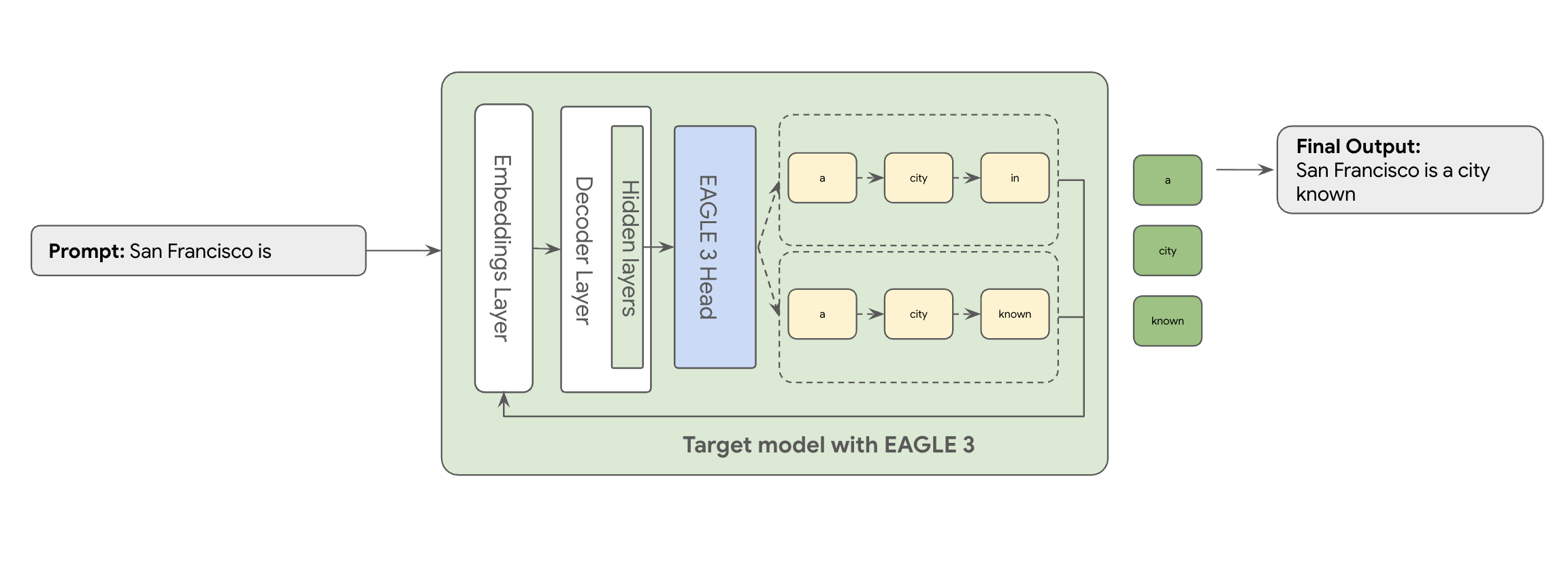
È qui che entra in gioco EAGLE-3 (Extrapolative Attention Guided LEarning). EAGLE-3 è un approccio più avanzato. Anziché un modello completamente separato, collega una "testa" di bozza estremamente leggera, pari solo al 2-5% delle dimensioni del modello di destinazione, direttamente ai suoi livelli interni. Questa testa opera sia a livello di funzionalità che di token, acquisendo le funzionalità dagli stati nascosti del modello di destinazione per estrapolare e prevedere un albero di token futuri.
Il risultato? Tutti i vantaggi della decodifica speculativa, eliminando il sovraccarico di addestramento ed esecuzione di un secondo modello.
L'approccio di EAGLE-3 è molto più efficiente rispetto alla complessa attività di addestramento e manutenzione di un modello di bozza separato con miliardi di parametri, che richiede molte risorse. Viene addestrato solo un "draft head" leggero, ovvero solo il 2-5% delle dimensioni del modello di destinazione, che viene aggiunto come parte del modello esistente. Questo processo di addestramento più semplice ed efficiente offre un aumento significativo delle prestazioni di decodifica di 2-3 volte per modelli come Llama 70B (a seconda dei tipi di carichi di lavoro, ad esempio multi-turn, codice, contesto lungo e altro ancora).
Fai clic per ingrandire l'immagine
Ma il passaggio di questo approccio EAGLE-3 semplificato da un documento a un servizio cloud scalabile e pronto per la produzione è un vero e proprio percorso ingegneristico. Questo post condivide la nostra pipeline tecnica, le sfide principali e le lezioni apprese lungo il percorso.
Sfida n. 1: preparazione dei dati
La testa EAGLE-3 deve essere addestrata. Il primo passaggio ovvio è recuperare un set di dati generico disponibile pubblicamente. La maggior parte di questi set di dati presenta sfide, tra cui:
- Termini di servizio rigorosi:questi set di dati vengono generati utilizzando modelli che non consentono di utilizzarli per sviluppare modelli che competano con i fornitori originali.
- Contaminazione di PII:alcuni di questi set di dati contengono PII significative, tra cui nomi, località e persino identificatori finanziari.
- Nessuna garanzia di qualità: alcuni set di dati funzionano alla perfezione solo per casi d'uso"demo" generali, ma non per il carico di lavoro specializzato dei clienti reali.
L'utilizzo di questi dati così come sono non è un'opzione.
Lezione 1: crea una pipeline di generazione di dati sintetici
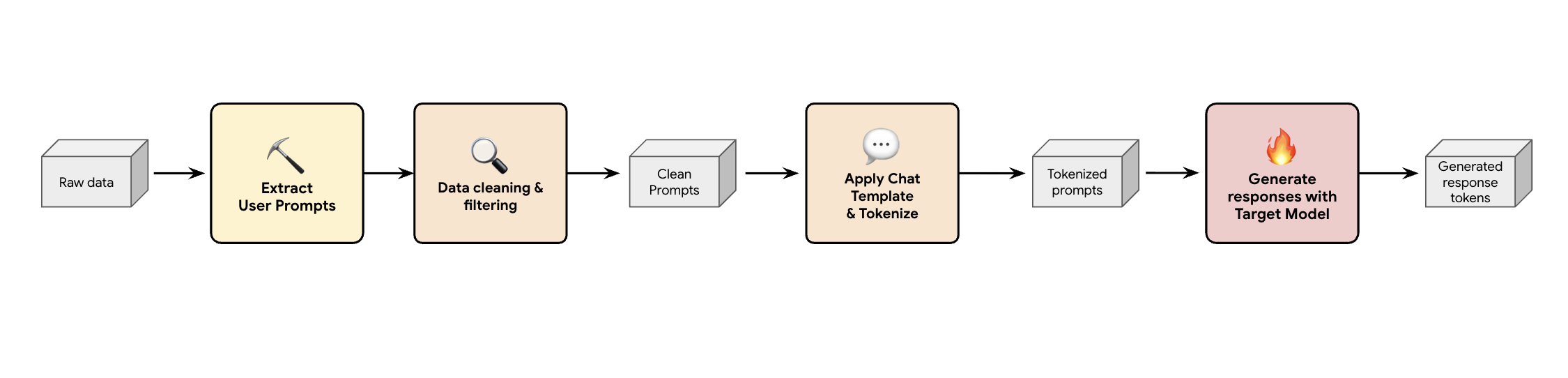
Una soluzione consiste nel creare una pipeline di generazione di dati sintetici. A seconda dei casi d'uso dei nostri clienti, selezioniamo il set di dati giusto non solo con una buona qualità, ma anche quello che corrisponde meglio al traffico di produzione dei nostri clienti per vari carichi di lavoro diversi. Successivamente, puoi estrarre solo i prompt utente da questi set di dati e applicare filtri rigorosi per la prevenzione della perdita di dati (DLP) e delle informazioni di identificazione personale (PII). Questi prompt puliti applicano un modello di chat, li tokenizzano e poi possono essere inseriti nel modello di destinazione (ad es. Llama 3.3 70B) per raccogliere le sue risposte.
Questo approccio fornisce dati generati dal target che non sono solo conformi e puliti, ma anche ben abbinati alla distribuzione effettiva dell'output del modello. Questa opzione è ideale per l'addestramento della bozza di titolo.
Fai clic per ingrandire l'immagine
Sfida n. 2: progettazione della pipeline di addestramento
Un'altra decisione fondamentale è come fornire i dati di addestramento all'intestazione EAGLE-3. Hai due percorsi distinti: addestramento online, in cui gli incorporamenti vengono "generati al volo", e addestramento offline, in cui gli incorporamenti vengono generati prima dell'addestramento.
Nel nostro caso, abbiamo scelto un approccio di addestramento offline perché richiede molte meno risorse hardware rispetto all'addestramento online. Questo processo prevede il pre-calcolo di tutte le funzionalità e gli incorporamenti prima di addestrare l'intestazione EAGLE-3. Li salviamo in GCS e diventano i dati di addestramento per la nostra intestazione EAGLE-3 leggera. Una volta ottenuti i dati, l'addestramento è rapido. Date le dimensioni ridotte della testa EAGLE-3, l'addestramento iniziale con il nostro set di dati originale ha richiesto circa un giorno su un singolo host. Tuttavia, man mano che abbiamo scalato il nostro set di dati, i tempi di addestramento sono aumentati proporzionalmente, ora si estendono per diversi giorni.

Fai clic per ingrandire l'immagine
Questo processo ci ha insegnato due lezioni non trascurabili che devi tenere a mente.
Lezione 2: i modelli di chat non sono facoltativi
Durante l'addestramento del modello ottimizzato per le istruzioni, abbiamo scoperto che le prestazioni di EAGLE-3 possono variare molto se il modello di chat non è corretto. Devi applicare il modello di chat specifico del modello di destinazione (ad es. Llama 3) prima di generare le funzionalità e gli incorporamenti. Se concateni semplicemente il testo non elaborato, gli incorporamenti saranno errati e l'intestazione imparerà a prevedere la distribuzione errata.
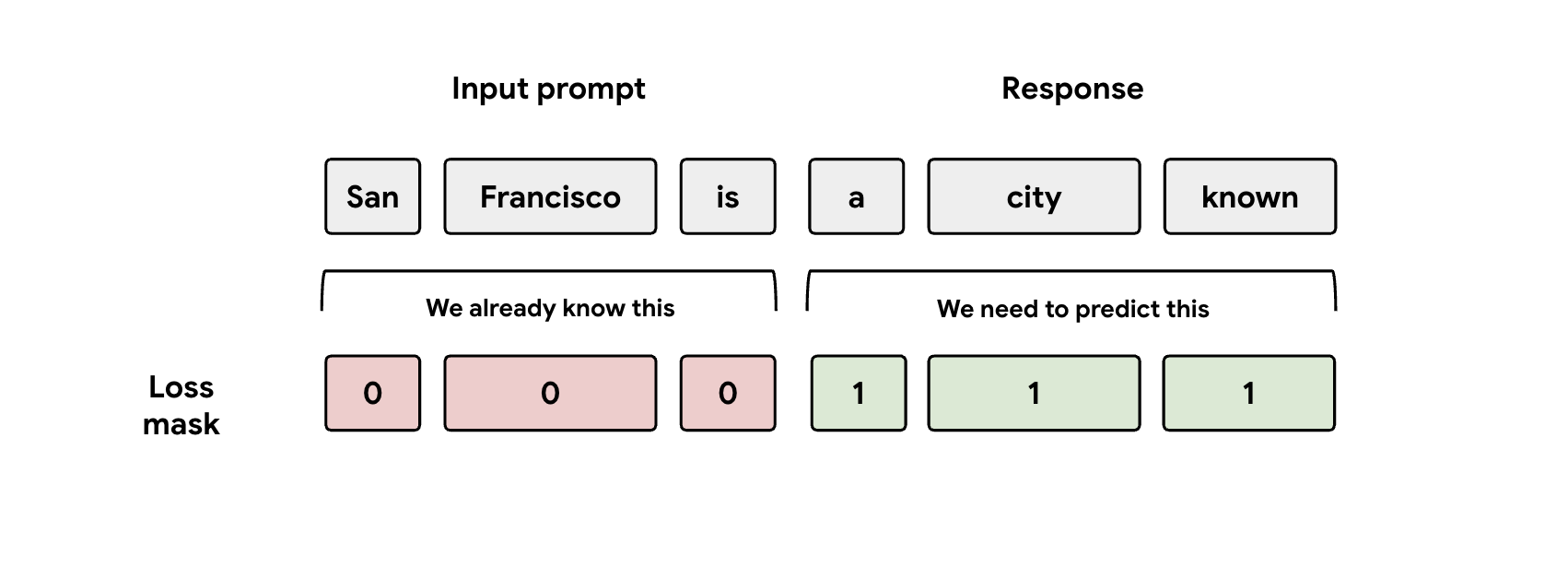
Lezione 3: attenzione alla maschera
Durante l'addestramento, al modello vengono fornite sia le rappresentazioni del prompt che quelle della risposta. Tuttavia, la testa EAGLE-3 deve imparare a prevedere solo la rappresentazione della risposta. Devi mascherare manualmente la parte del prompt nella funzione di perdita. Se non lo fai, l'intestazione spreca capacità per imparare a prevedere il prompt che le è già stato fornito e le prestazioni ne risentiranno.
Fai clic per ingrandire l'immagine
Sfida n. 3: pubblicazione e scalabilità
Con una testa EAGLE-3 addestrata, abbiamo proceduto alla fase di pubblicazione. Questa fase ha introdotto sfide di scalabilità significative. Ecco i principali insegnamenti.
Lezione 4: il framework di pubblicazione è fondamentale
Grazie alla stretta collaborazione con il team SGLang, abbiamo implementato con successo EAGLE-3 in produzione con le migliori prestazioni. Il motivo tecnico è che SGLang implementa un kernel di attenzione all'albero cruciale. Questo kernel speciale è fondamentale perché EAGLE-3 genera un "albero di bozza" di possibilità (non solo una semplice catena) e il kernel di SGLang è progettato specificamente per verificare tutti questi percorsi ramificati in parallelo in un unico passaggio. Senza questo, non stai sfruttando tutto il potenziale delle prestazioni.
Lezione 5: non lasciare che la CPU limiti la GPU
Anche dopo aver accelerato il tuo LLM con EAGLE-3, puoi incontrare un altro limite di rendimento: la CPU. Quando le GPU eseguono l'inferenza LLM, il software non ottimizzato spreca un'enorme quantità di tempo per l'overhead della CPU, ad esempio l'avvio del kernel e la gestione dei metadati. In un normale scheduler sincrono, la GPU esegue un passaggio (come Bozza), quindi rimane inattiva mentre la CPU esegue la contabilità e avvia il passaggio successivo Verifica. Queste bolle di sincronizzazione si sommano, sprecando enormi quantità di tempo della GPU.

Fai clic per ingrandire l'immagine
Abbiamo risolto il problema utilizzando lo Zero-Overhead Overlap Scheduler di SGLang. Questo
scheduler è ottimizzato in modo specifico per il flusso di lavoro multi-step Bozza ->
Verifica -> Estensione bozza della decodifica speculativa . La chiave è la sovrapposizione del calcolo. Mentre la GPU è impegnata nell'esecuzione del passaggio Verifica corrente, la CPU sta già lavorando in parallelo per avviare i kernel per i passaggi successivi Bozza ed Estensione bozza .
In questo modo si elimina la bolla di inattività, assicurandosi che il successivo job della GPU sia sempre pronto, utilizzando una FutureMap, una struttura di dati intelligente che consente alla CPU di preparare il batch successivo MENTRE la GPU è ancora in funzione.

Fai clic per ingrandire l'immagine
Eliminando questo sovraccarico della CPU, lo strumento di pianificazione della sovrapposizione ci offre un ulteriore aumento della velocità del 10-20% in tutti i casi. Dimostra che un ottimo modello è solo metà della battaglia: hai bisogno di un runtime che possa tenere il passo.
Risultati benchmark
Dopo questo percorso, ne è valsa la pena? Certo.
Abbiamo confrontato la nostra testa EAGLE-3 addestrata con la baseline non speculativa utilizzando SGLang con Llama 4 Scout 17B Instruct. I nostri benchmark mostrano un aumento della velocità di 2-3 volte nella latenza di decodifica e un aumento significativo del throughput a seconda dei tipi di carichi di lavoro.
Visualizza i dettagli completi ed esegui il benchmark autonomamente utilizzando il nostro notebook completo.
Metrica 1: tempo mediano per token di output (TPOT)
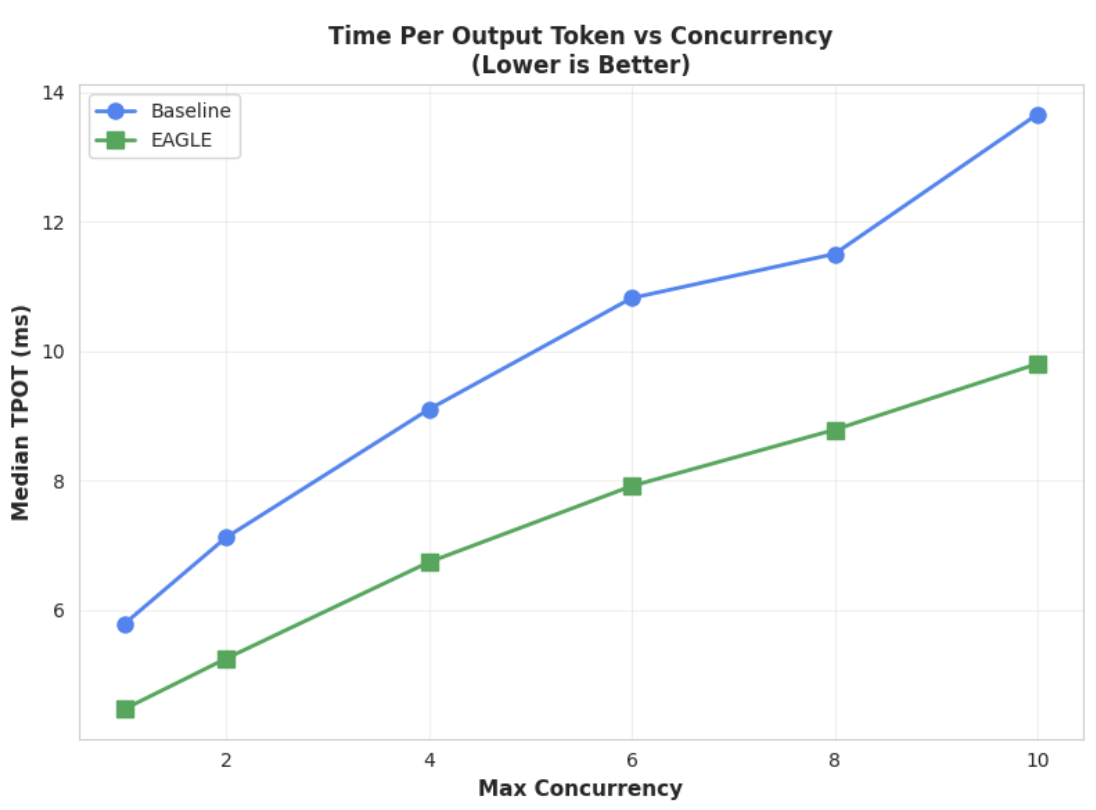
Fai clic per ingrandire l'immagine
Questo grafico mostra le migliori prestazioni di latenza di EAGLE-3. Il grafico Tempo per token di output (TPOT) mostra che il modello EAGLE-3 con accelerazione (linea verde) raggiunge costantemente una latenza inferiore (più veloce) rispetto alla baseline (linea blu) in tutti i livelli di concorrenza testati.
Metrica 2: throughput di output
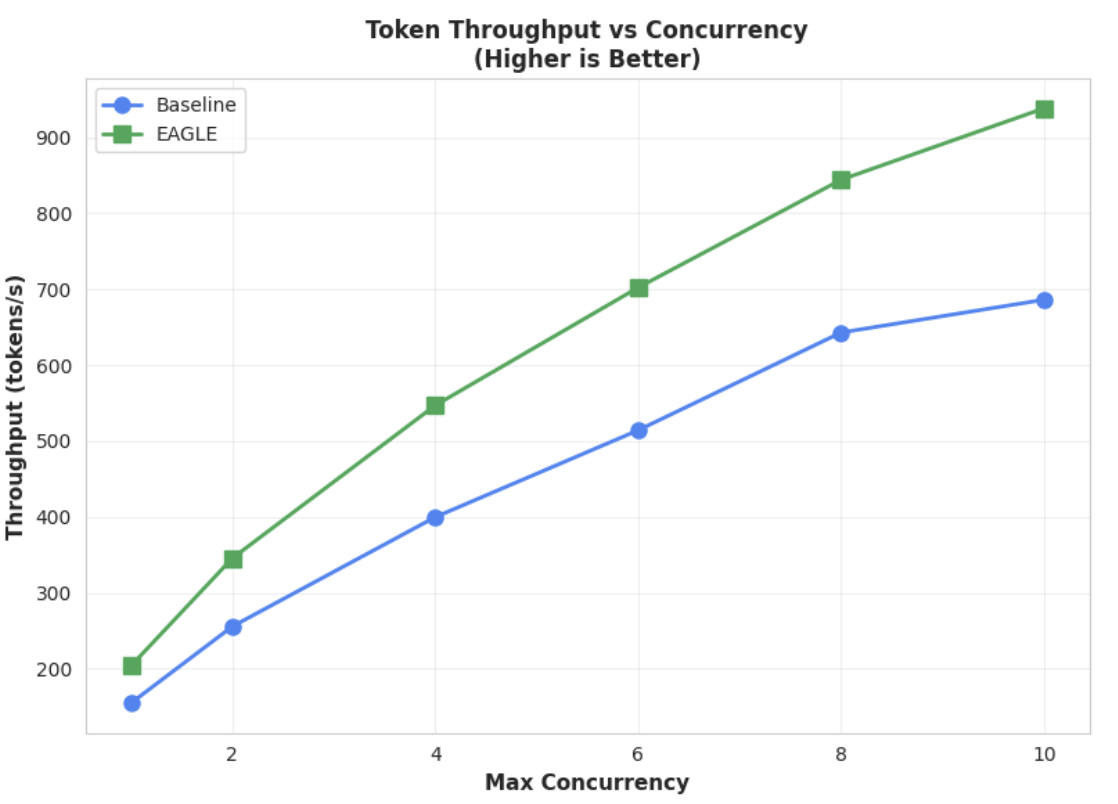
Fai clic per ingrandire l'immagine
Questo grafico evidenzia ulteriormente il vantaggio di EAGLE-3 in termini di throughput. Il grafico Throughput token vs. concorrenza dimostra chiaramente che il modello EAGLE-3 con accelerazione (linea verde) supera in modo costante e sostanziale il modello di base (linea blu).
Sebbene osservazioni simili valgano anche per i modelli più grandi, è importante notare che potrebbe essere osservato un aumento del tempo al primo token (TTFT) rispetto ad altre metriche di rendimento. Inoltre, queste prestazioni variano a seconda dell'attività, come illustrato dai seguenti esempi:
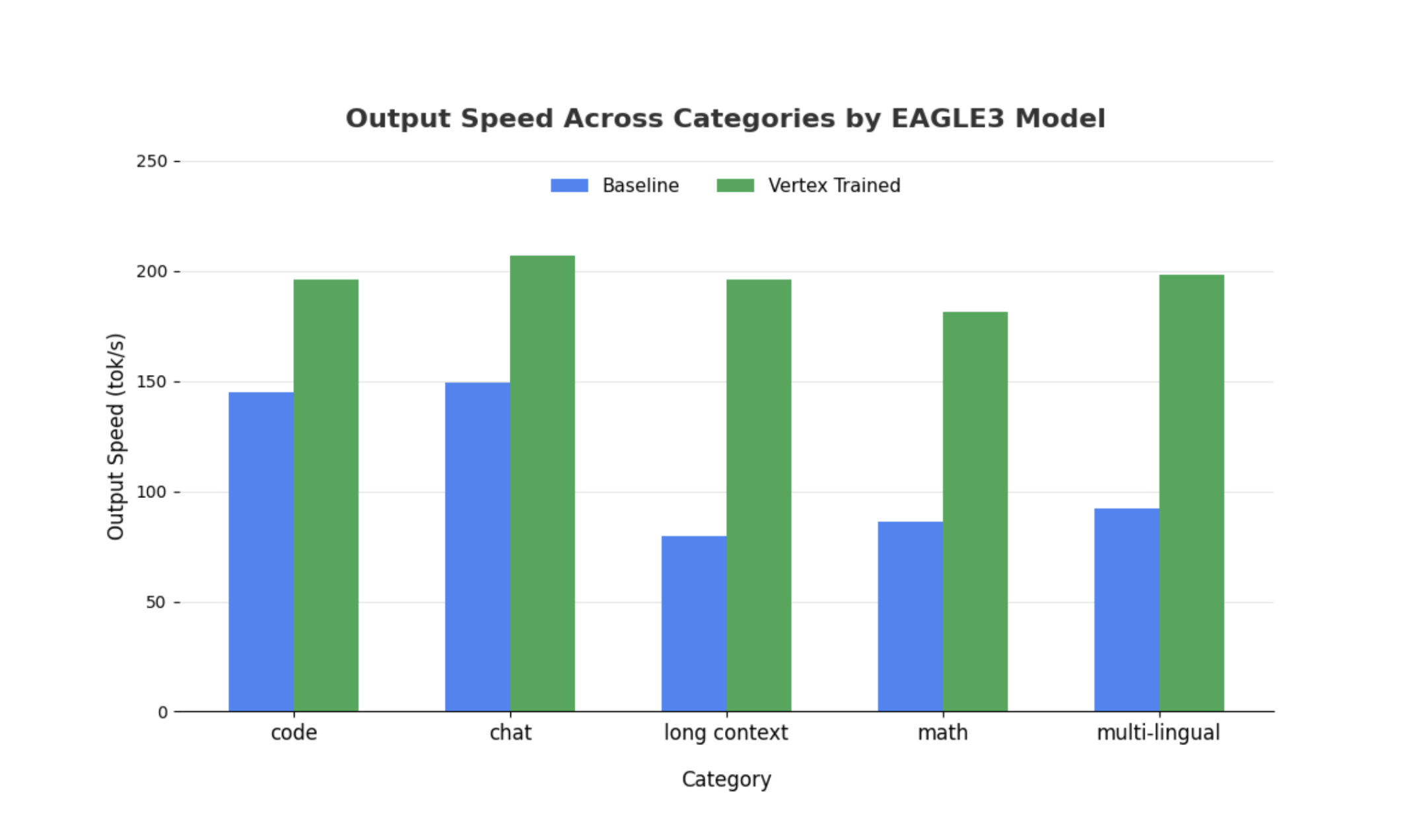
Fai clic per ingrandire l'immagine
Conclusione: ora tocca a te
EAGLE-3 non è solo un concetto di ricerca, ma un pattern pronto per la produzione che può offrire un aumento tangibile della velocità di decodifica di 2 volte. Ma per renderlo scalabile è necessario un vero e proprio sforzo ingegneristico. Per implementare in modo affidabile questa tecnologia per i tuoi utenti, devi:
- Crea una pipeline di dati sintetici conforme.
- Gestire correttamente i modelli di chat e le maschere di perdita e addestrare il modello su un set di dati di grandi dimensioni.
Su Vertex AI, abbiamo già semplificato l'intero processo per te, fornendo un container e un'infrastruttura ottimizzati progettati per scalare le tue applicazioni basate su LLM. Per iniziare, consulta le seguenti risorse:
Grazie per l'attenzione
Accogliamo con piacere il tuo feedback e le tue domande su Vertex AI.
Ringraziamenti
Vogliamo esprimere la nostra sincera gratitudine al team di SGLang, in particolare a Ying Sheng, Lianmin Zheng, Yineng Zhang, Xinyuan Tong, Liangsheng Yin, nonché al team di SGLang/SpecForge, in particolare a Shenggui Li e Yikai Zhu, per il loro prezioso supporto durante questo progetto. Il loro generoso aiuto e le loro approfondite conoscenze tecniche sono stati fondamentali per il successo di questo progetto.