

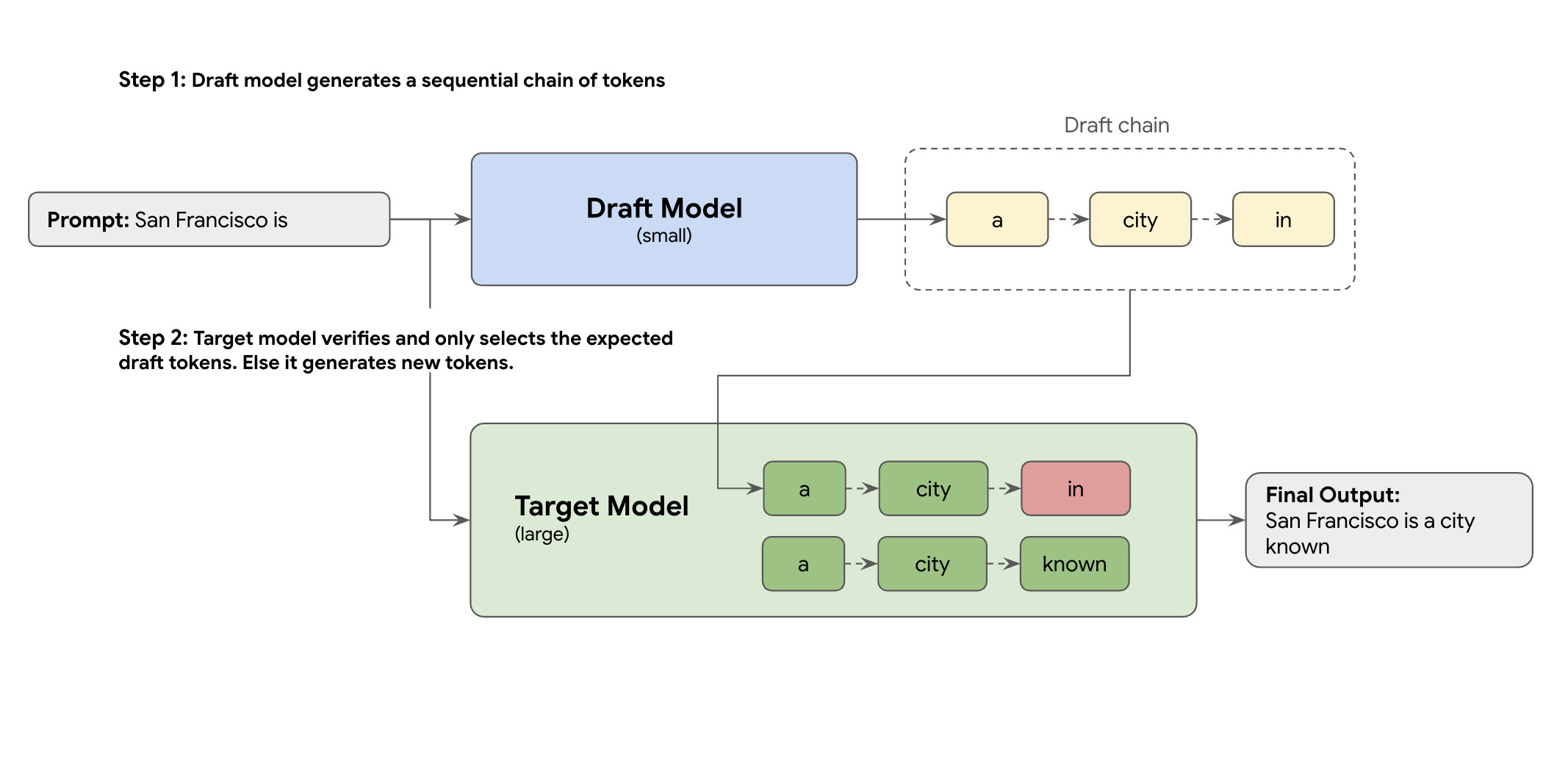
Die Lösung ist die spekulative Decodierung. Diese Optimierungstechnik beschleunigt den langsamen, sequenziellen Prozess, bei dem Ihr großes LLM (das Zielmodell) jeweils ein Token generiert, indem ein Entwurfsmechanismus eingeführt wird.
Mit diesem Mechanismus werden schnell mehrere nächste Tokens gleichzeitig vorgeschlagen. Das große Zielmodell überprüft diese Vorschläge dann in einem einzelnen, parallelen Batch. Es akzeptiert das längste übereinstimmende Präfix aus seinen eigenen Vorhersagen und setzt die Generierung ab diesem neuen Punkt fort.
Aber nicht alle Draft-Mechanismen sind gleich. Beim klassischen Ansatz mit Zielvorhaben für den Entwurf wird ein separates, kleineres LLM-Modell als Entwurfstool verwendet. Das bedeutet, dass Sie mehr Bereitstellungsressourcen hosten und verwalten müssen, was zusätzliche Kosten verursacht.
Zum Vergrößern des Bildes klicken
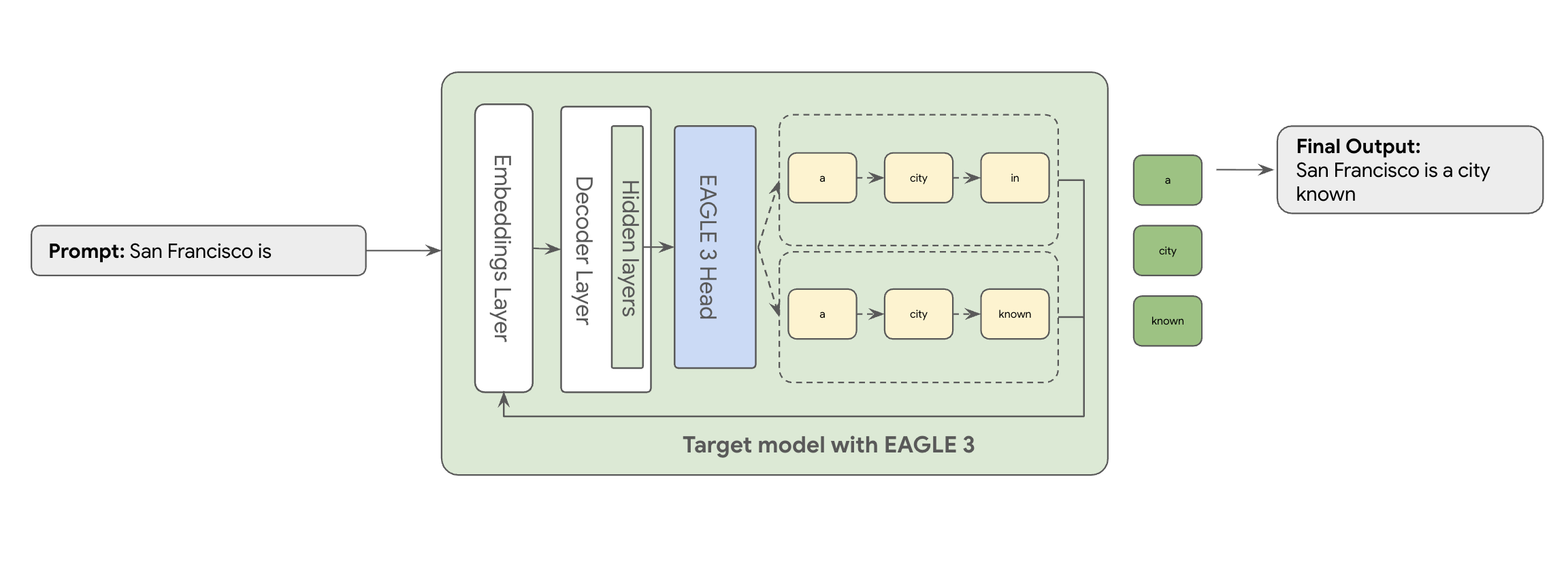
Hier kommt EAGLE-3 (Extrapolative Attention Guided LEarning) ins Spiel. EAGLE-3 ist ein komplexerer Ansatz. Statt eines völlig separaten Modells wird ein extrem kleiner „Draft-Head“ (nur 2–5% der Größe des Zielmodells) direkt an die internen Ebenen angehängt. Dieser Head arbeitet sowohl auf Feature- als auch auf Token-Ebene. Er nimmt Features aus den verborgenen Status des Zielmodells auf, um einen Baum zukünftiger Tokens zu extrapolieren und vorherzusagen.
Das Ergebnis: Alle Vorteile der spekulativen Dekodierung, ohne dass ein zweites Modell trainiert und ausgeführt werden muss.
Der Ansatz von EAGLE-3 ist viel effizienter als die komplexe, ressourcenintensive Aufgabe, ein separates Draft-Modell mit mehreren Milliarden Parametern zu trainieren und zu verwalten. Sie trainieren nur einen einfachen „Draft-Head“ mit 2% bis 5% der Größe des Zielmodells, der Ihrem vorhandenen Modell hinzugefügt wird. Dieser einfachere, effiziente Trainingsprozess führt zu einer erheblichen Steigerung der Decodierungsleistung um das 2- bis 3-Fache für Modelle wie Llama 70B (abhängig von den Arbeitslasttypen, z. B. Multi-Turn, Code, langer Kontext usw.).
Zum Vergrößern des Bildes klicken
Doch selbst die Übertragung dieses optimierten EAGLE-3-Ansatzes von einem Konzept zu einem skalierbaren, produktionsreifen Cloud-Dienst ist ein echter technischer Kraftakt. In diesem Beitrag stellen wir unsere technische Pipeline, die wichtigsten Herausforderungen und die hart erkämpften Erkenntnisse vor, die wir auf dem Weg dorthin gewonnen haben.
Herausforderung 1: Daten vorbereiten
Der EAGLE-3-Kopf muss trainiert werden. Der offensichtliche erste Schritt besteht darin, ein generisches, öffentlich verfügbares Dataset zu verwenden. Die meisten dieser Datasets sind mit Herausforderungen verbunden, darunter:
- Strenge Nutzungsbedingungen:Diese Datasets werden mit Modellen generiert, die nicht für die Entwicklung von Modellen verwendet werden dürfen, die mit den ursprünglichen Anbietern konkurrieren.
- Kontamination mit personenidentifizierbaren Informationen:Einige dieser Datasets enthalten erhebliche Mengen an personenidentifizierbaren Informationen, darunter Namen, Standorte und sogar Finanzkennungen.
- Keine Qualitätsgarantie:Einige Datasets eignen sich nur für allgemeine „Demo“-Anwendungsfälle, aber nicht für die speziellen Arbeitslasten echter Kunden.
Die Daten können nicht unverändert verwendet werden.
Lektion 1: Pipeline zur Generierung synthetischer Daten erstellen
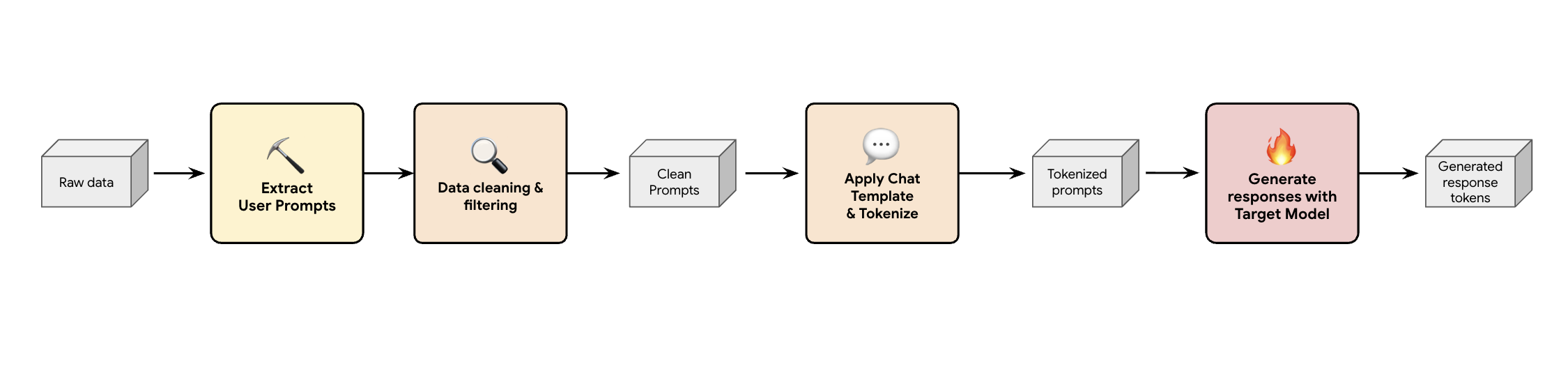
Eine Lösung besteht darin, eine Pipeline zur Generierung synthetischer Daten zu erstellen. Je nach Anwendungsfall des Kunden wählen wir das richtige Dataset aus, das nicht nur eine gute Qualität aufweist, sondern auch am besten zum Produktions-Traffic des Kunden für verschiedene Arbeitslasten passt. Anschließend können Sie nur die Nutzer-Prompts aus diesen Datasets extrahieren und strenge DLP- (Data Loss Prevention) und PII-Filterung (personenidentifizierbare Informationen) anwenden. Bei diesen bereinigten Prompts wird eine Chatvorlage angewendet, sie werden tokenisiert und können dann in Ihr Zielmodell eingegeben werden (z.B. Llama 3.3 70B) verwendet.
So werden zielgenerierte Daten bereitgestellt, die nicht nur konform und bereinigt sind, sondern auch gut mit der tatsächlichen Ausgabeverteilung des Modells übereinstimmen. Das ist ideal, um den Kopf des Entwurfs zu trainieren.
Zum Vergrößern des Bildes klicken
Herausforderung 2: Trainingspipeline entwickeln
Eine weitere wichtige Entscheidung ist, wie die Trainingsdaten für den EAGLE-3-Head bereitgestellt werden. Es gibt zwei verschiedene Ansätze: Online-Training, bei dem Einbettungen „on the fly“ generiert werden, und Offline-Training, bei dem Einbettungen vor dem Training generiert werden.
In unserem Fall haben wir uns für ein Offline-Training entschieden, da es viel weniger Hardware als das Online-Training erfordert. Bei diesem Prozess werden alle Merkmale und Einbettungen vorab berechnet, bevor wir den EAGLE-3-Head trainieren. Wir speichern sie in GCS und sie werden zu den Trainingsdaten für unseren einfachen EAGLE-3-Head. Sobald Sie die Daten haben, geht das Training selbst schnell. Angesichts der geringen Größe des EAGLE-3-Kopfes dauerte das erste Training mit unserem ursprünglichen Dataset auf einem einzelnen Host etwa einen Tag. Mit der Skalierung unseres Datensatzes haben sich die Trainingszeiten jedoch entsprechend verlängert und dauern nun mehrere Tage.

Zum Vergrößern des Bildes klicken
Dabei haben wir zwei wichtige Dinge gelernt, die Sie im Hinterkopf behalten sollten.
Lektion 2: Chatvorlagen sind nicht optional
Beim Trainieren des anweisungsabgestimmten Modells haben wir festgestellt, dass die Leistung von EAGLE-3 stark variieren kann, wenn die Chatvorlage nicht richtig ist. Sie müssen die spezifische Chatvorlage des Zielmodells anwenden (z.B. Llama 3) bevor Sie die Funktionen und Einbettungen generieren. Wenn Sie nur Rohtext verketten, sind die Einbettungen falsch und der Head lernt, die falsche Verteilung vorherzusagen.
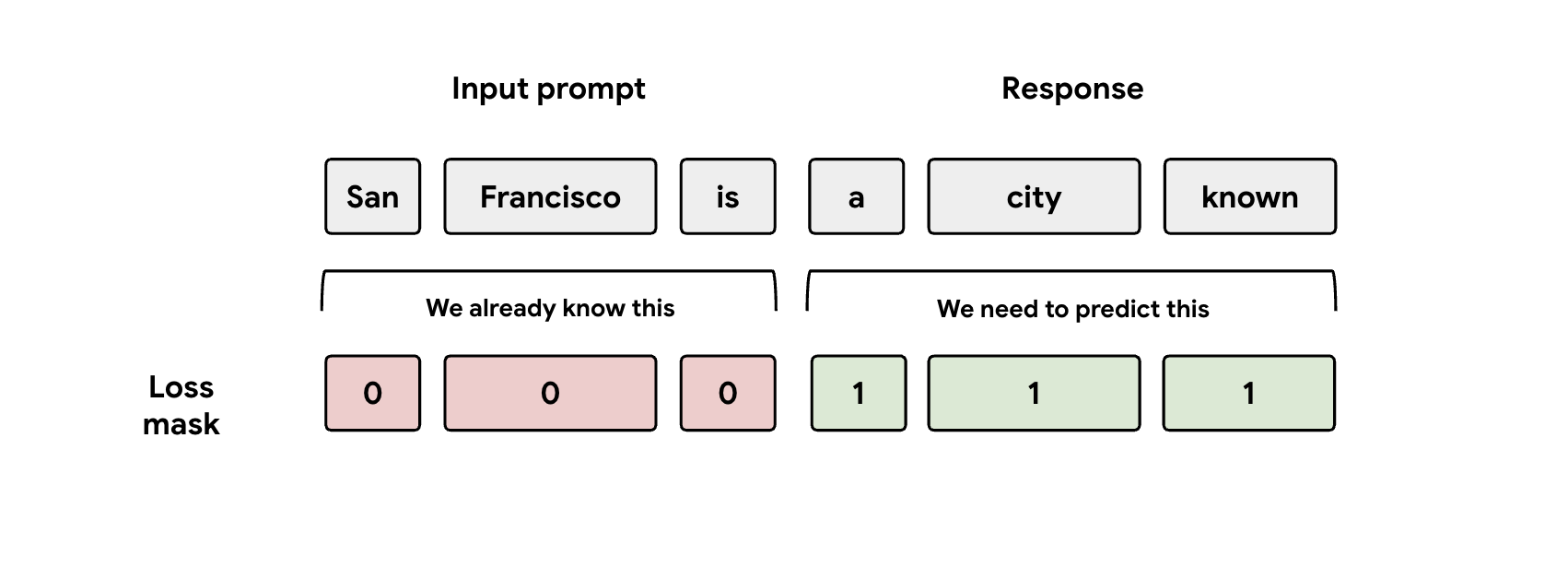
Lektion 3: Maske beachten
Während des Trainings werden dem Modell sowohl die Prompt- als auch die Antwortdarstellungen zugeführt. Der EAGLE-3-Head sollte jedoch nur lernen, die Antwort-Darstellung vorherzusagen. Sie müssen den Prompt-Teil in Ihrer Verlustfunktion manuell maskieren. Wenn Sie das nicht tun, verschwendet der Head Kapazität, um den Prompt vorherzusagen, den er bereits erhalten hat, und die Leistung leidet.
Zum Vergrößern des Bildes klicken
Herausforderung 3: Bereitstellung und Skalierung
Nachdem wir einen trainierten EAGLE-3-Head hatten, konnten wir mit der Bereitstellungsphase fortfahren. In dieser Phase traten erhebliche Skalierungsprobleme auf. Hier sind die wichtigsten Erkenntnisse.
Lektion 4: Das Bereitstellungs-Framework ist entscheidend
Durch die enge Zusammenarbeit mit dem SGLang-Team konnten wir EAGLE-3 erfolgreich in die Produktion überführen und dabei die bestmögliche Leistung erzielen. Der technische Grund dafür ist, dass in SGLang ein wichtiger Kernel für die Aufmerksamkeit von Entscheidungsbäumen implementiert ist. Dieser spezielle Kernel ist von entscheidender Bedeutung, da EAGLE-3 einen „Entwurfsbaum“ mit Möglichkeiten (nicht nur eine einfache Kette) generiert und der Kernel von SGLang speziell dafür entwickelt wurde, alle diese Verzweigungspfade parallel in einem einzigen Schritt zu überprüfen. Andernfalls schöpfen Sie das Leistungspotenzial nicht voll aus.
Lektion 5: CPU-Engpässe bei der GPU vermeiden
Auch nachdem Sie Ihr LLM mit EAGLE-3 beschleunigt haben, kann es zu einem weiteren Leistungsengpass kommen: der CPU. Wenn Ihre GPUs LLM-Inferenz ausführen, verschwendet nicht optimierte Software viel Zeit mit CPU-Overhead, z. B. mit dem Starten von Kernels und der Verwaltung von Metadaten. In einem normalen synchronen Scheduler führt die GPU einen Schritt (z. B. Entwurf) aus und wartet dann, während die CPU ihre Buchhaltung durchführt und den nächsten Schritt Bestätigen startet. Diese Synchronisierungsblasen summieren sich und verschwenden enorme Mengen an wertvoller GPU-Zeit.

Zum Vergrößern des Bildes klicken
Wir haben das Problem mit dem Zero-Overhead Overlap Scheduler von SGLang gelöst. Dieser Scheduler ist speziell auf den mehrstufigen Workflow Entwurf –> Bestätigen –> Entwurf erweitern von Speculative Decoding abgestimmt . Der Schlüssel ist, die Berechnung zu überlappen. Während die GPU mit dem aktuellen Verify-Schritt beschäftigt ist, startet die CPU parallel dazu bereits die Kernel für die nächsten Schritte Draft und Draft Extend .
Dadurch wird die Leerlaufblase eliminiert, da der nächste Job der GPU immer bereit ist. Dazu wird eine FutureMap verwendet, eine intelligente Datenstruktur, mit der die CPU den nächsten Batch vorbereiten kann, WÄHREND die GPU noch arbeitet.

Zum Vergrößern des Bildes klicken
Durch die Eliminierung dieses CPU-Overheads bietet der Überschneidungsplaner eine zusätzliche Beschleunigung von 10 % bis 20%. Das zeigt, dass ein gutes Modell nur die halbe Miete ist. Sie benötigen auch eine Laufzeit, die mithalten kann.
Benchmark-Ergebnisse
Hat sich die Reise gelohnt? Selbstverständlich.
Wir haben unseren trainierten EAGLE-3-Head mit SGLang und Llama 4 Scout 17B Instruct mit der nicht spekulativen Baseline verglichen. Unsere Benchmarks zeigen je nach Art der Arbeitslast eine 2- bis 3-fache Beschleunigung der Decodierungslatenz und einen erheblichen Durchsatzgewinn.
Alle Details und die Möglichkeit, den Benchmark selbst auszuführen, finden Sie in unserem umfassenden Notebook.
Messwert 1: Medianwert für die Zeit pro Ausgabetoken (TPOT)
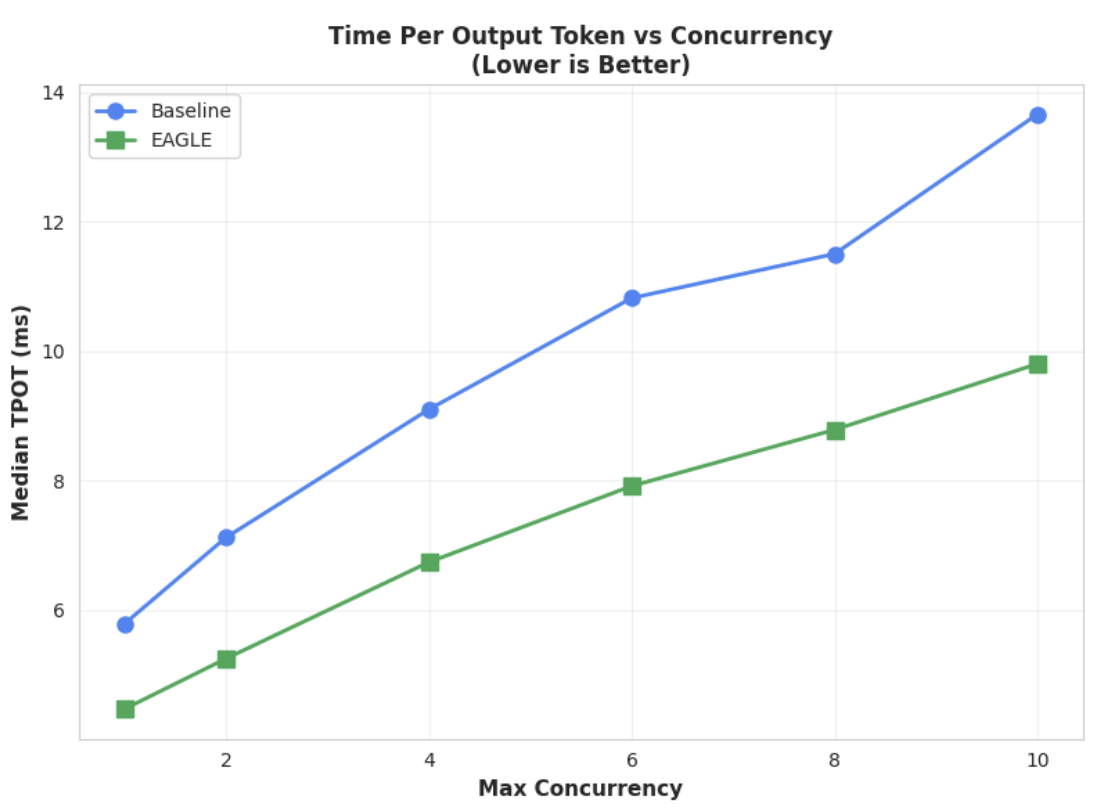
Zum Vergrößern des Bildes klicken
In diesem Diagramm ist die bessere Latenzleistung von EAGLE-3 zu sehen. Das Diagramm „Zeit pro Ausgabetoken (TPOT)“ zeigt, dass das EAGLE-3-beschleunigte Modell (grüne Linie) bei allen getesteten Parallelitätsstufen eine durchgehend niedrigere (schnellere) Latenz als die Baseline (blaue Linie) erreicht.
Messwert 2: Ausgabedurchsatz
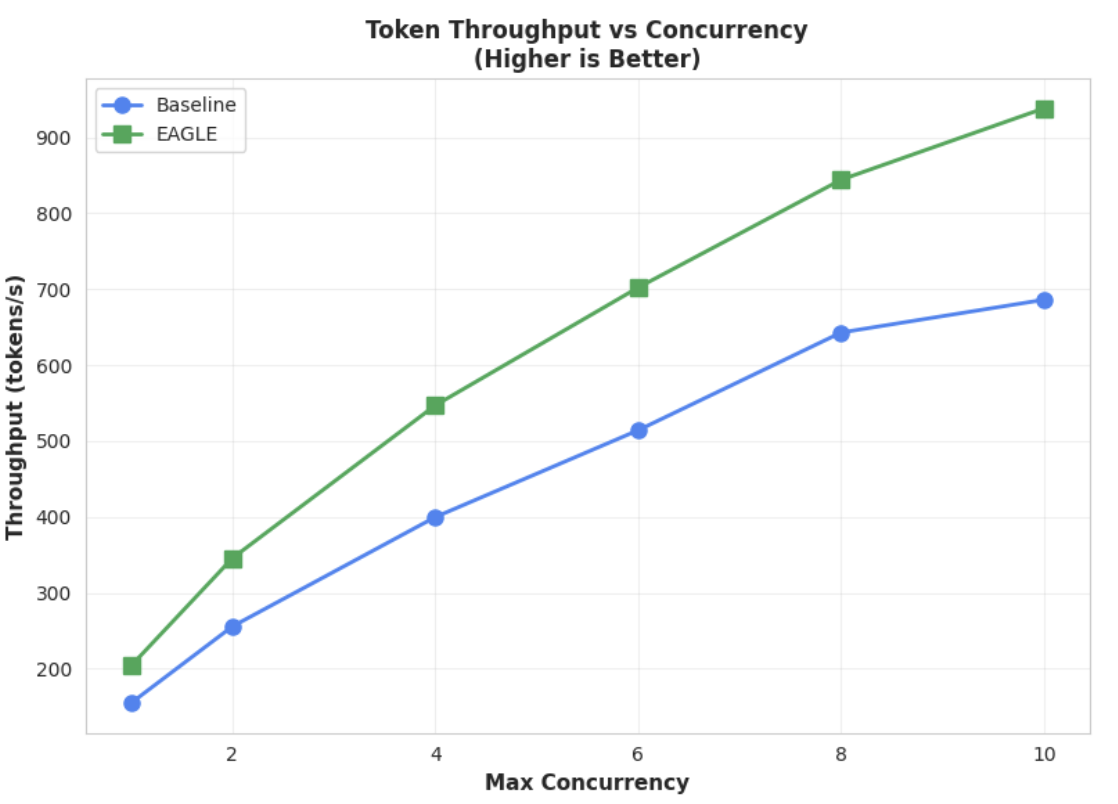
Zum Vergrößern des Bildes klicken
Dieses Diagramm verdeutlicht den Durchsatzvorteil von EAGLE-3. Das Diagramm „Token-Durchsatz im Vergleich zur Parallelität“ zeigt deutlich, dass das EAGLE-3-beschleunigte Modell (grüne Linie) das Baseline-Modell (blaue Linie) durchweg und erheblich übertrifft.
Ähnliche Beobachtungen gelten auch für größere Modelle. Es ist jedoch erwähnenswert, dass im Vergleich zu anderen Leistungsmesswerten eine Zunahme der Zeit bis zum ersten Token (Time to First Token, TTFT) beobachtet werden kann. Die Leistung variiert auch je nach Aufgabe, wie in den folgenden Beispielen veranschaulicht:
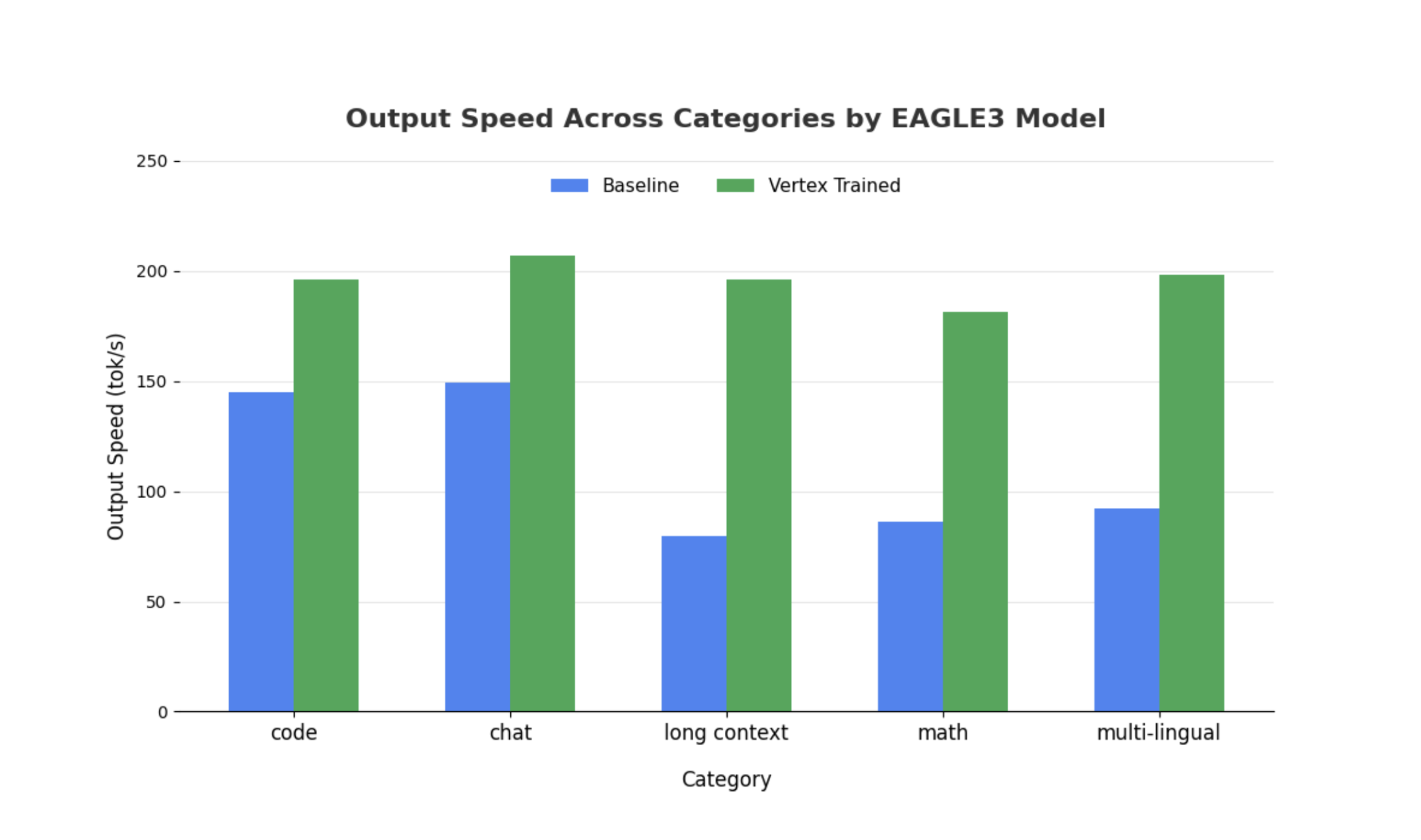
Zum Vergrößern des Bildes klicken
Fazit: Jetzt sind Sie an der Reihe
EAGLE-3 ist nicht nur ein Forschungskonzept, sondern ein produktionsreifes Muster, das eine spürbare Verdopplung der Decodierungs-Latenz ermöglicht. Damit es skaliert werden kann, ist jedoch ein erheblicher technischer Aufwand erforderlich. Damit Sie diese Technologie zuverlässig für Ihre Nutzer bereitstellen können, müssen Sie Folgendes tun:
- Erstellen Sie eine konforme Pipeline für synthetische Daten.
- Chatvorlagen und Verlustmasken richtig verarbeiten und das Modell mit einem großen Dataset trainieren.
In Vertex AI haben wir diesen gesamten Prozess bereits für Sie optimiert und bieten einen optimierten Container und eine Infrastruktur, die für die Skalierung Ihrer LLM-basierten Anwendungen entwickelt wurden. Weitere Informationen finden Sie in den folgenden Ressourcen:
Vielen Dank für Ihr Interesse
Wir freuen uns auf Ihr Feedback und Ihre Fragen zu Vertex AI.
Danksagungen
Wir möchten dem SGLang-Team, insbesondere Ying Sheng, Lianmin Zheng, Yineng Zhang, Xinyuan Tong und Liangsheng Yin, sowie dem SGLang/SpecForge-Team, insbesondere Shenggui Li und Yikai Zhu, für ihre unschätzbare Unterstützung bei diesem Projekt danken. Ihre großzügige Unterstützung und ihr tiefes technisches Wissen waren entscheidend für den Erfolg dieses Projekts.