

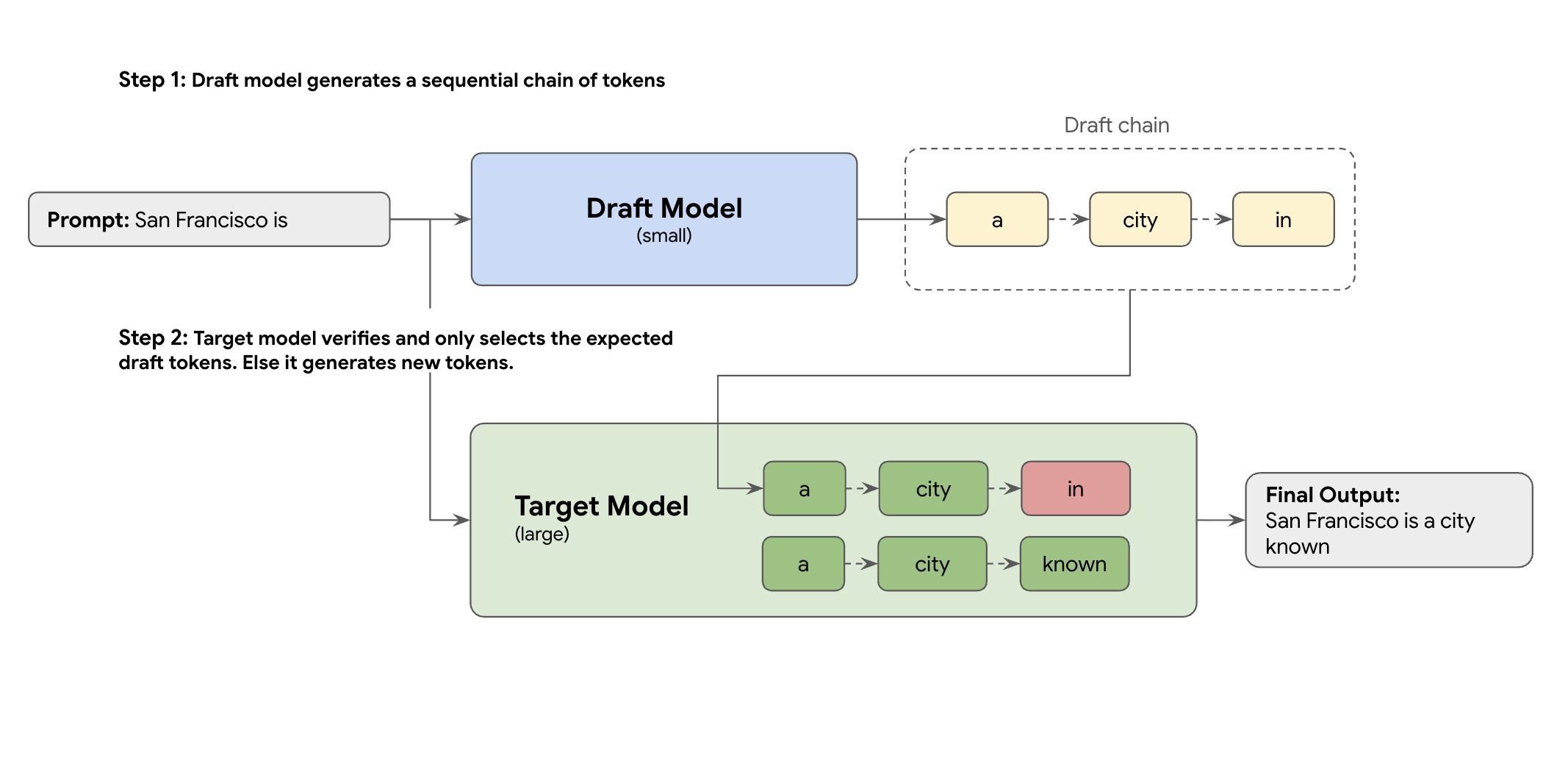
La solution est le décodage spéculatif. Cette technique d'optimisation accélère le processus lent et séquentiel de génération d'un jeton à la fois par votre grand LLM (le modèle cible) en introduisant un mécanisme de brouillon.
Ce mécanisme de brouillon propose rapidement plusieurs jetons suivants à la fois. Le grand modèle cible vérifie ensuite ces propositions dans un seul lot parallèle. Il accepte le préfixe correspondant le plus long de ses propres prédictions et poursuit la génération à partir de ce nouveau point.
Mais tous les mécanismes de brouillon ne se valent pas. L'approche classique de ciblage de brouillon utilise un modèle LLM distinct et plus petit comme rédacteur, ce qui signifie que vous devez héberger et gérer davantage de ressources de diffusion, ce qui entraîne des coûts supplémentaires.
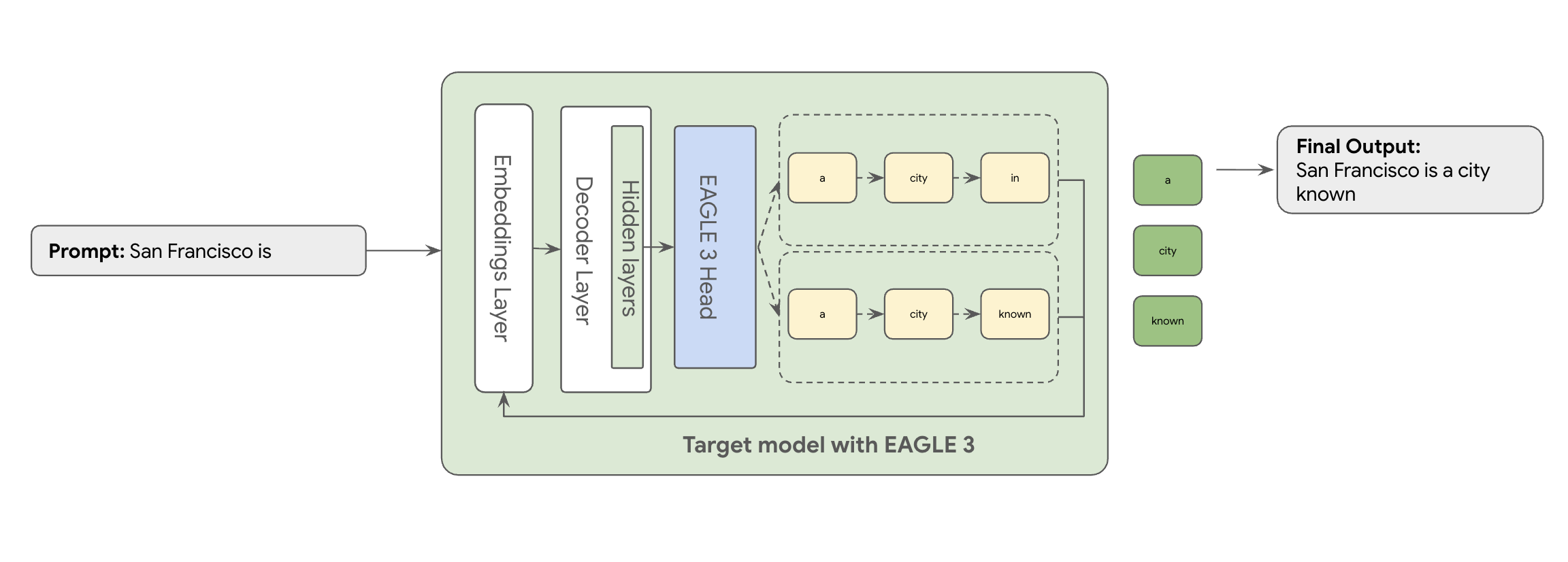
C'est là qu'intervient EAGLE-3 (Extrapolative Attention Guided LEarning). EAGLE-3 est une approche plus avancée. Au lieu d 'un modèle entièrement distinct, il ajoute une "tête de brouillon" extrêmement légère (seulement 2 à 5 % de la taille du modèle cible) directement à ses couches internes. Cette tête fonctionne à la fois au niveau des caractéristiques et des jetons, en ingérant les caractéristiques des états cachés du modèle cible pour extrapoler et prédire un arbre de futurs jetons.
Résultat : Tous les avantages du décodage spéculatif, tout en éliminant les frais généraux liés à l'entraînement et à l'exécution d'un deuxième modèle.
L'approche d'EAGLE-3 est beaucoup plus efficace que la tâche complexe et gourmande en ressources que représente l'entraînement et la maintenance d'un modèle brouillon distinct de plusieurs milliards de paramètres. Vous n'entraînez qu'une "tête brouillon" légère, qui ne représente que 2 % à 5 % de la taille du modèle cible et qui est ajoutée à votre modèle existant. Ce processus d'entraînement plus simple et plus efficace permet d'améliorer considérablement les performances de décodage (de deux à trois fois) pour les modèles tels que Llama 70B (en fonction des types de charge de travail, par exemple, multi-tours, code, contexte long, etc.).
Mais même cette approche EAGLE-3 simplifiée, qui passe d'un article à un service cloud à grande échelle et prêt pour la production, représente un véritable défi d'ingénierie. Cet article présente notre pipeline technique, les principaux défis rencontrés et les leçons que nous avons tirées de notre expérience.
Défi 1 : Préparer les données
La tête EAGLE-3 doit être entraînée. La première étape évidente consiste à récupérer un ensemble de données génériques disponibles publiquement. La plupart de ces ensembles de données présentent des difficultés, y compris les suivantes :
- Conditions d'utilisation strictes : ces ensembles de données sont générés à l'aide de modèles qui n'autorisent pas leur utilisation pour développer des modèles qui concurrenceraient les fournisseurs d'origine.
- Contamination par des informations permettant d'identifier personnellement l'utilisateur : certains de ces ensembles de données contiennent des informations permettant d'identifier personnellement l'utilisateur, y compris des noms, des lieux et même des identifiants financiers.
- Qualité non garantie : certains ensembles de données ne fonctionnent bien que pour les cas d'utilisation de démonstration généraux, mais ne sont pas optimaux pour la charge de travail spécialisée des clients réels.
Il n'est pas possible d'utiliser ces données telles quelles.
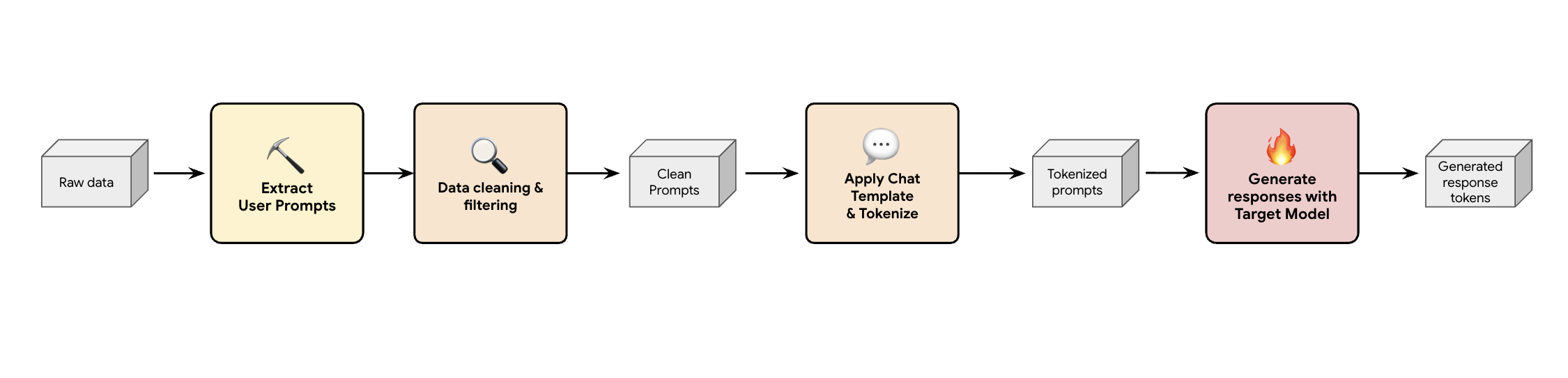
Leçon 1 : Créer un pipeline de génération de données synthétiques
Une solution consiste à créer un pipeline de génération de données synthétiques. En fonction des cas d'utilisation de nos clients, nous sélectionnons l'ensemble de données approprié, qui est non seulement de bonne qualité, mais qui correspond également le mieux au trafic de production de nos clients pour différentes charges de travail. Vous pouvez ensuite extraire uniquement les requêtes utilisateur de ces ensembles de données et appliquer un filtrage rigoureux de la protection contre la perte de données (DLP) et des informations permettant d'identifier personnellement l'utilisateur (PII). Ces requêtes propres appliquent un modèle de chat, les tokenisent, puis peuvent être transmises à votre modèle cible (par exemple, Llama 3.3 70B) pour collecter ses réponses.
Cette approche fournit des données générées par la cible qui sont non seulement conformes et propres, mais aussi bien adaptées à la distribution de sortie réelle du modèle. C'est idéal pour entraîner la tête de brouillon.
Défi 2 : Ingénierie du pipeline d'entraînement
Une autre décision clé consiste à déterminer comment fournir les données d'entraînement à la tête EAGLE-3. Vous avez deux options : l'entraînement en ligne, où les embeddings sont générés à la volée, et l'entraînement hors connexion, où les embeddings sont générés avant l'entraînement.
Dans notre cas, nous avons choisi une approche d'entraînement hors connexion, car elle nécessite beaucoup moins de matériel que l'entraînement en ligne. Ce processus implique de précalculer toutes les caractéristiques et tous les embeddings avant d'entraîner la tête EAGLE-3. Nous les enregistrons dans GCS, et elles deviennent les données d'entraînement pour notre tête EAGLE-3 légère. Une fois que vous disposez des données, l'entraînement lui-même est rapide. Compte tenu de la petite taille de la tête EAGLE-3, l'entraînement initial avec notre ensemble de données d'origine a nécessité environ une journée sur un seul hôte. Cependant, à mesure que nous avons augmenté la taille de notre ensemble de données, les temps d'entraînement ont augmenté en conséquence et s'étendent désormais sur plusieurs jours.

Ce processus nous a appris deux leçons non négligeables que vous devez garder à l'esprit.
Leçon 2 : Les modèles de chat ne sont pas facultatifs
Lors de l'entraînement du modèle ajusté aux instructions, nous avons constaté que les performances d'EAGLE-3 peuvent varier considérablement lorsque le modèle de chat n'est pas adapté. Vous devez appliquer le modèle de chat spécifique du modèle cible (par exemple, Llama 3) avant de générer les caractéristiques et les embeddings. Si vous concaténez simplement du texte brut, les embeddings seront incorrects et votre tête apprendra à prédire la mauvaise distribution.
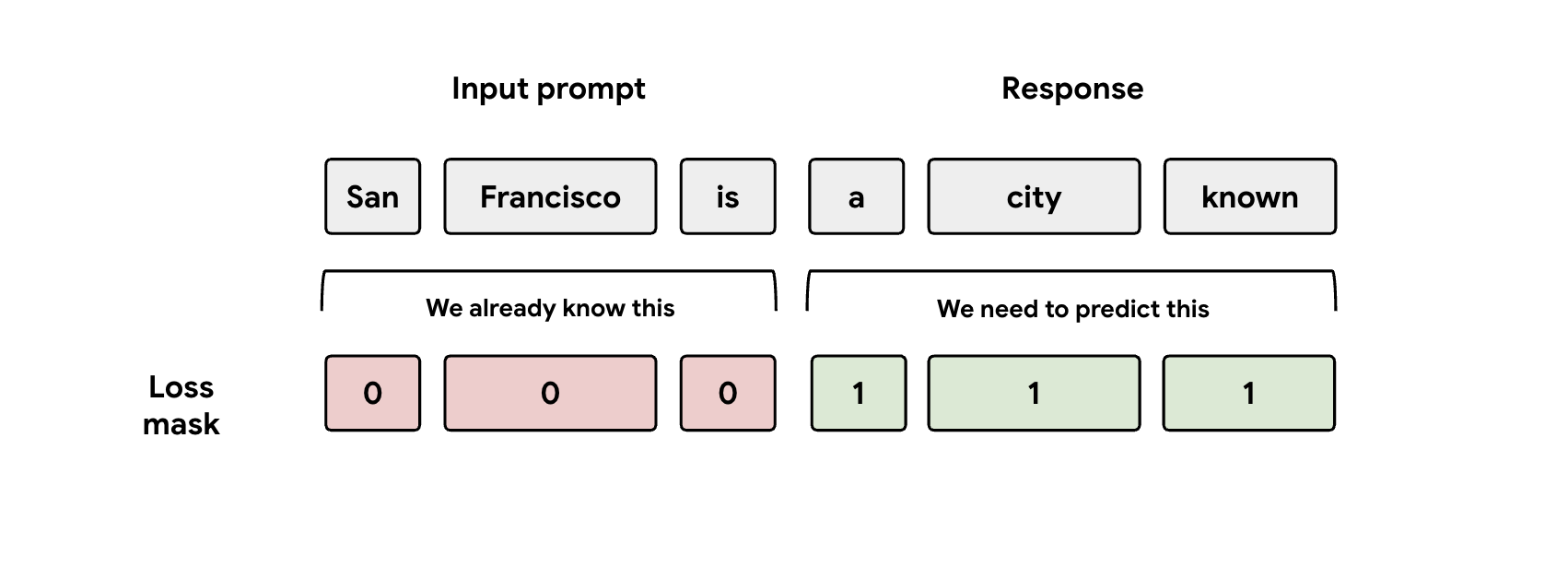
Leçon 3 : Attention au masque
Lors de l'entraînement, le modèle reçoit les représentations de la requête et de la réponse. Toutefois, la tête EAGLE-3 ne doit apprendre qu'à prédire la représentation de la réponse. Vous devez masquer manuellement la partie "invite" dans votre fonction de perte. Si vous ne le faites pas, la tête gaspille de la capacité à apprendre à prédire le prompt qui lui a déjà été donné, et les performances en pâtiront.
Défi n° 3 : Diffusion et mise à l'échelle
Une fois la tête EAGLE-3 entraînée, nous sommes passés à la phase de mise en service. Cette phase a entraîné des problèmes de mise à l'échelle importants. Voici nos principaux enseignements.
Leçon 4 : Votre framework de diffusion est essentiel
En travaillant en étroite collaboration avec l'équipe SGLang, nous avons réussi à déployer EAGLE-3 en production avec les meilleures performances. La raison technique est que SGLang implémente un noyau d'attention arborescent crucial. Ce noyau spécial est essentiel, car EAGLE-3 génère un "arbre brouillon" de possibilités (et pas seulement une simple chaîne). Le noyau de SGLang est spécifiquement conçu pour vérifier tous ces chemins de bifurcation en parallèle en une seule étape. Sans cela, vous passerez à côté de performances.
Leçon 5 : Ne laissez pas votre processeur limiter votre GPU
Même après avoir accéléré votre LLM avec EAGLE-3, vous pouvez rencontrer un autre problème de performances : le processeur. Lorsque vos GPU exécutent l'inférence LLM, les logiciels non optimisés perdent énormément de temps en surcharge du processeur, comme le lancement du noyau et la gestion des métadonnées. Dans un planificateur synchrone normal, le GPU exécute une étape (comme Brouillon), puis reste inactif pendant que le CPU effectue sa comptabilité et lance l'étape Vérifier suivante. Ces bulles de synchronisation s'accumulent et gaspillent d'énormes quantités de temps GPU précieux.

Pour résoudre ce problème, nous avons utilisé le planificateur de chevauchement sans surcharge de SGLang. Ce planificateur est spécifiquement adapté au workflow en plusieurs étapes de décodage spéculatif Brouillon → Vérifier → Étendre le brouillon . La clé est de chevaucher le calcul. Pendant que le GPU est occupé à exécuter l'étape Vérifier actuelle, le CPU travaille déjà en parallèle pour lancer les kernels des étapes Brouillon et Étendre le brouillon suivantes .
Cela élimine la bulle d'inactivité en s'assurant que le prochain travail du GPU est toujours prêt, en utilisant un FutureMap, une structure de données intelligente qui permet au CPU de préparer le prochain lot pendant que le GPU est toujours en train de travailler.

En éliminant cette surcharge du processeur, le planificateur de chevauchement nous permet d'obtenir un gain de vitesse supplémentaire de 10 à 20 % dans l'ensemble. Cela prouve qu'un excellent modèle ne représente que la moitié du chemin à parcourir. Vous avez besoin d'un environnement d'exécution capable de suivre le rythme.
Résultats du benchmark
Après ce parcours, valait-il la peine ? Absolument.
Nous avons comparé notre tête EAGLE-3 entraînée à la référence non spéculative à l'aide de SGLang avec Llama 4 Scout 17B Instruct. Nos benchmarks montrent une accélération de la latence de décodage de 2 à 3 fois et des gains de débit importants en fonction des types de charge de travail.
Pour en savoir plus et effectuer votre propre benchmark, consultez notre notebook complet.
Métrique 1 : Délai médian par jeton de sortie (TPOT)
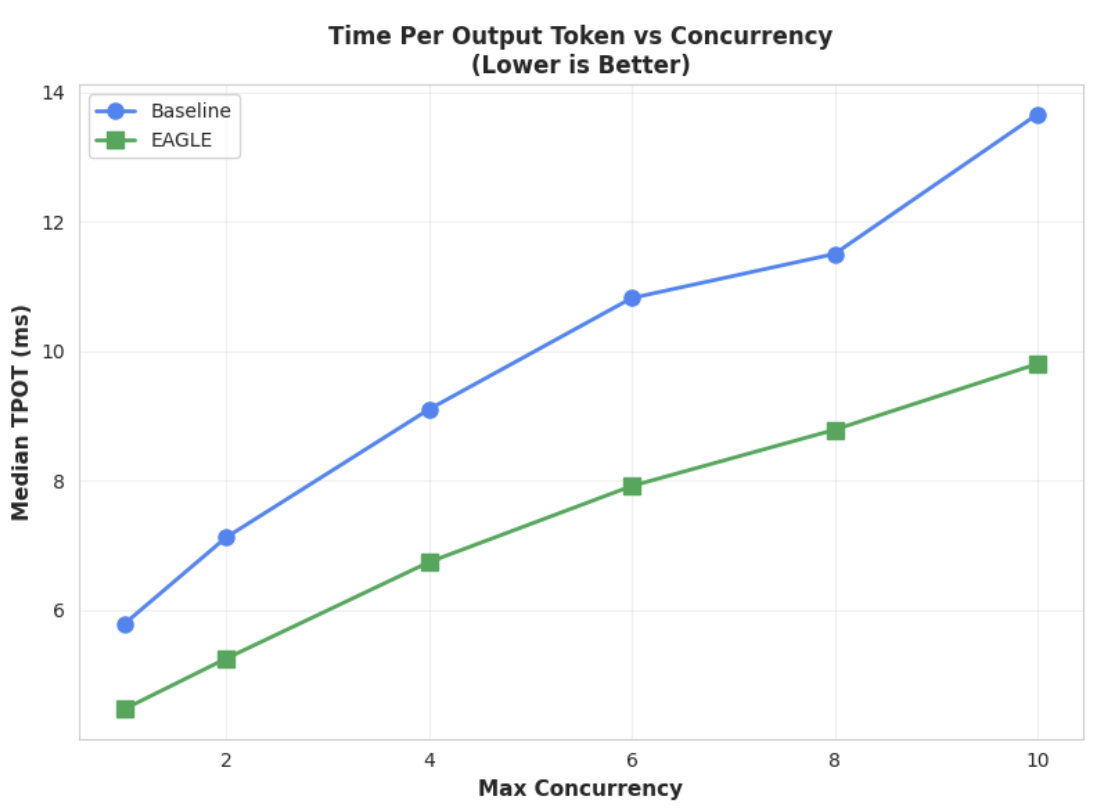
Ce graphique montre les meilleures performances de latence d'EAGLE-3. Le graphique "Temps par jeton de sortie" (TPOT) montre que le modèle accéléré EAGLE-3 (ligne verte) atteint systématiquement une latence inférieure (plus rapide) à celle de la référence (ligne bleue) pour tous les niveaux de concurrence testés.
Métrique 2 : Débit de sortie
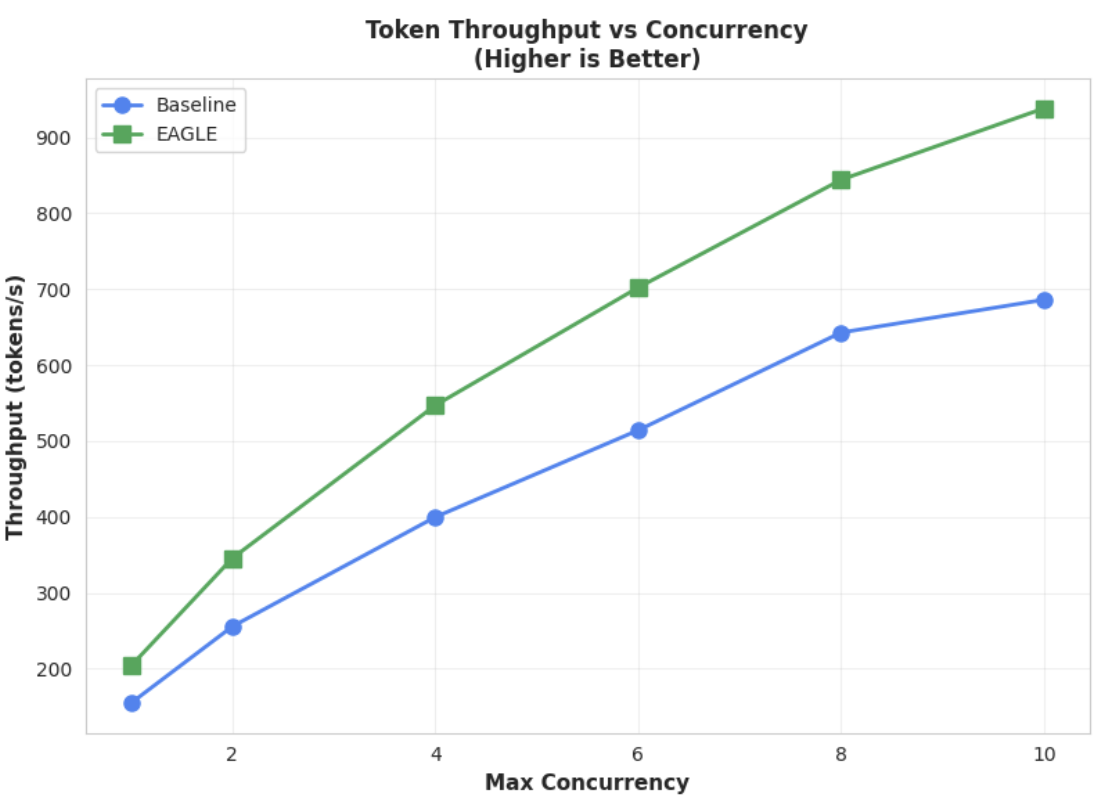
Ce graphique met en évidence l'avantage de débit d'EAGLE-3. Le graphique "Débit de jetons vs concurrence" montre clairement que le modèle accéléré EAGLE-3 (ligne verte) surpasse constamment et considérablement le modèle de référence (ligne bleue).
Bien que des observations similaires soient valables pour les modèles plus volumineux, il convient de noter qu'une augmentation du délai avant le premier jeton (TTFT) peut être observée par rapport à d'autres métriques de performances. De plus, ces performances varient en fonction de la tâche, comme l'illustrent les exemples suivants :
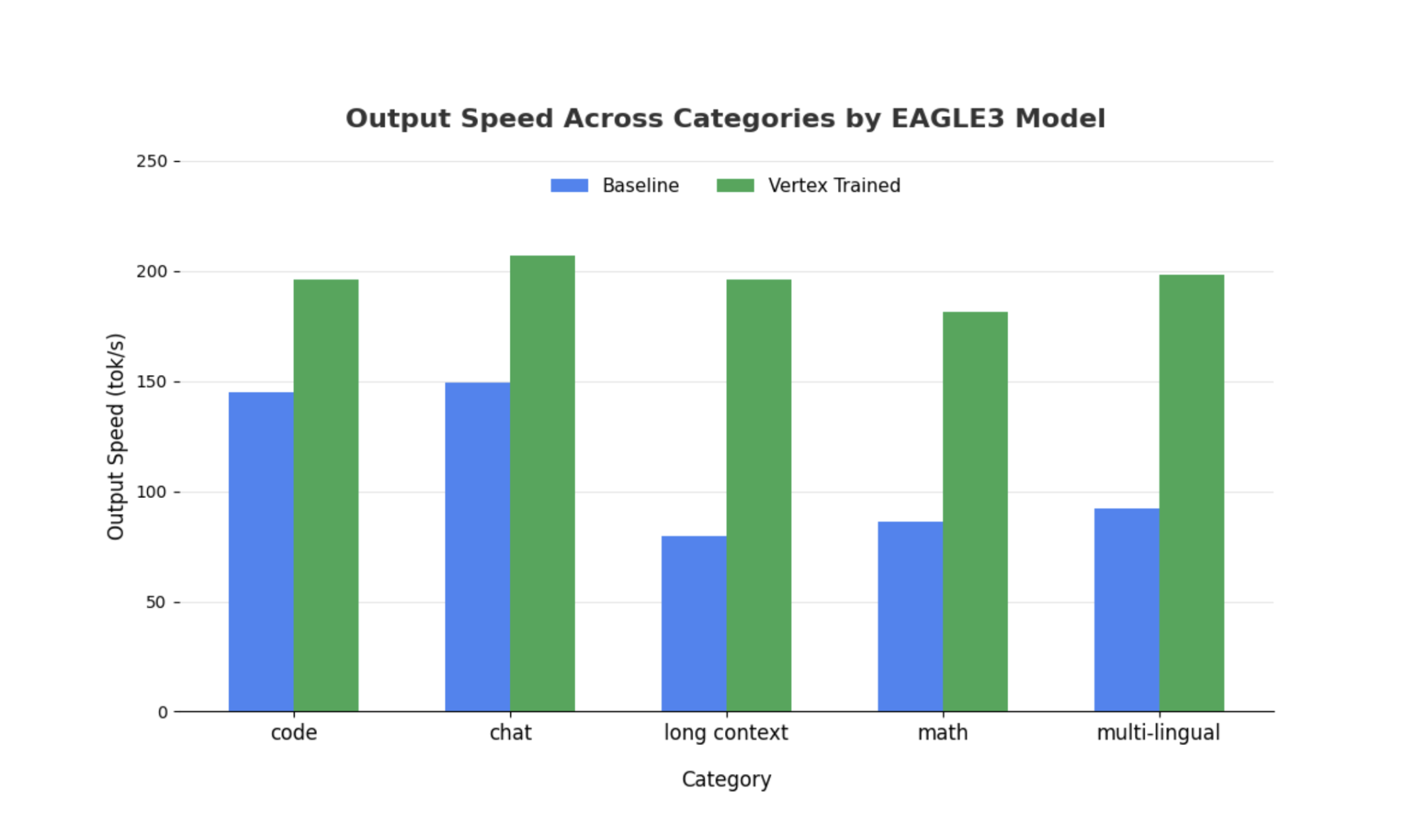
Conclusion : à vous de jouer
EAGLE-3 n'est pas qu'un concept de recherche. Il s'agit d'un modèle prêt pour la production qui peut doubler la latence de décodage. Mais pour le faire évoluer, il faut un véritable effort d'ingénierie. Pour déployer cette technologie de manière fiable pour vos utilisateurs, vous devez :
- Créez un pipeline de données synthétiques conforme.
- Gérez correctement les modèles de chat et les masques de perte, et entraînez le modèle sur un ensemble de données à grande échelle.
Sur Vertex AI, nous avons déjà simplifié l'ensemble de ce processus pour vous, en fournissant un conteneur et une infrastructure optimisés conçus pour faire évoluer vos applications basées sur des LLM. Pour commencer, consultez les ressources suivantes :
Merci de votre attention
N'hésitez pas à nous faire part de vos commentaires et questions sur Vertex AI.
Remerciements
Nous tenons à exprimer notre sincère gratitude à l'équipe SGLang, en particulier à Ying Sheng, Lianmin Zheng, Yineng Zhang, Xinyuan Tong et Liangsheng Yin, ainsi qu'à l'équipe SGLang/SpecForge, en particulier à Shenggui Li et Yikai Zhu, pour leur soutien inestimable tout au long de ce projet. Leur aide généreuse et leurs connaissances techniques approfondies ont été essentielles au succès de ce projet.