
このドキュメントでは、SQL クエリを発行する Observability Analytics のクエリ結果をグラフ化する方法について説明します。SQL を使用してログデータとトレースデータを分析すると、パターンと傾向を特定できます。クエリ結果は表として表示するか、グラフを作成して可視化できます。グラフをカスタム ダッシュボードに保存することもできます。
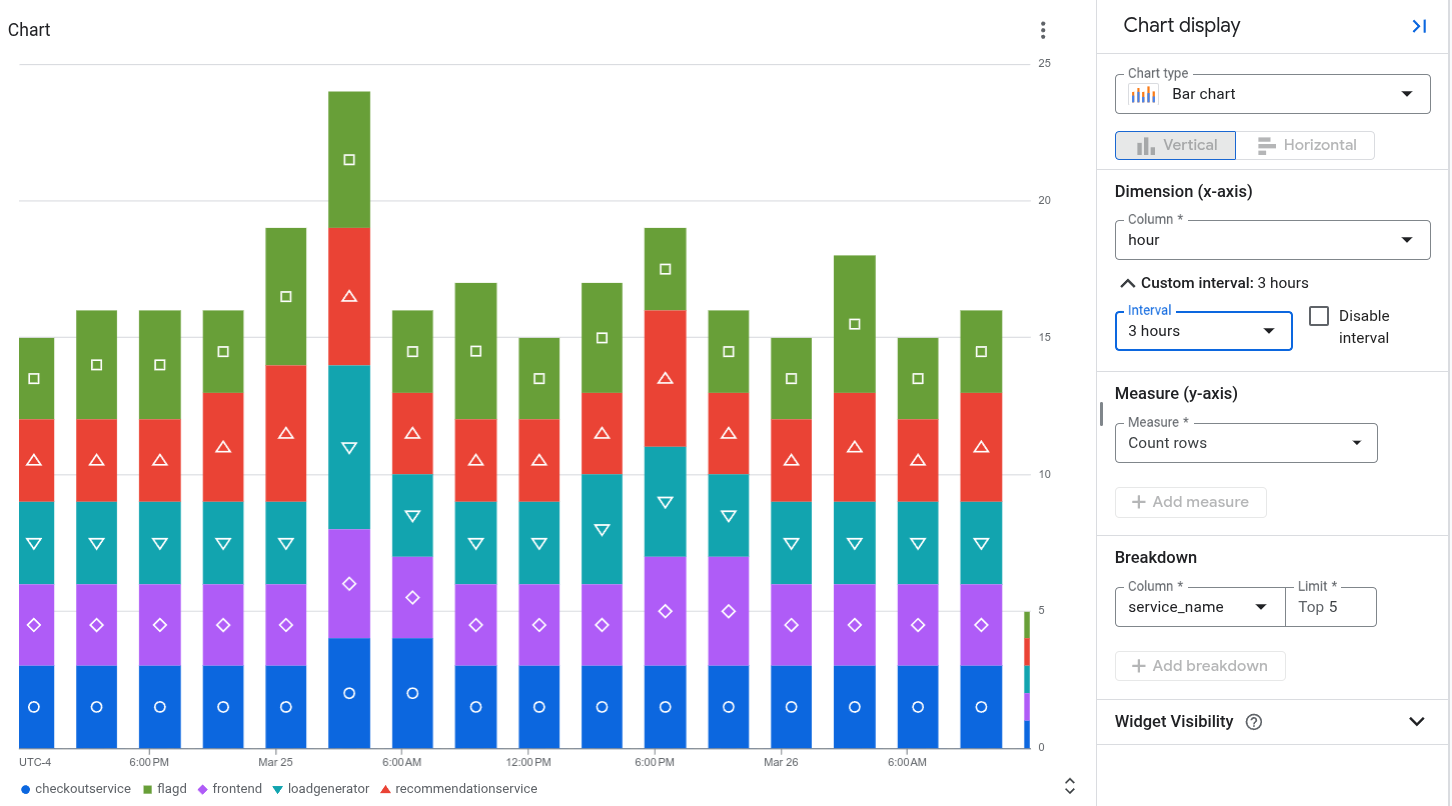
次のスクリーンショットは、このドキュメントの後半で説明するトレースのサンプルクエリの結果を示しています。スクリーンショットには、レスポンスを時間と service_name で集計した後に、スパンによって報告されたステータスが表示されます。
始める前に
- Google Cloud アカウントにログインします。 Google Cloudを初めて使用する場合は、 アカウントを作成して、実際のシナリオでの Google プロダクトのパフォーマンスを評価してください。新規のお客様には、ワークロードの実行、テスト、デプロイができる無料クレジット $300 分を差し上げます。
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Observability API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Observability API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
[オブザーバビリティ分析] ページの読み込み、ログデータとトレースデータに対するクエリの作成と実行、カスタム ダッシュボードへのグラフの保存に必要な権限を取得するには、次の IAM ロールを付与するよう管理者に依頼してください。
- プロジェクトに対するモニタリング編集者(
roles/monitoring.editor) - クエリを実行するオブザーバビリティ ビューに対するオブザーバビリティ ビュー アクセサー (
roles/observability.viewAccessor)。このロールは IAM 条件をサポートしています。これにより、付与を特定のビューに制限できます。ロール付与に条件を適用しない場合、プリンシパルはすべてのオブザーバビリティ ビューにアクセスできます。オブザーバビリティ ビューはパブリック プレビュー版です。 - プロジェクトに対するログビューア(
roles/logging.viewer) - クエリするログビューを保存するプロジェクトに対するログ表示アクセス者 (
roles/logging.viewAccessor)。
ロールの付与については、プロジェクト、フォルダ、組織へのアクセス権の管理をご覧ください。
- プロジェクトに対するモニタリング編集者(
グラフ化するデータを選択する
グラフに表示するデータを構成するには、SQL を使用してクエリを作成します。 [グラフ] タブを選択すると、クエリの結果がグラフに表示されます。クエリが実行され、グラフが生成されたら、グラフの種類を変更し、別のデータを表示するための列を選択して、グラフの構成をカスタマイズできます。
クエリの結果をグラフとして表示するには、次のようにします。
-
Google Cloud コンソールで、manage_search [オブザーバビリティ分析] ページに移動します。
検索バーを使用してこのページを検索する場合は、小見出しが [Logging] の結果を選択します。
[クエリ] ペインにクエリを入力して、[実行] をクリックします。
クエリが完了したら、[結果] タブでクエリ結果の表示方法を選択します。
表: 表形式のみ。
グラフ: グラフ形式のみ
両方: グラフと表形式。
クエリ結果の表示方法を選択したら、選択した可視化のフィールドを構成し、クエリと結果をカスタム ダッシュボードに保存できます。[表] オプションを選択した場合、保存される形式は表形式になります。それ以外の場合は、グラフ形式になります。
グラフの場合、可視化オプションを使用してグラフの種類を選択し、グラフ化する行と列を選択できます。グラフ構成の詳細については、グラフの構成をカスタマイズするをご覧ください。
グラフの構成をカスタマイズする
グラフの構成をカスタマイズするには、グラフの種類を変更して、グラフにディメンションとメジャーを選択し、内訳を適用します。ディメンションは、行をグループ化または分類するために使用される、X 軸の値です。メジャーまたは Y 軸の値は、Y 軸に対してプロットされるデータ系列です。
グラフの種類を変更する
ディメンションとメジャーとして選択した行と列の種類、データ可視化する方法に応じて、次のグラフの種類から選択できます。
棒グラフ(デフォルト): 棒グラフでは、2 つの軸でデータをプロットします。グラフでカテゴリまたは文字列をディメンションとして使用する場合、棒グラフのグラフ構成は水平方向または垂直方向に設定できます(ディメンションとメジャーの軸が入れ替わります)。
折れ線グラフ: 折れ線グラフを使用すると、経時的なデータの変化を示すことができます。折れ線グラフを使用する場合、各時系列は選択したメジャーに対応する異なる線で示されます。
X 軸が時間ベースの場合、各データポイントは期間の開始位置に配置されます。各データポイントは線形補間によって接続されています。
積み上げ面グラフ: 面グラフは折れ線グラフに基づいており、各線の下の領域は網掛けされます。面グラフでは、データ系列が積み上げられます。たとえば、2 つの同一の系列が折れ線グラフで重複する場合、網掛けされた領域は面グラフで積み重ねられます。
円グラフまたはドーナツグラフ: 円グラフは、データセット全体に対するデータセット内のカテゴリの割合を示します。円はデータセット全体を表し、円の中の扇形はデータセット内のカテゴリを表します。扇形のサイズは、カテゴリが全体に占める割合を示します。
表: 表には、クエリ結果の行ごとに 1 行が表示されます。表の列は
SELECT句で定義されます。ダッシュボードにデータを表形式で表示する場合は、LIMIT句を使用して、結果の行数を数百未満に制限します。ゲージまたはスコアカード: ゲージとスコアカードには、最新の値と、その値と一連のしきい値の差に基づいて緑、黄色、赤のインジケーターが表示されます。最新の値に関する情報のみを表示するゲージとは異なり、スコアカードには過去の値に関する情報も含めることができます。
ゲージとスコアカードにクエリ結果を表示できるのは、クエリ結果に少なくとも 1 つの行が含まれ、その行にタイムスタンプを含む列と数値データを含む列が存在している場合のみです。クエリ結果には、複数の行と 2 つ以上の列を含めることができます。
クエリの一部として時間ベースの集計を実行する場合は、次の操作を行います。
期間にわたってデータを集計し、結果をタイムスタンプが降順になるように並べ替え、結果の行数を制限するようにクエリを構成します。
LIMIT句を使用するか、期間セレクタを使用して、クエリ結果の行数を制限できます。ログデータ
たとえば、次のクエリはログビューに対して実行され、データが時間単位で集計され、上限が適用され、結果が並べ替えられます。
SELECT TIMESTAMP_TRUNC(timestamp, HOUR) AS hour, severity, COUNT(*) AS count FROM `PROJECT_ID.LOCATION.BUCKET_ID.LOG_VIEW_ID` WHERE severity IS NOT NULL AND severity = "DEFAULT" GROUP BY hour,severity ORDER BY hour DESC LIMIT 10
前の式のフィールドの意味は次のとおりです。
- PROJECT_ID: プロジェクトの ID。
- LOCATION: ログビューまたは分析ビューのロケーション。
- BUCKET_ID: ログバケットの名前または ID。
- LOG_VIEW_ID: ログビューの ID。100 文字に制限され、英字、数字、アンダースコア、ハイフンのみを使用できます。
トレースデータ
たとえば、次のクエリはトレースデータをクエリし、1 時間間隔でデータを集計し、上限を適用して、結果を並べ替えます。
SELECT TIMESTAMP_TRUNC(start_time, HOUR) AS hour, COALESCE( JSON_VALUE(resource.attributes, '$."service.name"'), JSON_VALUE(attributes, '$."service.name"'), JSON_VALUE(attributes, '$."g.co/gae/app/module"')) AS service_name, status.code AS status, COUNT(*) AS count FROM `PROJECT_ID.LOCATION._Trace.Spans._AllSpans` GROUP BY hour, service_name, status ORDER BY hour DESC LIMIT 1000
前の式のフィールドの意味は次のとおりです。
- PROJECT_ID: プロジェクトの ID。
- LOCATION: オブザーバビリティ バケットのロケーション。
前のクエリは、このドキュメントの冒頭に示されている図を生成するために使用されました。この図には、グラフの構成も示されています。
時間単位を報告する列と一致するようにディメンションを設定します。たとえば、クエリで 1 時間ごとにデータを集計し、
hourという名前の列を作成する場合、[ディメンション] メニューをhourに設定します。クエリで集計間隔がすでに指定されているため、[Disable interval] を選択します。この例では、間隔は 1 時間です。
[メジャー] を数値列に設定し、関数を [なし] に設定します。
オブザーバビリティ分析を使用して時間ベースの集計を実行する場合は、次の操作を行います。
- 期間セレクタを構成します。これは、クエリ結果の行数に影響します。
- 時間単位を報告する列と一致するようにディメンションを設定します。たとえば、このメニューを
timestampに設定できます。 - [間隔] メニューで、集計間隔を特定の間隔に設定します。たとえば、このフィールドの値を
1 hourに設定します。[Automatic interval] は選択しないでください。 - [メジャー] を数値列に設定し、sum などの関数を選択します。
ディメンションとメジャーを変更する
ディメンションとメジャーのフィールドを選択することで、グラフ化する行と列を選択できます。
ディメンション
ディメンションは、タイムスタンプ、数値、または文字列の列である必要があります。デフォルトでは、ディメンションはスキーマ内の最初のタイムスタンプ ベースの列に設定されます。クエリにタイムスタンプが含まれていない場合は、最初の文字列の列がディメンションとして選択されます。[グラフを表示] パネルでディメンションの定義をカスタマイズすることもできます。ディメンションとしてタイムスタンプ列を選択すると、時間の経過とともにデータがどのように変化するかがグラフに示されます。棒グラフのディメンションとして文字列の列を選択した場合は、昇順または降順でデータを並べ替えることができます。これにより、ディメンションが辞書順で並べ替えられます。デフォルトの並べ替え順序を維持することもできます。この場合、対応する指標の値に基づいてディメンションが降順で並べ替えられます。
タイムスタンプの間隔はデフォルトで自動的に設定されますが、カスタムの間隔を選択することもできます。自動間隔は、時間範囲セレクタに基づいて値を変更し、サイズが類似したグループを維持します。
期間を無効にすることもできます。これにより、クエリ内で独自の集計と期間を指定して、より複雑な分析を行うことができます。間隔を無効にすると、メジャーの集計関数が
noneに設定されます。ディメンション間隔が無効になっている場合、数値のメジャーのみが許可されます。測定
[グラフを表示] パネルで複数のメジャーを選択できます。メジャーを選択する場合は、グループ化された値(
count、sum、average、percentile-99など)に実行する集計関数も選択する必要があります。たとえば、count-distinctは指定した列内の一意の値の数を返します。ディメンションの [Disable interval] チェックボックスをオンにすると、
none集計関数のオプションを使用できます。ディメンションが文字列値の場合、[Disable interval] チェックボックスは表示されません。ただし、メジャーの集計関数をnoneに設定すると、間隔も無効になります。
内訳を追加する
単一のデータ系列を別の列に基づいて複数のデータ系列に分割するには、内訳を追加します。
内訳を選択した場合は、多数の文字列や長い文字列(textPayload など)を含むフィールドではなく、少数の短い、意味のあるラベル(region_name など)を含む列を選択します。
ログデータ
たとえば、ディメンション フィールドがタイプ、メジャー フィールドが行数をカウントする、内訳フィールドが重要度に設定されている、次のグラフ構成をご覧ください。
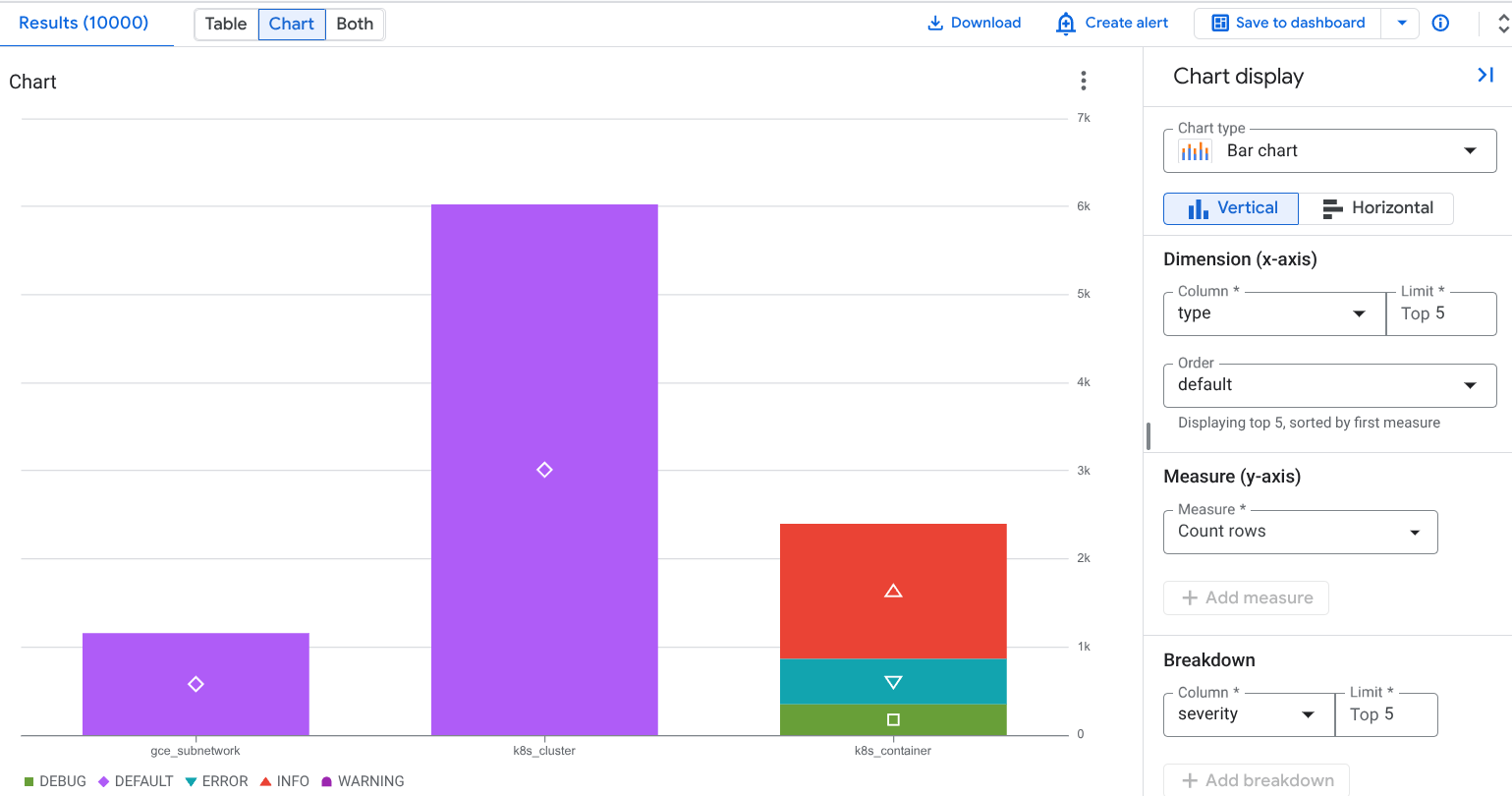
前のスクリーンショットでは、積み重ねられたデータ系列が表示され、ここではリソースタイプ k8s_container が異なる severity タイプに分割されています。これにより、特定のリソースによって重大度タイプごとに生成されたログの数を特定できます。
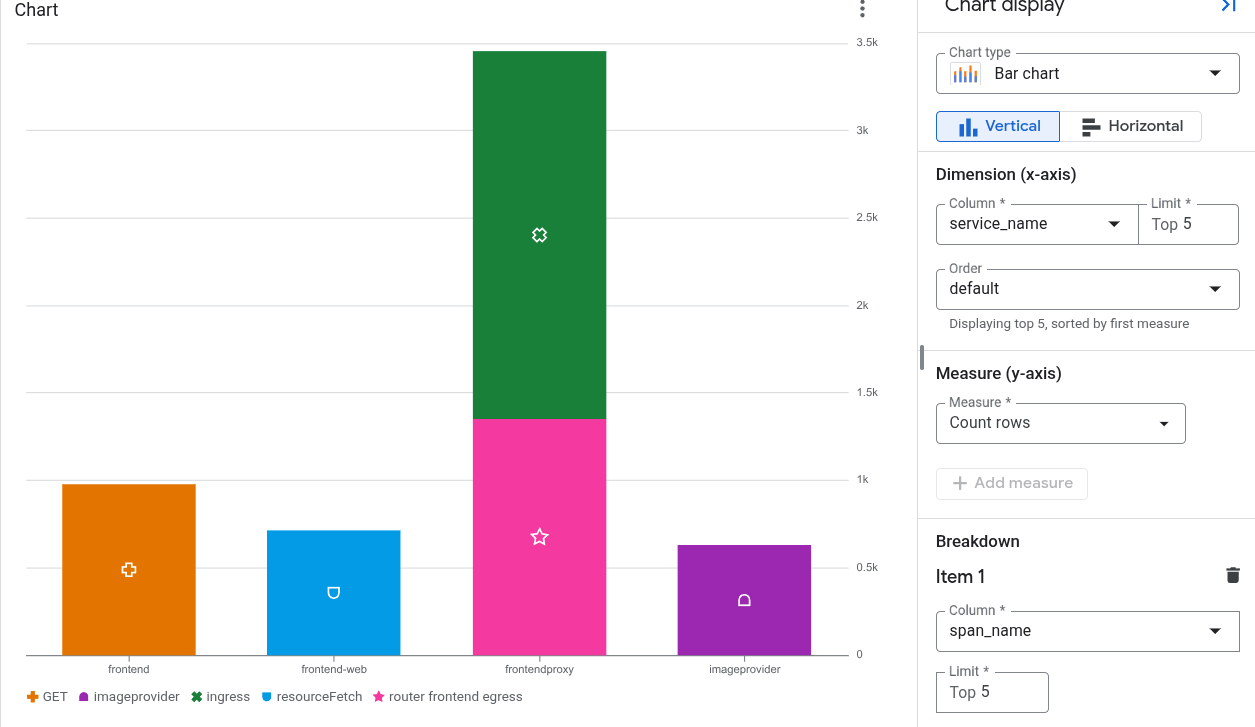
トレースデータ
たとえば、次のグラフは、各サービスによって作成されたスパンの数と、スパン名で分類されたデータを示しています。
カスタム ダッシュボードにグラフを保存する
クエリからグラフを生成したら、そのグラフをカスタム ダッシュボードに保存できます。カスタム ダッシュボードでは、さまざまな種類のウィジェットを使用して、有用な情報を表示し、整理できます。また、これらのダッシュボードでは、特定のウィジェットにのみ適用されるダッシュボード レベルのフィルタである変数を定義することもできます。変数をウィジェットに適用するには、クエリを変更する必要があります。詳細については、ウィジェットに変数を適用するをご覧ください。
クエリが BigQuery エンジンで実行され、クエリ対象のリソースが同じ所有権境界内にない場合、ダッシュボードには SQL クエリを含むウィジェットの警告メッセージが表示されます。所有権の境界は、クエリで使用されるリソースの階層など、いくつかの要因によって決まります。これらの警告を回避するには、サービス境界を設定します。
グラフをダッシュボードに保存する手順は次のとおりです。
-
Google Cloud コンソールで、manage_search [オブザーバビリティ分析] ページに移動します。
検索バーを使用してこのページを検索する場合は、小見出しが [Logging] の結果を選択します。
クエリを実行してグラフを生成し、[ ダッシュボードに保存] をクリックします。
[ダッシュボードに保存] ダイアログで、グラフのタイトルを入力し、グラフを保存するダッシュボードを選択します。
省略可: カスタム ダッシュボードを表示するには、トーストで [ダッシュボードを表示] をクリックします。
SQL クエリで生成されたグラフを含むカスタム ダッシュボードのリストを表示するには、[ダッシュボードに保存] ボタンに移動し、[arrow_drop_down メニュー] をクリックします。
カスタム ダッシュボードに保存されたグラフを編集する
ダッシュボードに保存した後でグラフを変更できます。詳細については、ウィジェットの構成を変更するをご覧ください。[ウィジェットを構成する] ダイアログで、次の操作を行います。
- クエリするデータを変更します。
- グラフの生成に使用されるクエリを編集します。
- グラフの構成をカスタマイズして、さまざまなデータを可視化します。
制限事項
Google Cloud プロジェクトが Assured Workloads を使用するフォルダ内にある場合、生成したグラフはカスタム ダッシュボードに表示されません。
ダッシュボード レベルのフィルタは、SQL クエリから生成されたグラフには適用されません。
選択した列には、NULL 以外の値を持つ行が少なくとも 1 つ必要です。
クエリを保存してグラフ構成をカスタマイズした場合、カスタムグラフの構成は保存されません。
クエリにすでに集計が含まれている場合、オブザーバビリティ分析によって自動的に適用される追加の集計が原因で、生成されるグラフが異なることがあります。
JSON パスをグラフに表示するには、文字列と数値にキャストする必要があります。