

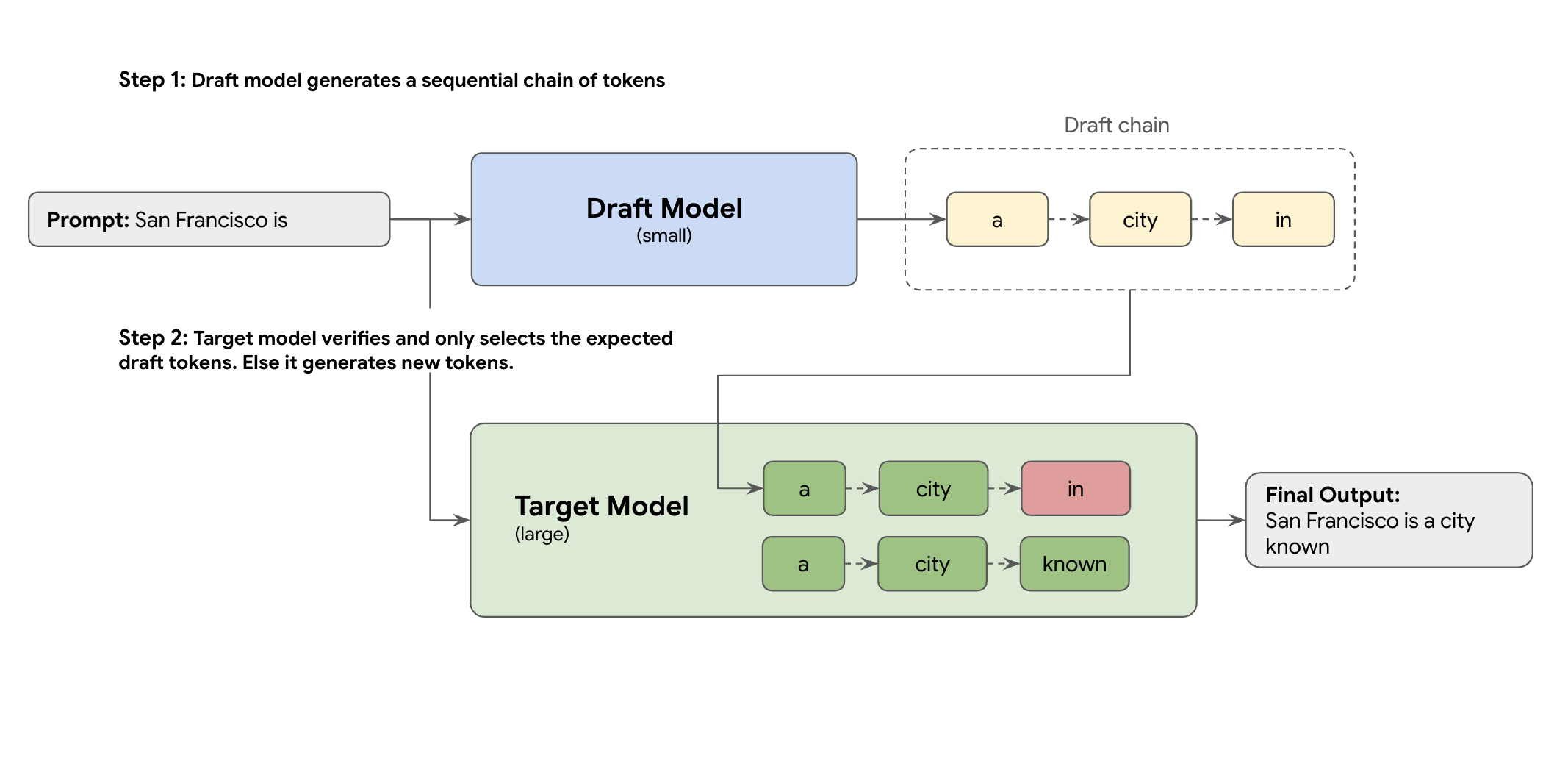
Solusinya adalah dekode spekulatif. Teknik pengoptimalan ini mempercepat proses berurutan yang lambat dari LLM besar Anda (model target) yang menghasilkan satu token dalam satu waktu, dengan memperkenalkan mekanisme draf.
Mekanisme draf ini dengan cepat menyarankan beberapa token berikutnya sekaligus. Model target besar kemudian memverifikasi proposal ini dalam satu batch paralel. Model ini menerima awalan yang cocok paling panjang dari prediksinya sendiri dan melanjutkan pembuatan dari titik baru tersebut.
Namun, tidak semua mekanisme draf sama. Pendekatan target draf klasik menggunakan model LLM terpisah yang lebih kecil sebagai pembuat draf, yang berarti Anda harus menghosting dan mengelola lebih banyak resource penayangan, sehingga menimbulkan biaya tambahan.
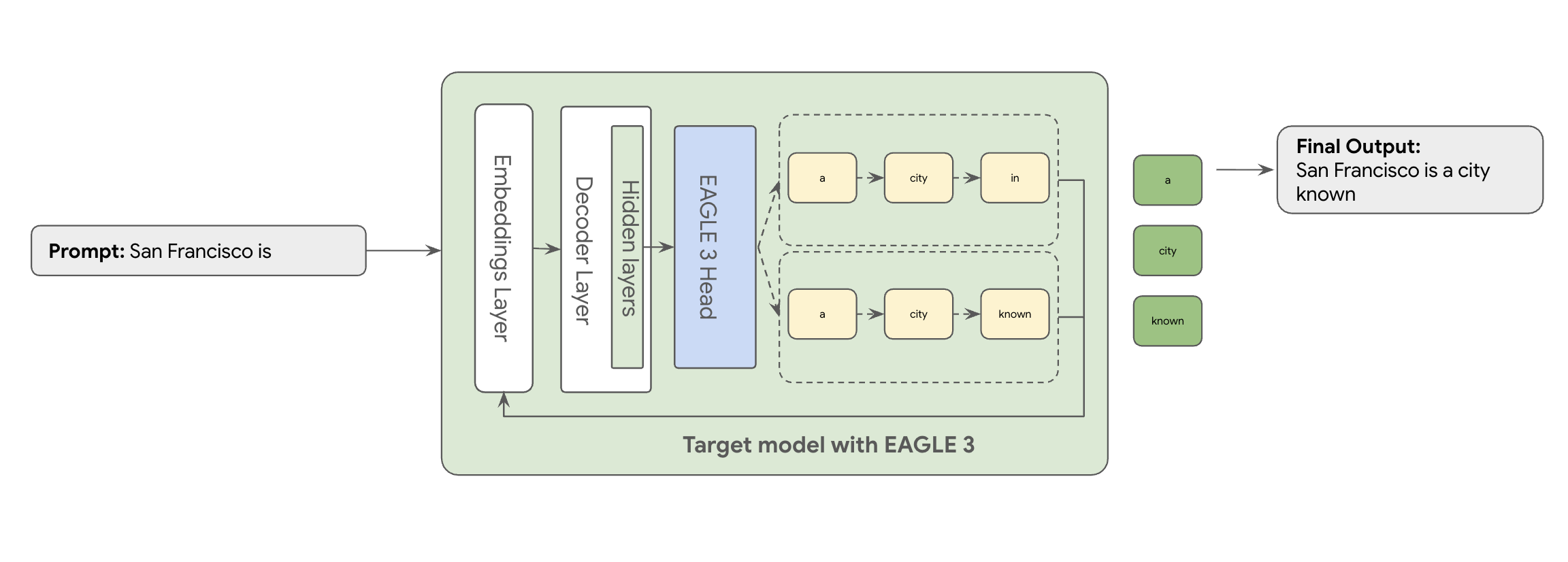
Di sinilah EAGLE-3 (Extrapolative Attention Guided LEarning) berperan. EAGLE-3 adalah pendekatan yang lebih canggih. Alih-alih menggunakan model yang benar-benar terpisah, model ini melampirkan 'draf head' yang sangat ringan—hanya 2-5% dari ukuran model target—langsung ke lapisan internalnya. Kepala ini beroperasi di tingkat fitur dan token, menyerap fitur dari status tersembunyi model target untuk mengekstrapolasi dan memprediksi pohon token mendatang.
Hasilnya? Semua manfaat decoding spekulatif sekaligus menghilangkan overhead pelatihan dan menjalankan model kedua.
Pendekatan EAGLE-3 jauh lebih efisien daripada tugas kompleks dan intensif resource untuk melatih dan memelihara model draf multi-miliar parameter yang terpisah. Anda hanya melatih 'draf head' ringan—hanya 2% hingga 5% dari ukuran model target—yang ditambahkan sebagai bagian dari model yang ada. Proses pelatihan yang lebih sederhana dan efisien ini memberikan peningkatan performa decoding yang signifikan sebesar 2x-3x untuk model seperti Llama 70B (bergantung pada jenis beban kerja, misalnya, multi-turn, kode, konteks panjang, dan lainnya).
Namun, memindahkan pendekatan EAGLE-3 yang sudah disederhanakan ini dari sebuah konsep ke layanan cloud yang siap produksi dan berskala adalah perjalanan engineering yang sesungguhnya. Postingan ini membagikan pipeline teknis kami, tantangan utama, dan pelajaran berharga yang kami peroleh selama proses tersebut.
Tantangan #1: Menyiapkan data
Kepala EAGLE-3 perlu dilatih. Langkah pertama yang jelas adalah mengambil set data generik yang tersedia secara publik. Sebagian besar set data ini menimbulkan tantangan, termasuk:
- Persyaratan Penggunaan yang Ketat: Set data ini dibuat menggunakan model yang tidak mengizinkan penggunaan set data ini untuk mengembangkan model yang akan bersaing dengan penyedia asli.
- Kontaminasi PII: Beberapa set data ini berisi PII yang signifikan, termasuk nama, lokasi, dan bahkan ID keuangan.
- Kualitas tidak terjamin: Beberapa set data hanya berfungsi dengan baik untuk kasus penggunaan "demo" umum, tetapi tidak berfungsi dengan baik untuk beban kerja khusus pelanggan sebenarnya.
Menggunakan data ini apa adanya bukanlah pilihan.
Pelajaran 1: Membangun Pipeline Pembuatan Data Sintetis
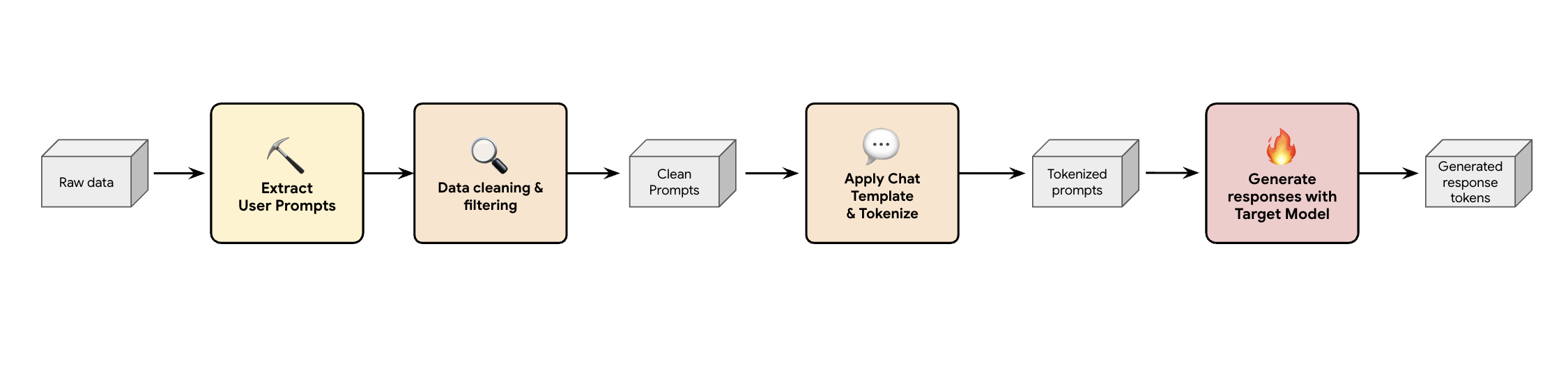
Salah satu solusinya adalah dengan membangun pipeline pembuatan data sintetis. Bergantung pada kasus penggunaan pelanggan, kami memilih set data yang tepat, tidak hanya dengan kualitas yang baik, tetapi juga paling cocok dengan traffic produksi pelanggan kami untuk berbagai beban kerja yang berbeda. Kemudian, Anda dapat mengekstrak hanya perintah pengguna dari kumpulan data ini dan menerapkan pemfilteran PII dan DLP (Pencegahan Kebocoran Data) yang ketat. Perintah bersih ini menerapkan template chat, melakukan tokenisasi, lalu dapat dimasukkan ke dalam model target Anda (misalnya, Llama 3.3 70B) untuk mengumpulkan responsnya.
Pendekatan ini memberikan data yang dihasilkan target yang tidak hanya mematuhi kebijakan dan bersih, tetapi juga cocok dengan distribusi output sebenarnya dari model. Hal ini ideal untuk melatih draf judul.
Tantangan #2: Merekayasa pipeline pelatihan
Keputusan penting lainnya adalah cara memasukkan data pelatihan ke head EAGLE-3. Anda memiliki dua jalur yang berbeda: pelatihan online, tempat embedding 'dibuat secara langsung', dan pelatihan offline, tempat 'embedding dibuat sebelum pelatihan'.
Dalam kasus ini, kami memilih pendekatan pelatihan offline karena memerlukan hardware yang jauh lebih sedikit daripada pelatihan online. Proses ini melibatkan prapenghitungan semua fitur dan penyematan sebelum kita melatih head EAGLE-3. Kami menyimpannya ke GCS dan data tersebut menjadi data pelatihan untuk head EAGLE-3 ringan kami. Setelah Anda memiliki data, pelatihan itu sendiri akan berlangsung cepat. Mengingat ukuran kecil kepala EAGLE-3, pelatihan awal dengan set data asli kami memerlukan waktu sekitar satu hari di satu host. Namun, seiring dengan penskalaan set data, waktu pelatihan meningkat secara proporsional, kini berlangsung selama beberapa hari.

Proses ini mengajarkan dua pelajaran penting yang perlu Anda ingat.
Pelajaran 2: Template Chat Tidak Bersifat Opsional
Saat melatih model yang dioptimalkan untuk perintah, kami menemukan bahwa performa EAGLE-3 dapat sangat bervariasi jika template chat tidak tepat. Anda harus menerapkan template chat spesifik model target (misalnya, Llama 3) sebelum Anda membuat fitur dan embedding. Jika Anda hanya menggabungkan teks mentah, sematan akan salah, dan head akan mempelajari cara memprediksi distribusi yang salah.
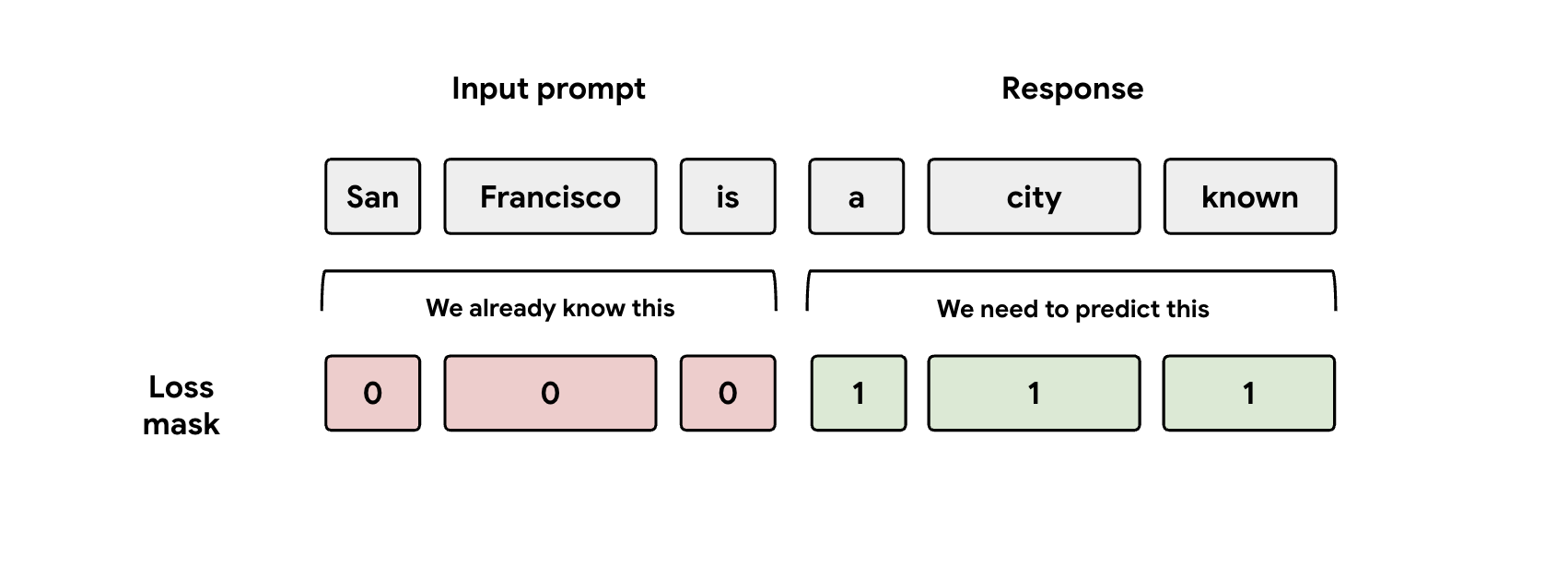
Pelajaran 3: Perhatikan Masker
Selama pelatihan, model diberi representasi perintah dan respons. Namun, head EAGLE-3 hanya boleh mempelajari cara memprediksi representasi respons. Anda harus menyamarkan bagian perintah secara manual dalam fungsi kerugian. Jika Anda tidak melakukannya, head akan membuang-buang kapasitas untuk mempelajari cara memprediksi perintah yang sudah diberikan, dan performa akan terpengaruh.
Tantangan #3: Penyajian dan Penskalaan
Dengan head EAGLE-3 yang terlatih, kami melanjutkan ke fase penayangan. Fase ini menimbulkan tantangan penskalaan yang signifikan. Berikut adalah pembelajaran utama kami.
Pelajaran 4: Framework Penayangan Anda adalah Kuncinya
Dengan bekerja sama secara erat dengan tim SGLang, kami berhasil meluncurkan EAGLE-3 ke produksi dengan performa terbaik. Alasan teknisnya adalah SGLang menerapkan kernel perhatian pohon yang penting. Kernel khusus ini sangat penting karena EAGLE-3 menghasilkan 'pohon draf' kemungkinan (bukan hanya rantai sederhana), dan kernel SGLang dirancang khusus untuk memverifikasi semua jalur percabangan tersebut secara paralel dalam satu langkah. Tanpa ini, Anda tidak akan mendapatkan performa maksimal.
Pelajaran 5: Jangan Biarkan CPU Anda Membatasi GPU Anda
Bahkan setelah mempercepat LLM dengan EAGLE-3, Anda dapat mencapai batas performa lain: CPU. Saat GPU Anda menjalankan inferensi LLM, software yang tidak dioptimalkan akan membuang banyak waktu untuk overhead CPU—seperti peluncuran kernel dan pembukuan metadata. Dalam penjadwal sinkron normal, GPU menjalankan langkah (seperti Draf), lalu tidak melakukan apa pun saat CPU melakukan pembukuan dan meluncurkan langkah Verifikasi berikutnya. Gelembung sinkronisasi ini bertambah, sehingga membuang banyak waktu GPU yang berharga.

Kami mengatasi masalah ini dengan menggunakan Zero-Overhead Overlap Scheduler SGLang. Penjadwal
ini disetel secara khusus untuk alur kerja Draf ->
Verifikasi -> Perluasan Draf multi-langkah decoding spekulatif . Kuncinya adalah melakukan komputasi secara bersamaan. Saat GPU sibuk menjalankan langkah Verifikasi saat ini, CPU sudah bekerja secara paralel untuk meluncurkan kernel untuk langkah Draf dan Perpanjangan Draf berikutnya .
Hal ini menghilangkan gelembung tidak ada aktivitas dengan memastikan tugas GPU berikutnya selalu siap,
menggunakan FutureMap, struktur data pintar yang memungkinkan CPU menyiapkan batch berikutnya SELAGI GPU masih bekerja.

Dengan menghilangkan overhead CPU ini, penjadwal tumpang-tindih memberi kita tambahan peningkatan kecepatan 10% - 20% secara keseluruhan. Hal ini membuktikan bahwa model yang hebat hanyalah setengah dari perjuangan; Anda memerlukan runtime yang dapat mengimbangi.
Hasil Benchmark
Setelah perjalanan ini, apakah semuanya sepadan? Tentu saja.
Kami membandingkan head EAGLE-3 terlatih kami dengan dasar non-spekulatif menggunakan SGLang dengan Llama 4 Scout 17B Instruct. Tolok ukur kami menunjukkan peningkatan kecepatan dekode latensi 2x-3x dan peningkatan throughput yang signifikan bergantung pada jenis workload.
Lihat detail lengkap dan lakukan tolok ukur sendiri menggunakan notebook komprehensif kami.
Metrik 1: Waktu Median Per Token Output (TPOT)
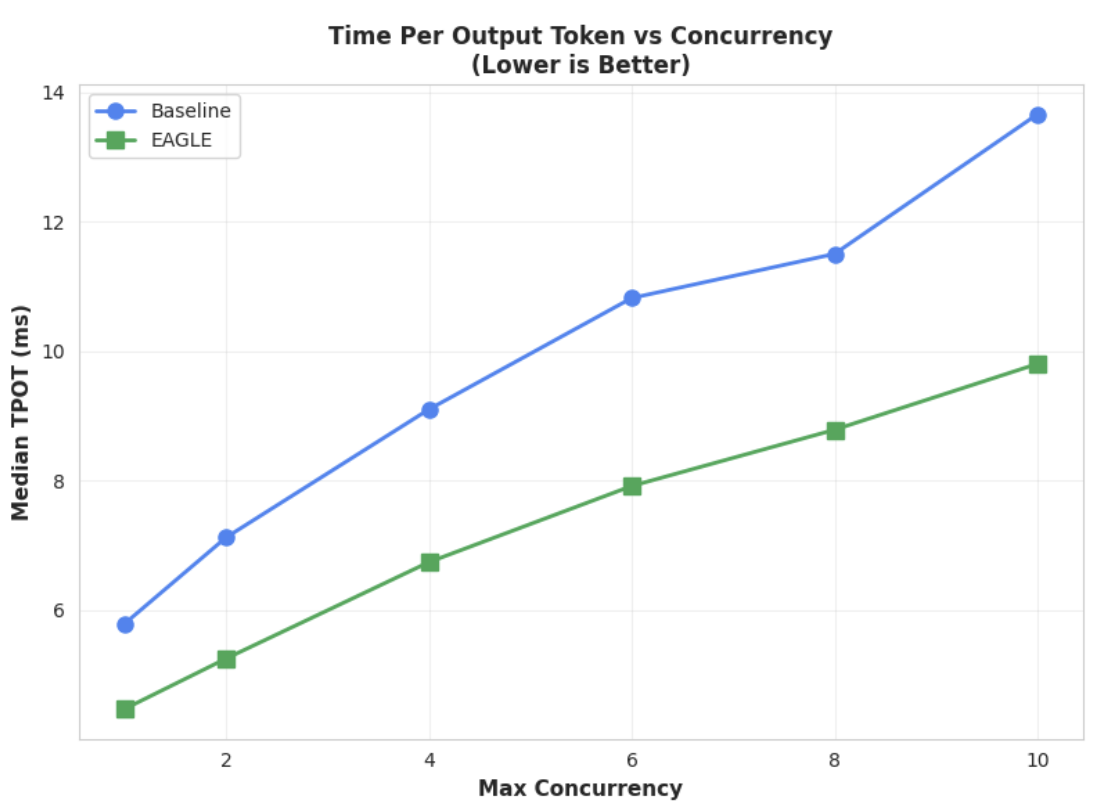
Diagram ini menunjukkan performa latensi EAGLE-3 yang lebih baik. Diagram Waktu Per Token Output (TPOT) menunjukkan bahwa model yang dipercepat EAGLE-3 (garis hijau) secara konsisten mencapai latensi yang lebih rendah (lebih cepat) daripada baseline (garis biru) di semua tingkat konkurensi yang diuji.
Metrik 2: Throughput Output
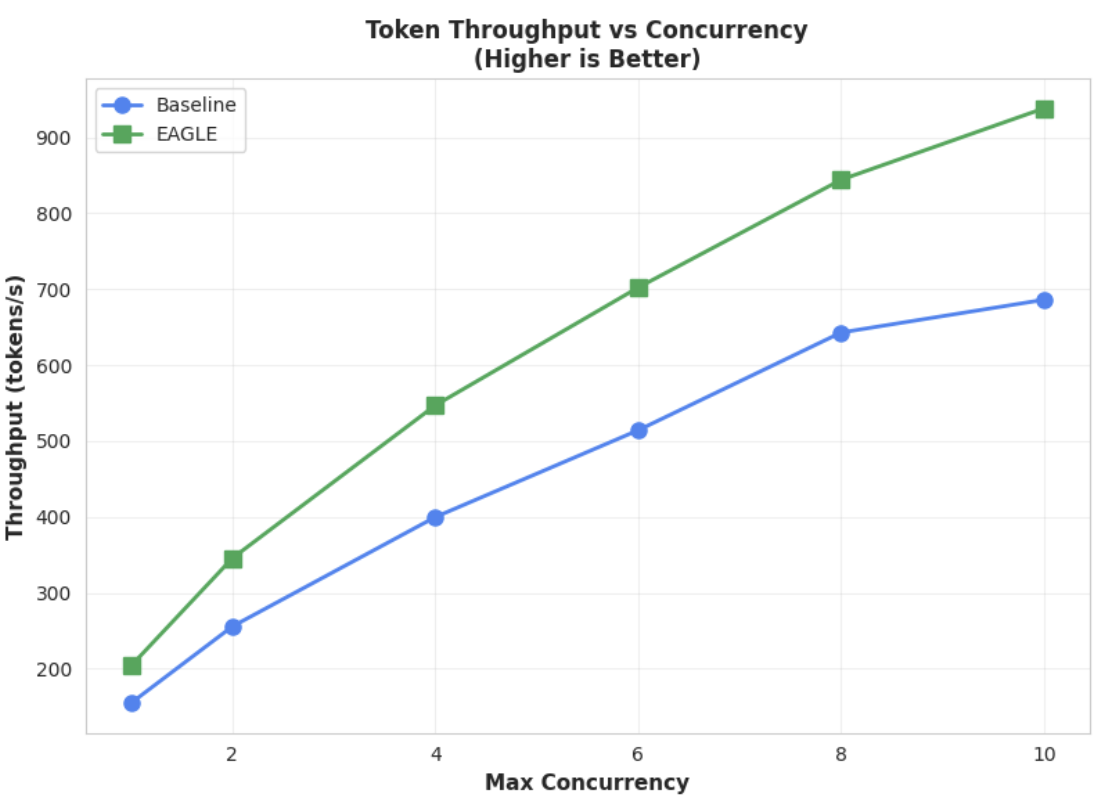
Diagram ini lebih menyoroti keunggulan throughput EAGLE-3. Diagram Throughput Token vs. Concurrency dengan jelas menunjukkan bahwa model yang dipercepat EAGLE-3 (garis hijau) secara konsisten dan substansial mengungguli model dasar (garis biru).
Meskipun pengamatan serupa berlaku untuk model yang lebih besar, perlu diperhatikan bahwa peningkatan Waktu ke Token Pertama (TTFT) mungkin diamati dibandingkan dengan metrik performa lainnya. Selain itu, performa ini bervariasi menurut tugas yang bergantung pada tugas, seperti yang diilustrasikan oleh contoh berikut:
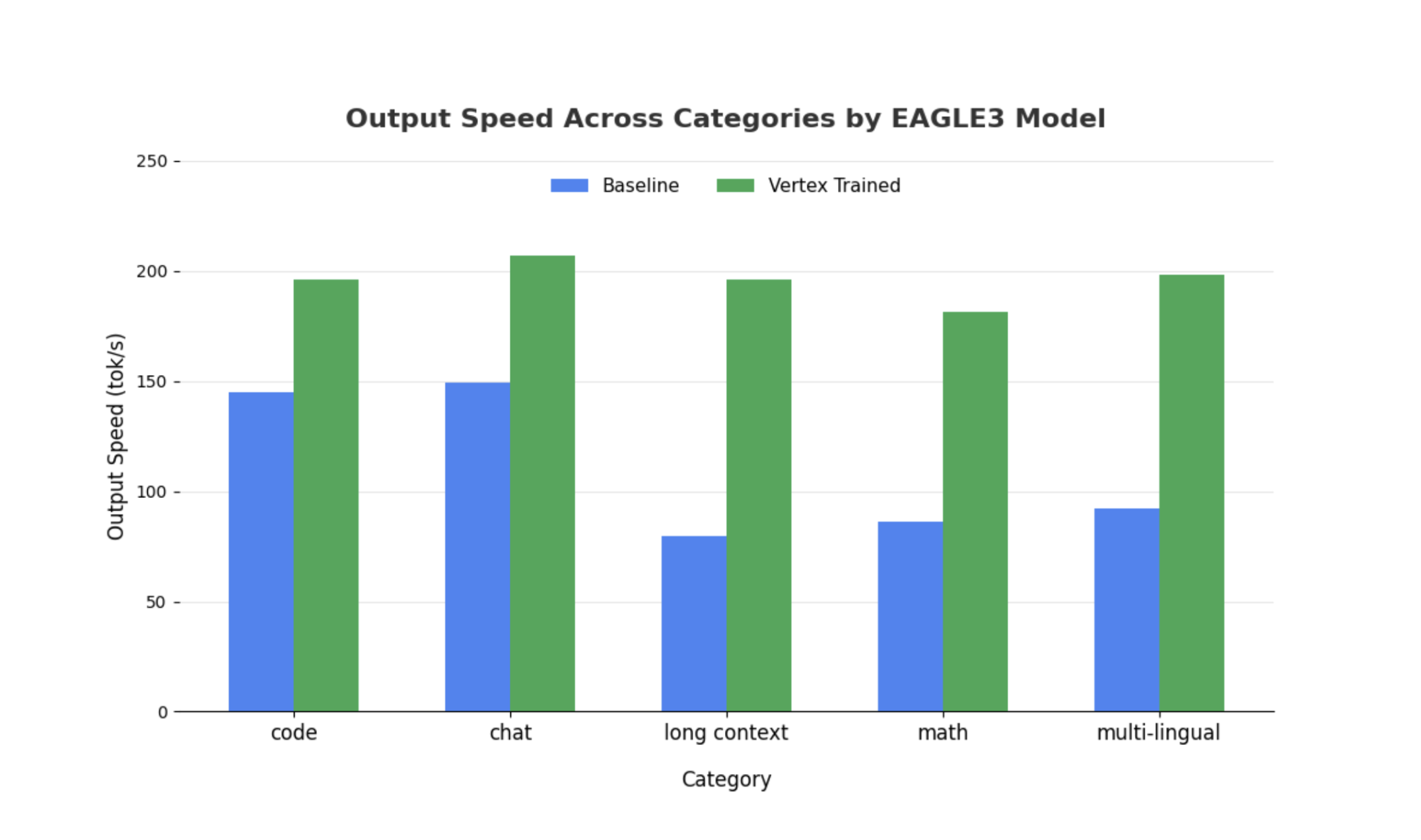
Kesimpulan: Sekarang Giliran Anda
EAGLE-3 bukan hanya konsep penelitian; ini adalah pola siap produksi yang dapat memberikan peningkatan kecepatan decoding yang nyata sebesar 2x. Namun, untuk menskalakannya, diperlukan upaya engineering yang nyata. Untuk men-deploy teknologi ini secara andal bagi pengguna Anda, Anda harus:
- Bangun pipeline data sintetis yang sesuai.
- Tangani dengan benar template chat dan mask kerugian serta latih model pada set data skala besar.
Di Vertex AI, kami telah menyederhanakan seluruh proses ini untuk Anda, dengan menyediakan infrastruktur dan container yang dioptimalkan yang dirancang untuk menskalakan aplikasi berbasis LLM Anda. Untuk memulai, lihat referensi berikut:
Terima kasih telah membaca
Kami menerima masukan dan pertanyaan Anda tentang Vertex AI.
Ucapan terima kasih
Kami ingin mengucapkan terima kasih yang tulus kepada tim SGLang—khususnya Ying Sheng, Lianmin Zheng, Yineng Zhang, Xinyuan Tong, Liangsheng Yin, serta tim SGLang/SpecForge—khususnya Shenggui Li, Yikai Zhu—atas dukungan mereka yang sangat berharga selama proyek ini. Bantuan mereka yang sangat berharga dan insight teknis yang mendalam sangat berperan dalam keberhasilan proyek ini.