
Chirp 3 es la generación más reciente de modelos generativos multilingües específicos para el reconocimiento de voz automático (ASR) de Google, diseñados con el objetivo de satisfacer las necesidades de los usuarios a partir de sus comentarios y experiencias. Chirp 3 proporciona mayor exactitud y velocidad que los modelos anteriores de Chirp. Además, ofrece identificación y detección automática de idiomas.
Detalles del modelo
Chirp 3: Transcription está disponible solo en la API V2 de Speech-to-Text.
Identificadores de modelos
Puedes usar Chirp 3: Transcription como cualquier otro modelo. Para ello, especifica el identificador de modelo adecuado en tu solicitud de reconocimiento cuando uses la API o el nombre del modelo en la consola de Google Cloud . Especifica el identificador adecuado en tu reconocimiento.
| Modelo | Identificador del modelo |
|---|---|
| Chirp 3 | chirp_3 |
Métodos de la API
No todos los métodos de reconocimiento admiten los mismos conjuntos de disponibilidad de idiomas. Como Chirp 3 está disponible en la API V2 de Speech-to-Text, admite los siguientes métodos de reconocimiento:
| Versión de API | Método de la API | Compatibilidad |
|---|---|---|
| V2 | Speech.StreamingRecognize (adecuado para audio en tiempo real y transmisión) | Compatible |
| V2 | Speech.Recognize (adecuado para audios de menos de un minuto) | Compatible |
| V2 | Speech.BatchRecognize (adecuado para audios largos de 1 minuto a 1 hora) | Compatible |
Disponibilidad regional
Chirp 3 está disponible en las siguientes regiones de Google Cloud y pronto habrá más:
| Zona deGoogle Cloud | Preparación para el lanzamiento |
|---|---|
us (multi-region) |
DG |
eu (multi-region) |
DG |
asia-northeast1 |
DG |
asia-southeast1 |
DG |
asia-south1 |
Versión preliminar |
europe-west2 |
Versión preliminar |
europe-west3 |
Versión preliminar |
northamerica-northeast1 |
Versión preliminar |
Con la API de Locations, como se explica aquí, puedes encontrar la lista más reciente de regiones de Google Cloud , idiomas, parámetros de configuración regionales y funciones compatibles para cada modelo de transcripción.
Disponibilidad de idiomas para la transcripción
Chirp 3 admite la transcripción en StreamingRecognize, Recognize y BatchRecognize en los
siguientes idiomas:
| Idioma | BCP-47 Code |
Preparación para el lanzamiento |
| Catalán (España) | ca-ES | DG |
| Chino (simplificado, China) | cmn-Hans-CN | DG |
| Croata (Croacia) | hr-HR | DG |
| Danés (Dinamarca) | da-DK | DG |
| Holandés (Países Bajos) | nl-NL | DG |
| Inglés (Australia) | en-AU | DG |
| Inglés (Reino Unido) | en-GB | DG |
| Inglés (India) | en-IN | DG |
| Inglés (Estados Unidos) | en-US | DG |
| Finés (Finlandia) | fi-FI | DG |
| Francés (Canadá) | fr-CA | DG |
| Francés (Francia) | fr-FR | DG |
| Alemán (Alemania) | de-DE | DG |
| Griego (Grecia) | el-GR | DG |
| Hindi (India) | hi-IN | DG |
| Italiano (Italia) | it-IT | DG |
| Japonés (Japón) | ja-JP | DG |
| Coreano (Corea) | ko-KR | DG |
| Polaco (Polonia) | pl-PL | DG |
| Portugués (Brasil) | pt-BR | DG |
| Portugués (Portugal) | pt-PT | DG |
| Rumano (Rumania) | ro-RO | DG |
| Ruso (Rusia) | ru-RU | DG |
| Español (España) | es-ES | DG |
| Español (Estados Unidos) | es-US | DG |
| Sueco (Suecia) | sv-SE | DG |
| Turco (Türkiye) | tr-TR | DG |
| Ucraniano (Ucrania) | uk-UA | DG |
| Vietnamita (Vietnam) | vi-VN | DG |
| árabe | ar-XA | Versión preliminar |
| Árabe (Argelia) | ar-DZ | Versión preliminar |
| Árabe (Baréin) | ar-BH | Versión preliminar |
| Árabe (Egipto) | ar-EG | Versión preliminar |
| Árabe (Israel) | ar-IL | Versión preliminar |
| Árabe (Jordania) | ar-JO | Versión preliminar |
| Árabe (Kuwait) | ar-KW | Versión preliminar |
| Árabe (Líbano) | ar-LB | Versión preliminar |
| Árabe (Mauritania) | ar-MR | Versión preliminar |
| Árabe (Marruecos) | ar-MA | Versión preliminar |
| Árabe (Omán) | ar-OM | Versión preliminar |
| Árabe (Catar) | ar-QA | Versión preliminar |
| Árabe (Arabia Saudita) | ar-SA | Versión preliminar |
| Árabe (Estado de Palestina) | ar-PS | Versión preliminar |
| Árabe (Siria) | ar-SY | Versión preliminar |
| Árabe (Túnez) | ar-TN | Versión preliminar |
| Árabe (Emiratos Árabes Unidos) | ar-AE | Versión preliminar |
| Árabe (Yemen) | ar-YE | Versión preliminar |
| Armenio (Armenia) | hy-AM | Versión preliminar |
| Bengalí (Bangladés) | bn-BD | Versión preliminar |
| Bengalí (India) | bn-IN | Versión preliminar |
| Búlgaro (Bulgaria) | bg-BG | Versión preliminar |
| Birmano (Birmania) | my-MM | Versión preliminar |
| Kurdo central (Irak) | ar-IQ | Versión preliminar |
| Chino, Cantonés (Tradicional, Hong Kong) | yue-Hant-HK | Versión preliminar |
| Chino, Mandarín (Tradicional, Taiwán) | cmn-Hant-TW | Versión preliminar |
| Checo (República Checa) | cs-CZ | Versión preliminar |
| Inglés (Filipinas) | en-PH | Versión preliminar |
| Estonio (Estonia) | et-EE | Versión preliminar |
| Filipino (Filipinas) | fil-PH | Versión preliminar |
| Guyaratí (India) | gu-IN | Versión preliminar |
| Hebreo (Israel) | iw-IL | Versión preliminar |
| Húngaro (Hungría) | hu-HU | Versión preliminar |
| Indonesio (Indonesia) | id-ID | Versión preliminar |
| Canarés (India) | kn-IN | Versión preliminar |
| Jemer (Camboya) | km-KH | Versión preliminar |
| Lao (Laos) | lo-LA | Versión preliminar |
| Letón (Letonia) | lv-LV | Versión preliminar |
| Lituano (Lituania) | lt-LT | Versión preliminar |
| Malayo (Malasia) | ms-MY | Versión preliminar |
| Malabar (India) | ml-IN | Versión preliminar |
| Maratí (India) | mr-IN | Versión preliminar |
| Nepalí (Nepal) | ne-NP | Versión preliminar |
| Noruego (Noruega) | no-NO | Versión preliminar |
| Persa (Irán) | fa-IR | Versión preliminar |
| Serbio (Serbia) | sr-RS | Versión preliminar |
| Eslovaco (Eslovaquia) | sk-SK | Versión preliminar |
| Esloveno (Eslovenia) | sl-SI | Versión preliminar |
| Español (México) | es-MX | Versión preliminar |
| Suajili | sw | Versión preliminar |
| Tamil (India) | ta-IN | Versión preliminar |
| Telugu (India) | te-IN | Versión preliminar |
| Tailandés (Tailandia) | th-TH | Versión preliminar |
| Uzbeko (Uzbekistán) | uz-UZ | Versión preliminar |
Disponibilidad de idiomas para la identificación
Chirp 3 admite la transcripción y la identificación solo en BatchRecognize y Recognize en los siguientes idiomas:
| Idioma | Código BCP-47 |
| Chino (simplificado, China) | cmn-Hans-CN |
| Alemán (Alemania) | de-DE |
| Inglés (Reino Unido) | en-GB |
| Inglés (India) | en-IN |
| Inglés (Estados Unidos) | en-US |
| Español (España) | es-ES |
| Español (Estados Unidos) | es-US |
| Francés (Canadá) | fr-CA |
| Francés (Francia) | fr-FR |
| Hindi (India) | hi-IN |
| Italiano (Italia) | it-IT |
| Japonés (Japón) | ja-JP |
| Coreano (Corea) | ko-KR |
| Portugués (Brasil) | pt-BR |
Compatibilidad y limitaciones de las funciones
Chirp 3 admite las siguientes funciones:
| Función | Descripción | Etapa de lanzamiento |
|---|---|---|
| Puntuación automática | Se genera automáticamente con el modelo y, si lo deseas, se puede inhabilitar. | DG |
| Uso automático de mayúsculas | Se genera automáticamente con el modelo y, si lo deseas, se puede inhabilitar. | DG |
| Marcas de tiempo a nivel de la expresión | El modelo lo genera automáticamente. | DG |
| Identificación de interlocutores | Identifica automáticamente los diferentes interlocutores en la muestra de audio de un solo canal. Solo disponible en BatchRecognize |
DG |
| Adaptación de voz (personalización) | Proporciona sugerencias al modelo con frases o palabras para mejorar la exactitud del reconocimiento de términos específicos o nombres propios. | DG |
| Transcripción de audio independiente del idioma | Infiere y transcribe automáticamente en el idioma más frecuente. | DG |
Chirp 3 no admite las siguientes funciones:
| Función | Descripción |
| Marcas de tiempo a nivel de la palabra | El modelo lo genera automáticamente y se puede habilitar de forma opcional, lo que genera cierta degradación en la transcripción. |
| Puntuaciones de confianza a nivel de palabra | La API devuelve un valor, pero no es realmente una puntuación de confianza. |
Transcribe con Chirp 3
Descubre cómo usar Chirp 3 para tareas de transcripción.
Realiza un reconocimiento de voz de transmisión
Python
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
REGION = "us"
def transcribe_streaming_chirp3(
audio_file: str
) -> cloud_speech.StreamingRecognizeResponse:
"""Transcribes audio from audio file stream using the Chirp 3 model of Google Cloud Speech-to-Text v2 API.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API V2 containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint=f"{REGION}-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
content = f.read()
# In practice, stream should be a generator yielding chunks of audio data
chunk_length = len(content) // 5
stream = [
content[start : start + chunk_length]
for start in range(0, len(content), chunk_length)
]
audio_requests = (
cloud_speech.StreamingRecognizeRequest(audio=audio) for audio in stream
)
recognition_config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_3",
)
streaming_config = cloud_speech.StreamingRecognitionConfig(
config=recognition_config
)
config_request = cloud_speech.StreamingRecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/{REGION}/recognizers/_",
streaming_config=streaming_config,
)
def requests(config: cloud_speech.RecognitionConfig, audio: list) -> list:
yield config
yield from audio
# Transcribes the audio into text
responses_iterator = client.streaming_recognize(
requests=requests(config_request, audio_requests)
)
responses = []
for response in responses_iterator:
responses.append(response)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return responses
Realiza un reconocimiento de voz síncrono
Python
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
REGION = "us"
def transcribe_sync_chirp3(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Transcribes an audio file using the Chirp 3 model of Google Cloud Speech-to-Text V2 API.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint=f"{REGION}-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_3",
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/{REGION}/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return response
Realiza un reconocimiento de voz por lotes
Python
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
REGION = "us"
def transcribe_batch_3(
audio_uri: str,
) -> cloud_speech.BatchRecognizeResults:
"""Transcribes an audio file from a Google Cloud Storage URI using the Chirp 3 model of Google Cloud Speech-to-Text v2 API.
Args:
audio_uri (str): The Google Cloud Storage URI of the input audio file.
E.g., gs://[BUCKET]/[FILE]
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint=f"{REGION}-speech.googleapis.com",
)
)
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_3",
)
file_metadata = cloud_speech.BatchRecognizeFileMetadata(uri=audio_uri)
request = cloud_speech.BatchRecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/{REGION}/recognizers/_",
config=config,
files=[file_metadata],
recognition_output_config=cloud_speech.RecognitionOutputConfig(
inline_response_config=cloud_speech.InlineOutputConfig(),
),
)
# Transcribes the audio into text
operation = client.batch_recognize(request=request)
print("Waiting for operation to complete...")
response = operation.result(timeout=120)
for result in response.results[audio_uri].transcript.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return response.results[audio_uri].transcript
Usa las funciones de Chirp 3
Explora cómo puedes usar las funciones más recientes con ejemplos de código:
Realiza una transcripción independiente del idioma
Chirp 3 puede identificar y transcribir automáticamente el idioma dominante que se habla en el audio, lo que es esencial en las aplicaciones multilingües. Para lograr esto, establece language_codes=["auto"] como se indica en el ejemplo de código:
Python
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
REGION = "us"
def transcribe_sync_chirp3_auto_detect_language(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Transcribes an audio file and auto-detect spoken language using Chirp 3.
Please see https://cloud.google.com/speech-to-text/docs/encoding for more
information on which audio encodings are supported.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint=f"{REGION}-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["auto"], # Set language code to auto to detect language.
model="chirp_3",
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/{REGION}/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
print(f"Detected Language: {result.language_code}")
return response
Realiza una transcripción restringida por el idioma
Chirp 3 puede identificar y transcribir automáticamente el idioma dominante en un archivo de audio. También puedes condicionarlo a parámetros de configuración regional específicos que esperes. Por ejemplo: ["en-US", "fr-FR"], que permitiría que los recursos del modelo se enfoquen en los idiomas más probables para obtener resultados más confiables, como se demuestra en el ejemplo de código:
Python
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
REGION = "us"
def transcribe_sync_3_auto_detect_language(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Transcribes an audio file and auto-detect spoken language using Chirp 3.
Please see https://cloud.google.com/speech-to-text/docs/encoding for more
information on which audio encodings are supported.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint=f"{REGION}-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US", "fr-FR"], # Set language codes of the expected spoken locales
model="chirp_3",
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/{REGION}/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
print(f"Detected Language: {result.language_code}")
return response
Realiza la transcripción y la identificación de interlocutores
Usa Chirp 3 para tareas de identificación y transcripción.
Python
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
REGION = "us"
def transcribe_batch_chirp3(
audio_uri: str,
) -> cloud_speech.BatchRecognizeResults:
"""Transcribes an audio file from a Google Cloud Storage URI using the Chirp 3 model of Google Cloud Speech-to-Text V2 API.
Args:
audio_uri (str): The Google Cloud Storage URI of the input
audio file. E.g., gs://[BUCKET]/[FILE]
Returns:
cloud_speech.RecognizeResponse: The response from the
Speech-to-Text API containing the transcription results.
"""
# Instantiates a client.
client = SpeechClient(
client_options=ClientOptions(
api_endpoint=f"{REGION}-speech.googleapis.com",
)
)
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"], # Use "auto" to detect language.
model="chirp_3",
features=cloud_speech.RecognitionFeatures(
# Enable diarization by setting empty diarization configuration.
diarization_config=cloud_speech.SpeakerDiarizationConfig(),
),
)
file_metadata = cloud_speech.BatchRecognizeFileMetadata(uri=audio_uri)
request = cloud_speech.BatchRecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/{REGION}/recognizers/_",
config=config,
files=[file_metadata],
recognition_output_config=cloud_speech.RecognitionOutputConfig(
inline_response_config=cloud_speech.InlineOutputConfig(),
),
)
# Creates audio transcription job.
operation = client.batch_recognize(request=request)
print("Waiting for transcription job to complete...")
response = operation.result(timeout=120)
for result in response.results[audio_uri].transcript.results:
print(f"Transcript: {result.alternatives[0].transcript}")
print(f"Detected Language: {result.language_code}")
print(f"Speakers per word: {result.alternatives[0].words}")
return response.results[audio_uri].transcript
Mejora la exactitud con la adaptación de modelos
Chirp 3 puede mejorar la exactitud de la transcripción de tu audio específico con la adaptación del modelo. Esto te permite proporcionar una lista de palabras y frases específicas, lo que aumenta la probabilidad de que el modelo las reconozca. Es muy útil para términos específicos del dominio, nombres propios o vocabulario único.
Python
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
REGION = "us"
def transcribe_sync_chirp3_model_adaptation(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Transcribes an audio file using the Chirp 3 model with adaptation, improving accuracy for specific audio characteristics or vocabulary.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint=f"{REGION}-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_3",
# Use model adaptation
adaptation=cloud_speech.SpeechAdaptation(
phrase_sets=[
cloud_speech.SpeechAdaptation.AdaptationPhraseSet(
inline_phrase_set=cloud_speech.PhraseSet(phrases=[
{
"value": "alphabet",
},
{
"value": "cell phone service",
}
])
)
]
)
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/{REGION}/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return response
Habilita el filtro de cancelación de ruido y de SNR
Chirp 3 puede reducir el ruido de fondo y filtrar los sonidos no deseados antes de la transcripción para mejorar la calidad del audio. Habilita el filtro de reducción de ruido integrado y el filtro de relación señal/ruido (SNR) y mejora los resultados en entornos ruidosos.
El parámetro de configuración denoiser_audio=true puede ayudarte a reducir la música o los ruidos de fondo con eficacia,
como la lluvia y el tráfico de la calle.
Puedes configurar snr_threshold=X para controlar el volumen mínimo del habla necesario
de la transcripción. Esto ayuda a filtrar el audio que no es voz o el ruido
de fondo, lo que evita que aparezca texto no deseado en los resultados. Un valor de snr_threshold más alto
significa que el usuario debe hablar más alto para que el modelo transcriba las expresiones.
El filtro de SNR se puede usar en casos de uso de transmisión en tiempo real para evitar enviar sonidos innecesarios a un modelo en su transcripción. Un valor más alto para este parámetro de configuración significa que el volumen de tu voz debe ser más alto en relación con el ruido de fondo para enviarse al modelo de transcripción.
La configuración de snr_threshold interactuará
con denoise_audio, ya sea true o false. Cuando la configuración es denoise_audio=true,
se quita el ruido de fondo y la voz se vuelve un poco más clara. El
SNR general del audio aumenta.
Si tu caso de uso solo involucra la voz del usuario sin que hablen otras personas, configura denoise_audio=true para aumentar la sensibilidad del filtrado de SNR, lo que puede
filtrar el ruido que no es del habla. Si tu caso de uso involucra voces
de fondo y quieres evitar que se transcriban,
considera configurar denoise_audio=false y reducir el umbral de SNR.
A continuación, se indican los valores de umbral de SNR recomendados. Se puede establecer un valor snr_threshold
razonable entre 0 y 1000. Un valor 0 significa que no se filtra nada, y 1000
significa que se filtra todo. Ajusta el valor si el parámetro de configuración recomendado no
es el adecuado para ti.
| Cancelar ruido del audio | Umbral de SNR | Sensibilidad a la voz |
|---|---|---|
| true | 10.0 | alta |
| true | 20.0 | media |
| true | 40.0 | baja |
| true | 100.0 | muy baja |
| false | 0.5 | alta |
| false | 1.0 | media |
| false | 2.0 | baja |
| false | 5.0 | muy baja |
Python
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
REGION = "us"
def transcribe_sync_chirp3_with_timestamps(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Transcribes an audio file using the Chirp 3 model of Google Cloud Speech-to-Text v2 API, which provides word-level timestamps for each transcribed word.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint=f"{REGION}-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_3",
denoiser_config={
denoise_audio: True,
# Medium snr threshold
snr_threshold: 20.0,
}
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/{REGION}/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return response
Usa Chirp 3 en la consola de Google Cloud
- Regístrate para obtener una cuenta de Google Cloud y crea un proyecto.
- Ve a Speech en la consola de Google Cloud .
- Habilita la API en caso de que no esté habilitada.
Asegúrate de tener un espacio de trabajo en la consola de STT. Si no tienes un espacio de trabajo, deberás crear uno.
Ve a la página de transcripciones y haz clic en Transcripción nueva (New Transcription).
Abre el menú desplegable Espacio de trabajo (Workspace) y haz clic en Nuevo espacio de trabajo para crear un espacio de trabajo de transcripción.
Desde la barra lateral de navegación Crea un lugar de trabajo nuevo, haz clic en Explorar (Browse).
Haz clic para crear un bucket nuevo.
Escribe un nombre para tu bucket y haz clic en Continuar (Continue).
Haz clic en Crear para crear un bucket de Cloud Storage.
Una vez que se haya creado el bucket, haz clic en Seleccionar para seleccionarlo.
Haz clic en Crear para completar la configuración de tu espacio de trabajo en la consola de la API V2 de Speech-to-Text.
Realiza una transcripción en tu audio real.
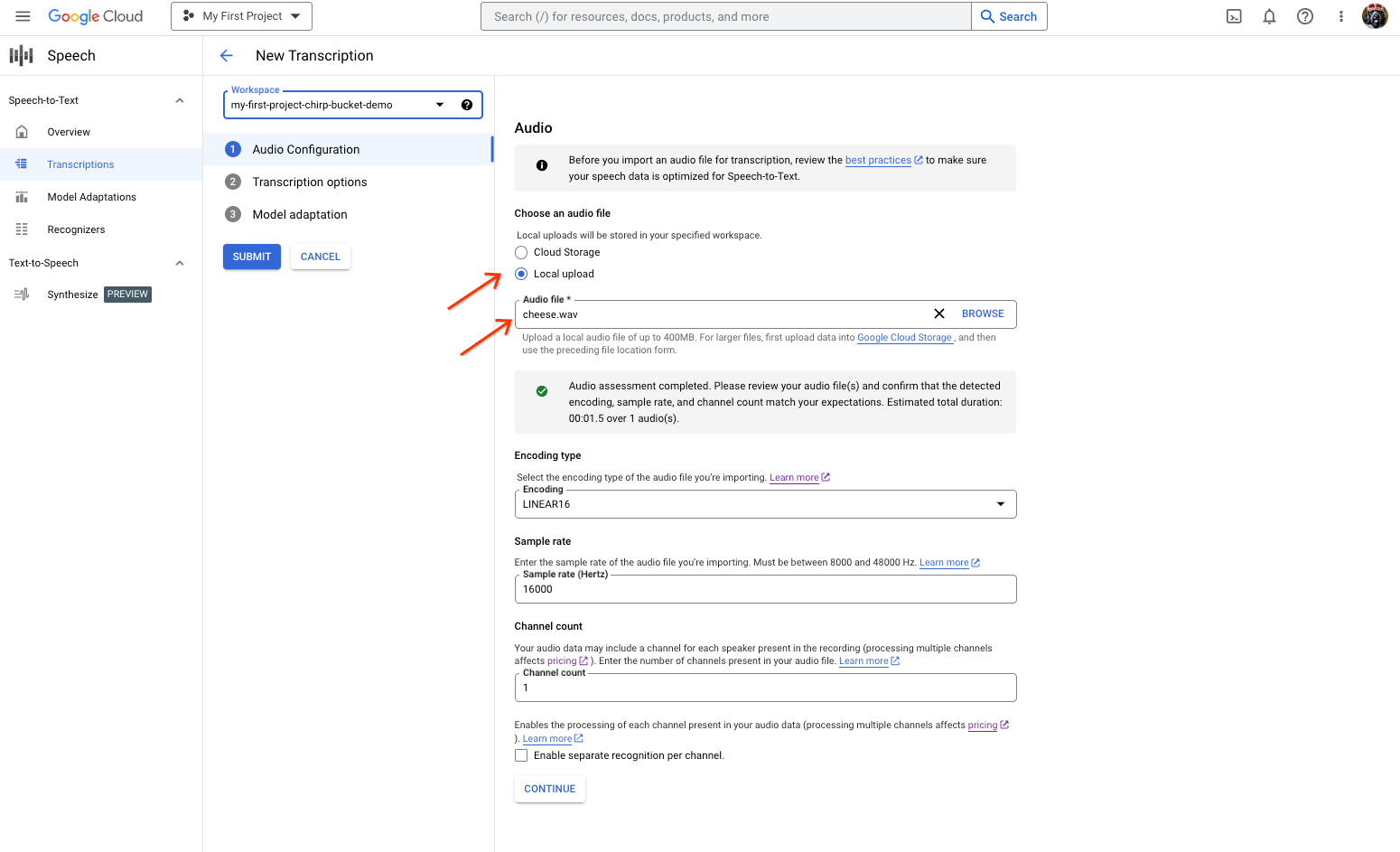
Página de creación de transcripciones de Speech-to-Text, en la que se muestra la selección o carga del archivo. En la página Transcripción nueva (New Transcription), selecciona el archivo de audio y cárgalo con Carga local (Local upload) o especifica un archivo de Cloud Storage existente (Cloud Storage).
Haz clic en Continuar (Continue) para ir a Opciones de transcripción (Transcription options).
Selecciona el Idioma de voz que usarás para el reconocimiento con Chirp de tu reconocedor que creaste antes.
En el menú desplegable del modelo, selecciona chirp_3.
En el menú desplegable Reconocedor, selecciona el que acabas de crear.
Haz clic en Enviar (Submit) para ejecutar tu primera solicitud de reconocimiento con
chirp_3.
Visualiza el resultado de la transcripción de Chirp 3.
En la página Transcripciones (Transcriptions), haz clic en el nombre de la transcripción para ver su resultado.
En la página Detalles de la transcripción, visualiza el resultado de la transcripción. También tienes la opción de reproducir el audio en el navegador.