
TPU7x (Ironwood)
Esta página descreve a arquitetura e as configurações disponíveis para o TPU7x, a mais recente TPU disponível em Google Cloud. A TPU7x é a primeira versão da família Ironwood,a TPU de sétima geração do Google Cloud. A geração Ironwood foi projetada para treinamento e inferência de IA em grande escala.
Com 9.216 chips por pod, a TPU7x compartilha muitas semelhanças com a TPU v5p. A TPU7x oferece alto desempenho para modelos densos e MoE em grande escala, pré-treinamento, amostragem e inferência com decodificação pesada.
Para usar a TPU7x, use o Google Kubernetes Engine (GKE) ou o Compute Engine. Para mais informações sobre o uso de TPUs com o GKE, consulte Sobre TPUs no GKE.
Também é possível usar o TPU7x e o GKE com o TPU Cluster Director. O TPU Cluster Director está disponível por uma reserva de modo "Toda a capacidade", que oferece acesso total a toda a capacidade reservada (sem retenções) e visibilidade completa da topologia de hardware, do status de utilização e da integridade da TPU. Para mais informações, consulte Visão geral do modo de capacidade completo.
Arquitetura do sistema
Cada chip da TPU7x contém dois TensorCores e quatro SparseCores. A tabela a seguir mostra as principais especificações e os valores da TPU7x em comparação com as gerações anteriores.
| Especificação | v5p | v6e (Trillium) | TPU7x (Ironwood) |
|---|---|---|---|
| Número de chips por pod | 8960 | 256 | 9216 |
| Pico de computação por chip (BF16) (TFLOPs) | 459 | 918 | 2307 |
| Pico de computação por chip (FP8) (TFLOPs) | 459 | 918 | 4614 |
| Capacidade de HBM por chip (GiB) | 95 | 32 | 192 |
| Largura de banda de HBM por chip (GiBps) | 2575 | 1638 | 7380 |
| Número de vCPUs (VM de 4 chips) | 208 | 180 | 224 |
| RAM (GB) (VM de quatro chips) | 448 | 720 | 960 |
| Número de TensorCores por chip | 2 | 1 | 2 |
| Número de SparseCores por chip | 4 | 2 | 4 |
| Largura de banda bidirecional da interconexão entre chips (ICI) por chip (GBps) | 1200 | 800 | 1200 |
| Largura de banda da rede do data center (DCN) por chip (Gbps) | 50 | 100 | 100 |
O diagrama a seguir ilustra a arquitetura do Ironwood:
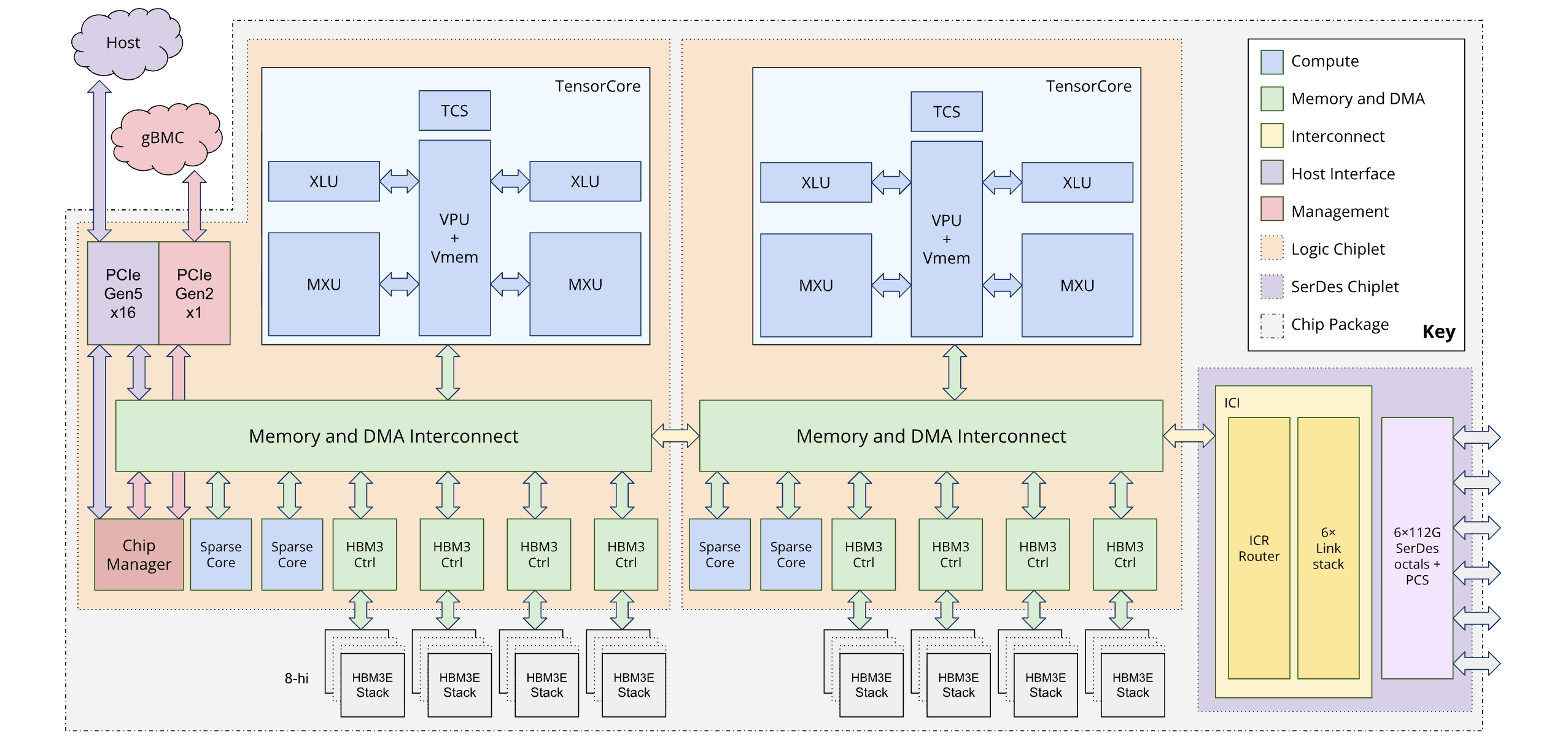
Hierarquia de memória
A TPUv7 tem um sistema de memória de vários níveis, e o gerenciamento da movimentação de dados entre esses níveis é fundamental para o desempenho:
- Memória de alta largura de banda (HBM): cada chip é equipado com 192 GB de HBM, com largura de banda de aproximadamente 7,37 TB/s. A grande capacidade de HBM permite tamanhos de lote grandes, o que pode melhorar a capacidade de processamento. No entanto, apesar do tamanho, a HBM ainda pode ser um gargalo, principalmente para operações de vetor vinculadas à memória ou padrões de acesso aos dados ineficientes.
- Memória vetorial (VMEM): a VMEM é uma SRAM (memória estática de acesso aleatório) menor e no chip com largura de banda significativamente maior para a unidade de multiplicação de matrizes (MXU) do que a HBM. Essa memória funciona como um bloco de rascunho de alta velocidade para kernels personalizados. O tamanho desse buffer é um parâmetro ajustável. A otimização do tamanho do buffer é fundamental para ajustar os kernels personalizados do Pallas, já que os tamanhos de bloco costumam ser limitados pela VMEM disponível.
- Memória do host e PCIe:cada conjunto de quatro chips de TPU está conectado a um host de CPU usando uma rede PCIe. Embora essa conexão tenha uma largura de banda muito menor do que a HBM, a memória principal do host pode ser usada para descarregar ativações ou estados do otimizador para liberar a HBM, uma técnica particularmente útil para gerenciar a pressão da memória em modelos grandes.
Para saber mais sobre como gerenciar com eficiência a movimentação de dados entre os níveis da hierarquia de memória TPU7x, consulte Otimizações de desempenho do Ironwood.
Arquitetura de dois chiplets
O modelo de programação Ironwood permite acessar dois chiplets de TPU em vez de uma arquitetura de núcleo lógico único (também conhecida como MegaCore) usada em gerações anteriores (TPU v4 e v5p). Essa mudança melhora a relação custo-benefício e a eficiência da fabricação do chip. Embora isso represente uma mudança arquitetônica, o novo design garante que você possa reutilizar modelos de software atuais com mudanças mínimas.
As TPUs Ironwood são compostas por dois chiplets distintos, cada um com seu próprio espaço de memória dedicado. Isso é diferente do espaço de memória unificado da arquitetura MegaCore.
Composição do chiplet: cada chiplet é uma unidade independente com um TensorCore, dois SparseCores e 96 GB de memória de alta largura de banda (HBM).
Interconexão de alta velocidade: os dois chiplets são conectados por uma interface de matriz para matriz (D2D) seis vezes mais rápida do que um link de interconexão entre chips (ICI) 1D. A comunicação entre chiplets é gerenciada usando operações coletivas.
Exposição a modelos e frameworks de programação
O modelo de programação do Ironwood é semelhante ao das gerações de TPU anteriores à v4, como a TPU v3. A nova arquitetura é exposta das seguintes maneiras:
Dois dispositivos por chip:frameworks como o JAX expõem cada chip Ironwood como dois "dispositivos" separados, um para cada chiplet.
Especificação de chiplet:é possível especificar qual chiplet usar para um cálculo. O JAX adiciona uma quarta dimensão à especificação de topologia para distinguir entre chiplets. Esse design permite reutilizar modelos de software com mudanças mínimas.
Para mais informações sobre como alcançar o desempenho ideal com a arquitetura de chiplet duplo, consulte Recomendações de desempenho para a arquitetura de chiplet duplo do Ironwood.
Configurações aceitas
Os chips TPU7x têm uma conexão direta com os chips vizinhos mais próximos em três dimensões, o que resulta em uma malha 3D de conexões de rede. Fatias maiores que 64 chips são compostas por um ou mais "cubos" de chips de 4x4x4.
Os chips TPU7x têm uma topologia de interconexão de torus 3D. Essa topologia permite que as frações sejam escalonar verticalmente verticalmente para até 9.216 chips. Ela tem largura de banda bidirecional de 200 GBps por eixo para comunicação entre chips em um pod.
A tabela abaixo mostra as formas de fração 3D comuns disponíveis na TPU7x:
| Topologia | Chips de TPU | Hosts | VMs | Cubos | Escopo |
|---|---|---|---|---|---|
| 2x2x1 | 4 | 1 | 1 | 1/16 | Host único |
| 2x2x2 | 8 | 2 | 2 | 1/8 | Vários hosts |
| 2x2x4 | 16 | 4 | 4 | 1/4 | Vários hosts |
| 2x4x4 | 32 | 8 | 8 | 1/2 | Vários hosts |
| 4x4x4 | 64 | 16 | 16 | 1 | Vários hosts |
| 4x4x8 | 128 | 32 | 32 | 2 | Vários hosts |
| 4x8x8 | 256 | 64 | 64 | 4 | Vários hosts |
| 8x8x8 | 512 | 128 | 128 | 8 | Vários hosts |
| 8x8x16 | 1024 | 256 | 256 | 16 | Vários hosts |
| 8x16x16 | 2048 | 512 | 512 | 32 | Vários hosts |
VM TPU7x
Cada máquina virtual (VM) TPU7x contém quatro chips. Cada VM tem acesso a dois nós NUMA. Para mais informações sobre nós NUMA, consulte Acesso à memória não uniforme na Wikipédia.
Todas as frações de TPU7x usam VMs de host completo com quatro chips. As especificações técnicas de uma VM TPU7x são:
- Número de vCPUs por VM: 224
- RAM por VM: 960 GB
- Número de nós NUMA por VM: 2
Hyperdisk
Por padrão, o disco de inicialização da VM para TPU7x é o Hyperdisk Balanced. É possível anexar mais discos à VM de TPU para ter mais armazenamento. Os seguintes tipos de disco são compatíveis com TPU7x:
- Hiperdisco equilibrado
- Hyperdisk ML
Para mais informações sobre o Hyperdisk, consulte Visão geral do Hyperdisk. Para mais informações sobre opções de armazenamento para o Cloud TPU, consulte Opções de armazenamento para dados do Cloud TPU.
A seguir
- Usar TPU7x com o GKE
- Usar TPU7x com o TPU Cluster Director
- Use a plataforma Google Cloud ML Diagnostics para otimizar e diagnosticar suas cargas de trabalho
- Executar uma carga de trabalho de treinamento usando uma receita otimizada para TPU7x
- Executar uma microcomparação de TPU7x
- Otimizações de desempenho do Ironwood
- Treinar modelos de machine learning em larga escala no GKE com o checkpointing de vários níveis