

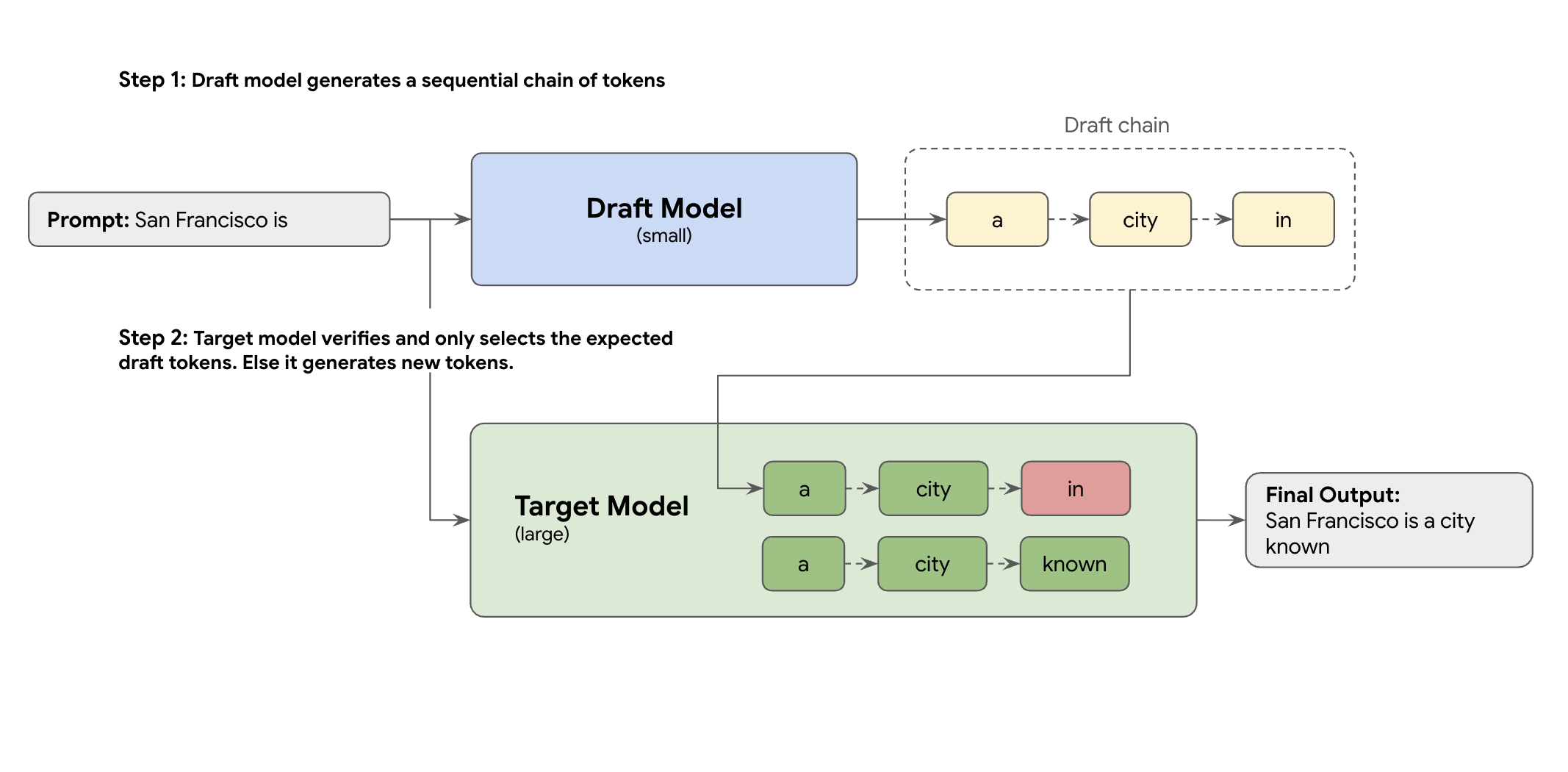
La solución es el decodificador especulativo. Esta técnica de optimización acelera el proceso lento y secuencial de tu LLM grande (el modelo de destino) que genera un token a la vez, ya que introduce un mecanismo de borrador.
Este mecanismo de borrador propone rápidamente varios tokens siguientes a la vez. A continuación, el modelo de destino grande verifica estas propuestas en un solo lote paralelo. Acepta el prefijo más largo que coincida con sus propias predicciones y continúa la generación a partir de ese nuevo punto.
Sin embargo, no todos los mecanismos de borrador son iguales. El enfoque clásico de borrador y objetivo usa un modelo de LLM independiente y más pequeño como borrador, lo que significa que tienes que alojar y gestionar más recursos de servicio, lo que conlleva costes adicionales.
Haz clic para ampliar la imagen
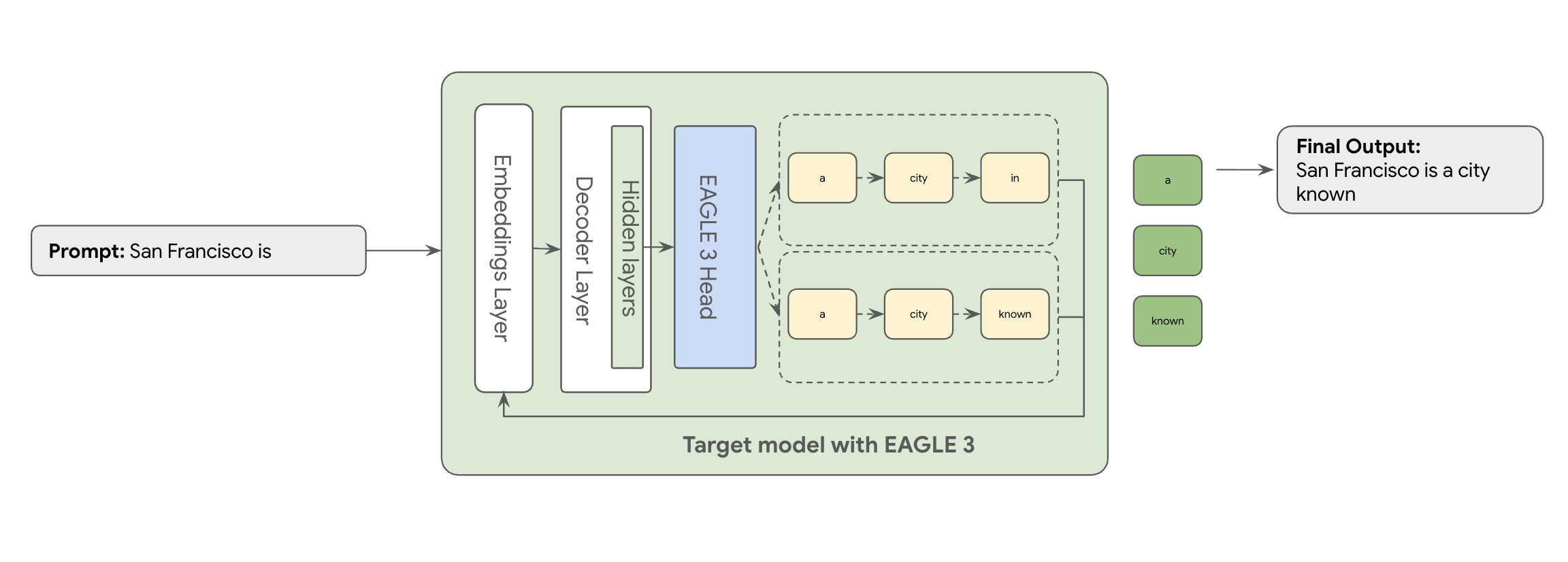
Aquí es donde entra en juego EAGLE-3 (Extrapolative Attention Guided LEarning). EAGLE-3 es un enfoque más avanzado. En lugar de un modelo completamente independiente, se adjunta un "encabezado de borrador" extremadamente ligero (solo entre el 2 y el 5% del tamaño del modelo de destino) directamente a sus capas internas. Este encabezado funciona tanto a nivel de función como de token, ingiriendo funciones de los estados ocultos del modelo de destino para extrapolar y predecir un árbol de tokens futuros.
¿Cuál es el resultado? Todas las ventajas de la decodificación especulativa, pero sin la sobrecarga de entrenar y ejecutar un segundo modelo.
El enfoque de EAGLE-3 es mucho más eficiente que la compleja tarea de entrenar y mantener un borrador de modelo independiente con miles de millones de parámetros, que requiere muchos recursos. Solo entrenas un "borrador" ligero, que ocupa entre el 2% y el 5% del tamaño del modelo de destino, y que se añade a tu modelo. Este proceso de entrenamiento más sencillo y eficiente ofrece una mejora significativa del rendimiento de decodificación de entre 2 y 3 veces para modelos como Llama 70B (en función de los tipos de carga de trabajo, como las conversaciones de varias interacciones, el código o el contexto largo, entre otros).
Haz clic para ampliar la imagen
Sin embargo, pasar de este enfoque optimizado de EAGLE-3 de un documento a un servicio en la nube escalado y listo para producción es un verdadero reto de ingeniería. En esta publicación, compartimos nuestro proceso técnico, los principales retos y las valiosas lecciones que hemos aprendido por el camino.
Reto 1: Preparar los datos
Es necesario entrenar el modelo EAGLE-3. El primer paso es obtener un conjunto de datos público genérico. La mayoría de estos conjuntos de datos presentan dificultades, como las siguientes:
- Términos de Uso estrictos: estos conjuntos de datos se generan mediante modelos que no permiten usarlos para desarrollar modelos que compitan con los proveedores originales.
- Contaminación con IPI: algunos de estos conjuntos de datos contienen una cantidad significativa de IPI, como nombres, ubicaciones e incluso identificadores financieros.
- Calidad no garantizada: algunos conjuntos de datos solo funcionan bien en casos prácticos generales de demostración, pero no en cargas de trabajo especializadas de clientes reales.
No se puede usar esta información tal cual.
Lección 1: Crear un flujo de procesamiento para generar datos sintéticos
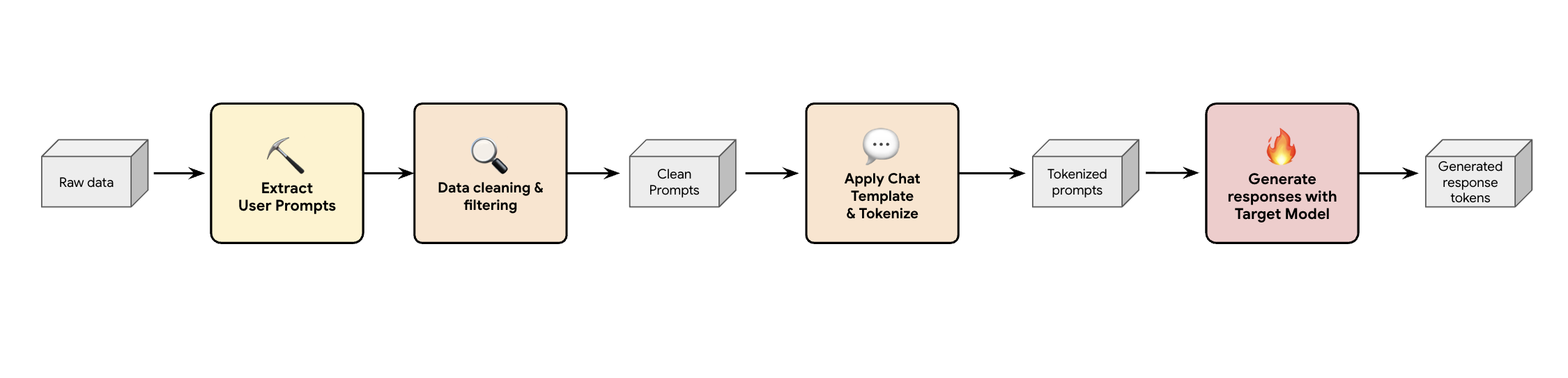
Una solución es crear una canalización de generación de datos sintéticos. En función de los casos prácticos de nuestros clientes, seleccionamos el conjunto de datos adecuado, que no solo es de buena calidad, sino que también se adapta mejor al tráfico de producción de nuestros clientes para diferentes cargas de trabajo. Después, puedes extraer solo las peticiones de los usuarios de estos conjuntos de datos y aplicar un filtrado riguroso de DLP (prevención de la pérdida de datos) e IPI. Estas peticiones limpias aplican una plantilla de chat, las tokenizan y, a continuación, se pueden introducir en el modelo de destino (por ejemplo, Llama 3.3 70B) para recoger sus respuestas.
Este enfoque proporciona datos generados por el objetivo que no solo son conformes y limpios, sino que también se ajustan bien a la distribución de salida real del modelo. Es ideal para entrenar la cabeza del borrador.
Haz clic para ampliar la imagen
Reto 2: diseñar el flujo de procesamiento de entrenamiento
Otra decisión clave es cómo proporcionar los datos de entrenamiento al encabezado EAGLE-3. Tienes dos opciones: entrenamiento online, donde las inserciones se generan sobre la marcha, y entrenamiento offline, donde las inserciones se generan antes del entrenamiento.
En nuestro caso, hemos elegido un enfoque de entrenamiento sin conexión porque requiere mucho menos hardware que el entrenamiento online. Este proceso implica precalcular todas las características y las inserciones antes de entrenar el modelo EAGLE-3. Los guardamos en GCS y se convierten en los datos de entrenamiento de nuestro ligero encabezado EAGLE-3. Una vez que tengas los datos, el entrenamiento será rápido. Dado el tamaño reducido del cabezal de EAGLE-3, la preparación inicial con nuestro conjunto de datos original requirió aproximadamente un día en un solo host. Sin embargo, a medida que hemos ampliado nuestro conjunto de datos, los tiempos de entrenamiento han aumentado proporcionalmente y ahora se prolongan durante varios días.

Haz clic para ampliar la imagen
Este proceso nos ha enseñado dos lecciones importantes que debes tener en cuenta.
Lección 2: Las plantillas de chat no son opcionales
Durante el entrenamiento del modelo ajustado para instrucciones, descubrimos que el rendimiento de EAGLE-3 puede variar mucho si la plantilla de chat no es la adecuada. Debes aplicar la plantilla de chat específica del modelo de destino (por ejemplo, Llama 3) antes de generar las funciones y las inserciones. Si solo concatenas texto sin formato, las inserciones serán incorrectas y tu encabezado aprenderá a predecir la distribución incorrecta.
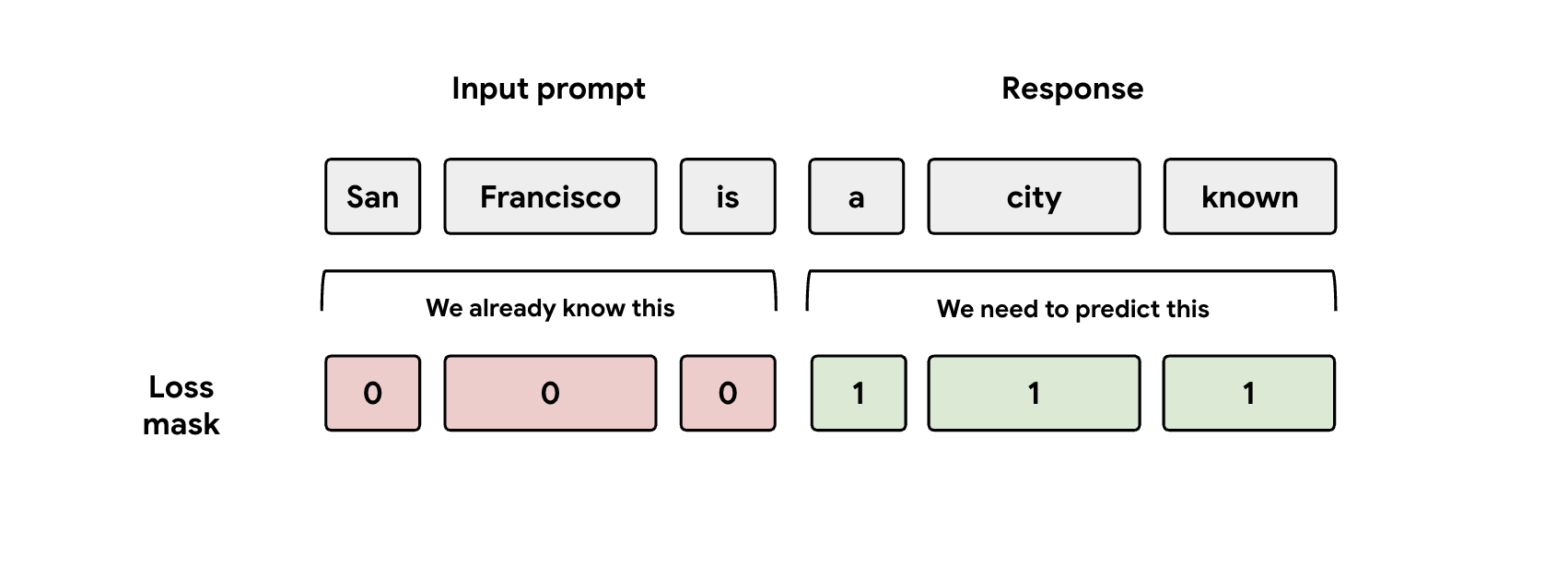
Lección 3: Cuidado con la máscara
Durante el entrenamiento, se proporcionan al modelo las representaciones de la petición y de la respuesta. Sin embargo, el encabezado de EAGLE-3 solo debería aprender a predecir la representación de la respuesta. Debes enmascarar manualmente la parte de la petición en tu función de pérdida. Si no lo haces, el encabezado desperdiciará capacidad aprendiendo a predecir la petición que ya se le ha dado y el rendimiento se verá afectado.
Haz clic para ampliar la imagen
Reto 3: publicación y escalado
Con un cabezal EAGLE-3 entrenado, pasamos a la fase de servicio. Esta fase supuso importantes retos de escalabilidad. Estas son las principales conclusiones.
Lección 4: Tu framework de servicio es clave
Gracias a la estrecha colaboración con el equipo de SGLang, hemos podido lanzar EAGLE-3 en producción con el mejor rendimiento. El motivo técnico es que SGLang implementa un kernel de atención de árbol crucial. Este kernel especial es crucial porque EAGLE-3 genera un "árbol de borrador" de posibilidades (no solo una cadena simple) y el kernel de SGLang se ha diseñado específicamente para verificar todas esas rutas ramificadas en paralelo en un solo paso. Si no lo haces, estarás desaprovechando el rendimiento.
Lección 5: No dejes que tu CPU limite el rendimiento de tu GPU
Incluso después de acelerar tu LLM con EAGLE-3, puedes encontrarte con otro obstáculo en cuanto al rendimiento: la CPU. Cuando tus GPUs ejecuten la inferencia de LLMs, el software no optimizado perderá una gran cantidad de tiempo en la sobrecarga de la CPU, como el lanzamiento del kernel y el registro de metadatos. En un programador síncrono normal, la GPU ejecuta un paso (como Borrador) y, a continuación, se queda inactiva mientras la CPU hace sus tareas de gestión y lanza el siguiente paso Verificar. Estas burbujas de sincronización se acumulan y desperdician enormes cantidades de tiempo valioso de la GPU.

Haz clic para ampliar la imagen
Para resolverlo, usamos el programador de superposición sin sobrecarga de SGLang. Este
programador se ha diseñado específicamente para el flujo de trabajo de varios pasos de la decodificación especulativa: Borrador ->
Verificar -> Ampliar borrador . La clave es superponer los cálculos. Mientras la GPU está ocupada ejecutando el paso Verificar actual, la CPU ya está trabajando en paralelo para iniciar los kernels de los siguientes pasos Borrador y Ampliar borrador .
De esta forma, se elimina el tiempo de inactividad, ya que se asegura de que la GPU siempre tenga lista la siguiente tarea. Para ello, se usa una FutureMap, una estructura de datos inteligente que permite a la CPU preparar el siguiente lote mientras la GPU sigue trabajando.

Haz clic para ampliar la imagen
Al eliminar este consumo de CPU, el programador de superposición nos ofrece una mejora de la velocidad del 10 al 20 % en general. Esto demuestra que un buen modelo es solo la mitad del trabajo; necesitas un tiempo de ejecución que esté a la altura.
Resultados de comparativas
Después de este viaje, ¿ha merecido la pena? Desde luego.
Hemos comparado nuestro modelo EAGLE-3 entrenado con la base de referencia no especulativa usando SGLang con Llama 4 Scout 17B Instruct. Nuestras comparativas muestran que la latencia de decodificación se reduce entre 2 y 3 veces, y que el rendimiento aumenta significativamente en función de los tipos de carga de trabajo.
Consulta todos los detalles y haz la prueba tú mismo con nuestro cuaderno completo.
Métrica 1: tiempo medio por token de salida (TPOT)
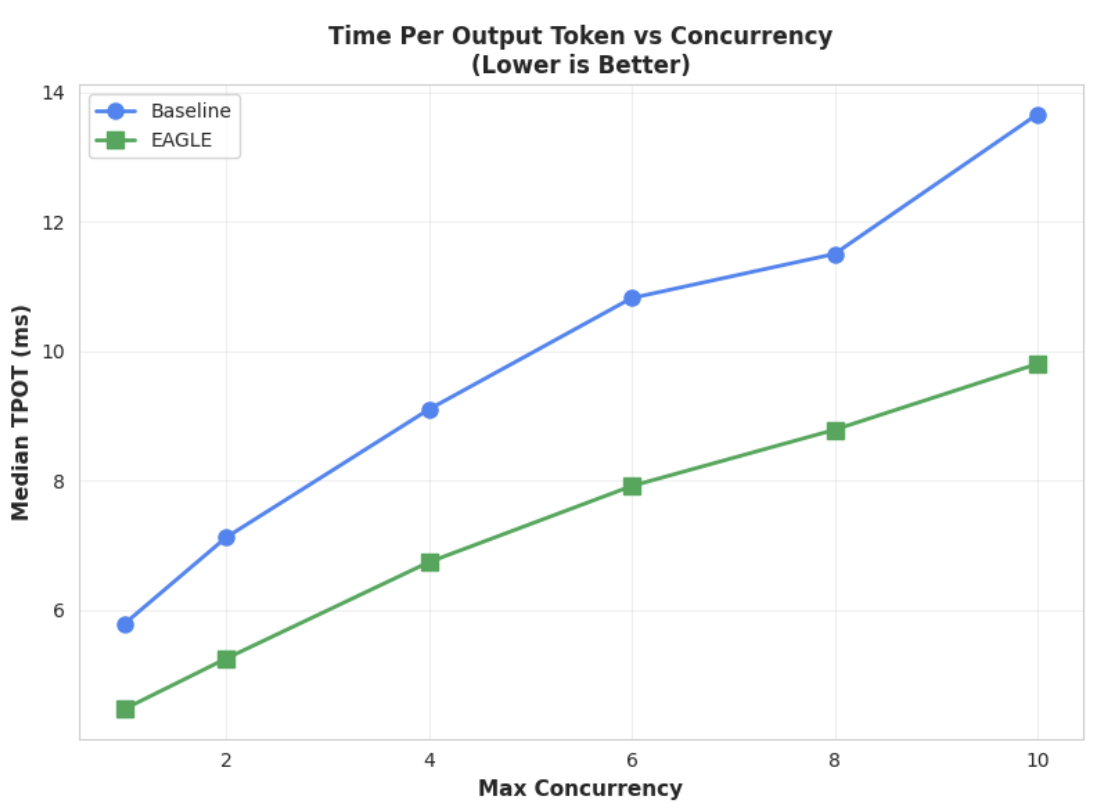
Haz clic para ampliar la imagen
En este gráfico se muestra la mejor latencia de EAGLE-3. El gráfico Tiempo por token de salida (TPOT) muestra que el modelo acelerado por EAGLE-3 (línea verde) consigue de forma constante una latencia inferior (más rápida) que la base de referencia (línea azul) en todos los niveles de simultaneidad probados.
Métrica 2: Rendimiento de salida
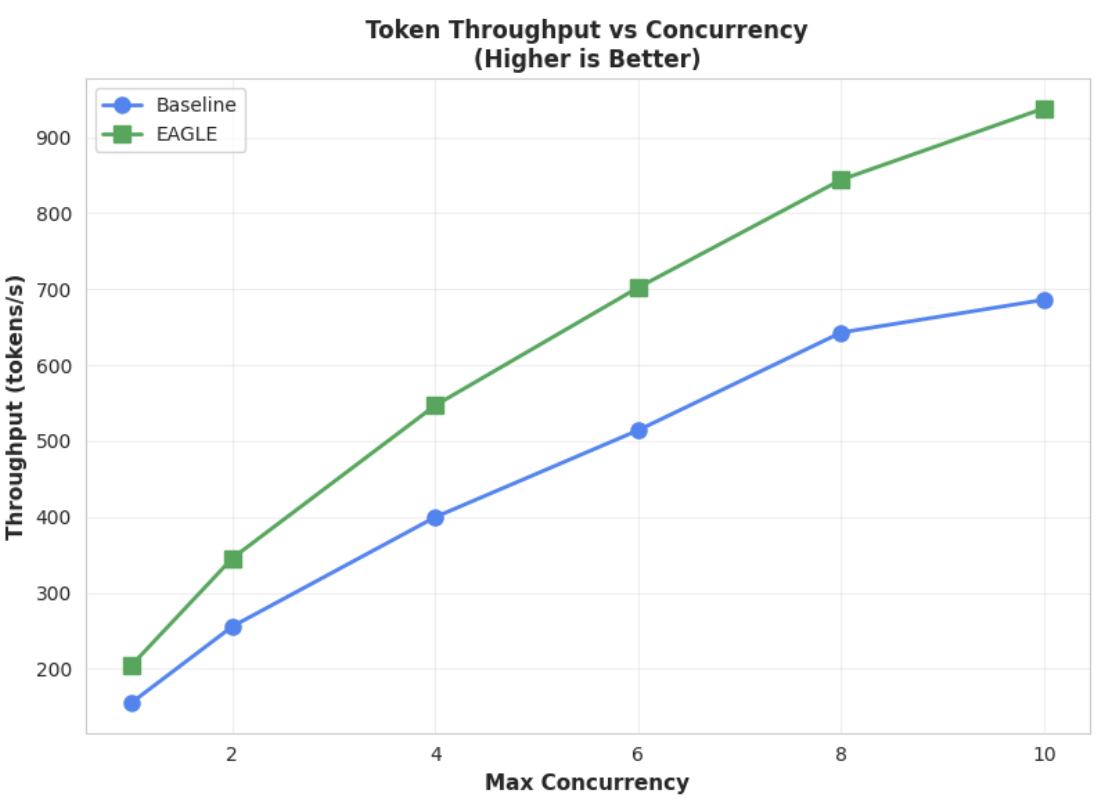
Haz clic para ampliar la imagen
Este gráfico destaca aún más la ventaja de EAGLE-3 en cuanto al rendimiento. El gráfico de latencia de tokens frente a simultaneidad muestra claramente que el modelo acelerado por EAGLE-3 (línea verde) supera de forma constante y sustancial al modelo de referencia (línea azul).
Aunque se pueden hacer observaciones similares en modelos más grandes, cabe destacar que se puede observar un aumento del tiempo hasta el primer token (TTFT) en comparación con otras métricas de rendimiento. Además, el rendimiento varía en función de la tarea, como se muestra en los siguientes ejemplos:
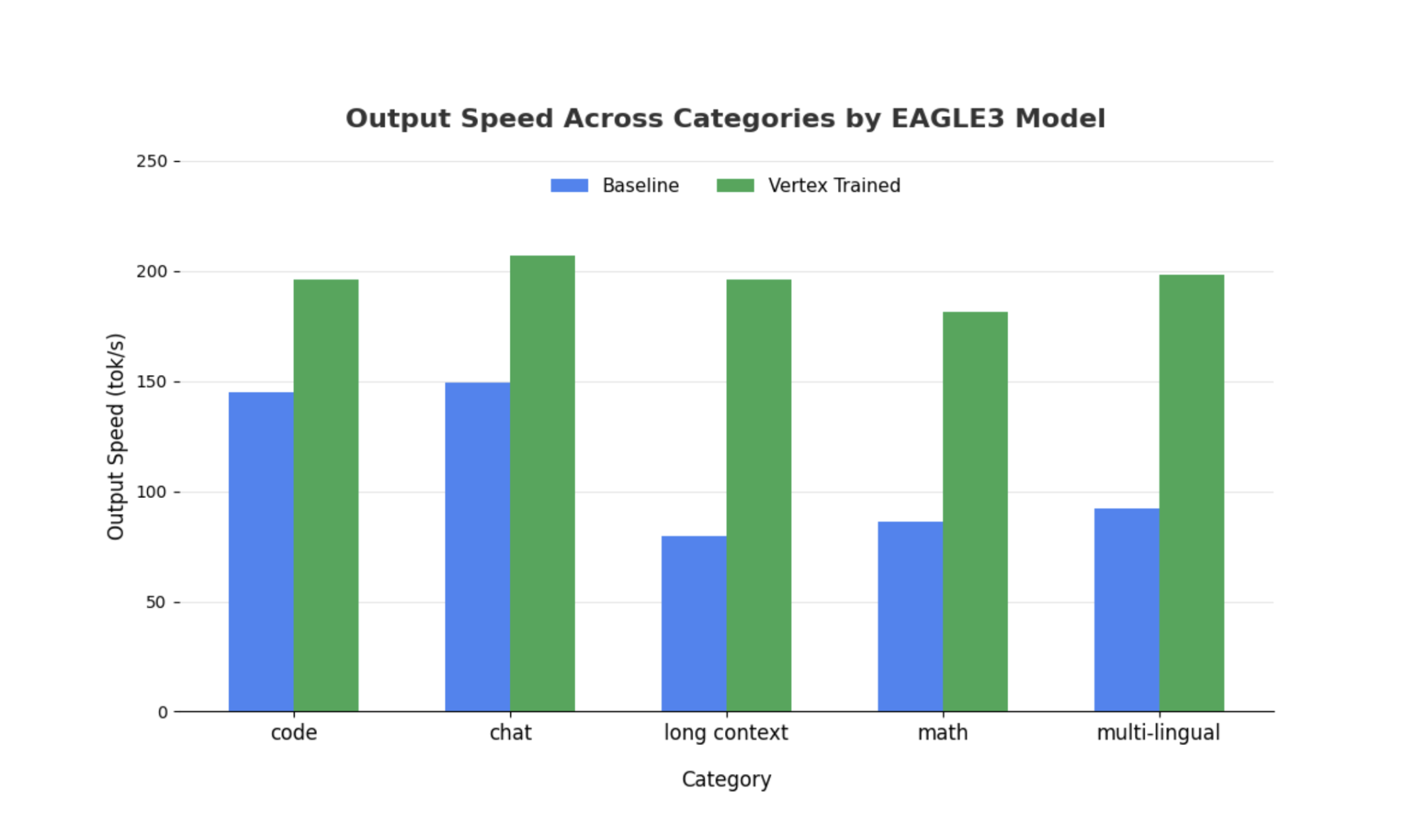
Haz clic para ampliar la imagen
Conclusión: ahora te toca a ti
EAGLE-3 no es solo un concepto de investigación, sino un patrón listo para producción que puede ofrecer una mejora tangible del doble de velocidad en la latencia de decodificación. Pero para que funcione a gran escala, se necesita un esfuerzo de ingeniería considerable. Para implementar esta tecnología de forma fiable para tus usuarios, debes hacer lo siguiente:
- Crea un flujo de procesamiento de datos sintéticos que cumpla los requisitos.
- Gestionar correctamente las plantillas de chat y las máscaras de pérdida, y entrenar el modelo con un conjunto de datos a gran escala.
En Vertex AI, ya hemos optimizado todo este proceso para ti, proporcionando un contenedor y una infraestructura optimizados diseñados para escalar tus aplicaciones basadas en LLMs. Para empezar, consulta los siguientes recursos:
Gracias por leer
Estaremos encantados de recibir tus comentarios y preguntas sobre Vertex AI.
Agradecimientos
Queremos expresar nuestro más sincero agradecimiento al equipo de SGLang, en concreto a Ying Sheng, Lianmin Zheng, Yineng Zhang, Xinyuan Tong y Liangsheng Yin, así como al equipo de SGLang/SpecForge, en concreto a Shenggui Li y Yikai Zhu, por su inestimable ayuda a lo largo de este proyecto. Su generosa ayuda y sus profundos conocimientos técnicos fueron fundamentales para el éxito de este proyecto.