
O Chirp 3 é a geração mais recente dos modelos generativos específicos de reconhecimento automático de voz (ASR) multilingues da Google, concebidos para satisfazer as necessidades dos utilizadores com base no feedback e na experiência. O Chirp 3 oferece maior precisão e velocidade em comparação com os modelos Chirp anteriores, além de fornecer diarização e deteção automática de idioma.
Detalhes do modelo
O Chirp 3: transcrição está disponível exclusivamente na API Speech-to-Text V2.
Identificadores do modelo
Pode usar o Chirp 3: Transcription tal como qualquer outro modelo, especificando o identificador do modelo adequado no seu pedido de reconhecimento quando usar a API ou o nome do modelo na Google Cloud consola. Especifique o identificador adequado no seu reconhecimento.
| Modelo | Identificador do modelo |
|---|---|
| Chirp 3 | chirp_3 |
Métodos da API
Nem todos os métodos de reconhecimento suportam os mesmos conjuntos de disponibilidade de idiomas. Uma vez que o Chirp 3 está disponível na API Speech-to-Text V2, suporta os seguintes métodos de reconhecimento:
| Versão da API | Método da API | Apoio técnico |
|---|---|---|
| V2 | Speech.StreamingRecognize (adequado para streaming e áudio em tempo real) | Suportado |
| V2 | Speech.Recognize (adequado para áudio com menos de um minuto) | Suportado |
| V2 | Speech.BatchRecognize (bom para áudio longo, geralmente de 1 minuto a 1 hora, mas até 20 minutos com a indicação de tempo ao nível da palavra ativada) | Suportado |
Disponibilidade regional
O Chirp 3 está disponível nas seguintes Google Cloud regiões, com mais regiões planeadas:
| Google Cloud Zona | Disponibilidade para lançamento |
|---|---|
us (multi-region) |
DG |
eu (multi-region) |
DG |
asia-northeast1 |
DG |
asia-southeast1 |
DG |
asia-south1 |
Pré-visualização |
europe-west2 |
Pré-visualização |
europe-west3 |
Pré-visualização |
northamerica-northeast1 |
Pré-visualização |
Usando a API Locations, conforme explicado aqui, pode encontrar a lista mais recente de regiões, idiomas e locais, e funcionalidades suportados Google Cloud para cada modelo de transcrição.
Idiomas disponíveis para a transcrição
O Chirp 3 suporta a transcrição em StreamingRecognize, Recognize e BatchRecognize nos seguintes idiomas:
| Idioma | BCP-47 Code |
Disposição para lançamento |
| Catalão (Espanha) | ca-ES | DG |
| Chinês (simplificado, China) | cmn-Hans-CN | DG |
| Croata (Croácia) | hr-HR | DG |
| Dinamarquês (Dinamarca) | da-DK | DG |
| Neerlandês (Países Baixos) | nl-NL | DG |
| Inglês (Austrália) | en-AU | DG |
| Inglês (Reino Unido) | en-GB | DG |
| Inglês (Índia) | en-IN | DG |
| Inglês (Estados Unidos) | en-US | DG |
| Finlandês (Finlândia) | fi-FI | DG |
| Francês (Canadá) | fr-CA | DG |
| Francês (França) | fr-FR | DG |
| Alemão (Alemanha) | de-DE | DG |
| Grego (Grécia) | el-GR | DG |
| Hindi (Índia) | hi-IN | DG |
| Italiano (Itália) | it-IT | DG |
| Japonês (Japão) | ja-JP | DG |
| Coreano (Coreia) | ko-KR | DG |
| Polaco (Polónia) | pl-PL | DG |
| Português (Brasil) | pt-BR | DG |
| Português (Portugal) | pt-PT | DG |
| Romeno (Roménia) | ro-RO | DG |
| Russo (Rússia) | ru-RU | DG |
| Espanhol (Espanha) | es-ES | DG |
| Espanhol (Estados Unidos) | es-US | DG |
| Sueco (Suécia) | sv-SE | DG |
| Turco (Turquia) | tr-TR | DG |
| Ucraniano (Ucrânia) | uk-UA | DG |
| Vietnamita (Vietname) | vi-VN | DG |
| Árabe | ar-XA | Pré-visualização |
| Árabe (Argélia) | ar-DZ | Pré-visualização |
| Árabe (Barém) | ar-BH | Pré-visualização |
| Árabe (Egito) | ar-EG | Pré-visualização |
| Árabe (Israel) | ar-IL | Pré-visualização |
| Árabe (Jordânia) | ar-JO | Pré-visualização |
| Árabe (Koweit) | ar-KW | Pré-visualização |
| Árabe (Líbano) | ar-LB | Pré-visualização |
| Árabe (Mauritânia) | ar-MR | Pré-visualização |
| Árabe (Marrocos) | ar-MA | Pré-visualização |
| Árabe (Omã) | ar-OM | Pré-visualização |
| Árabe (Catar) | ar-QA | Pré-visualização |
| Árabe (Arábia Saudita) | ar-SA | Pré-visualização |
| Árabe (Estado da Palestina) | ar-PS | Pré-visualização |
| Árabe (Síria) | ar-SY | Pré-visualização |
| Árabe (Tunísia) | ar-TN | Pré-visualização |
| Árabe (Emirados Árabes Unidos) | ar-AE | Pré-visualização |
| Árabe (Iémen) | ar-YE | Pré-visualização |
| Arménio (Arménia) | hy-AM | Pré-visualização |
| Bengali (Bangladexe) | bn-BD | Pré-visualização |
| Bengali (Índia) | bn-IN | Pré-visualização |
| Búlgaro (Bulgária) | bg-BG | Pré-visualização |
| Birmanês (Mianmar) | my-MM | Pré-visualização |
| Curdo central (Iraque) | ar-IQ | Pré-visualização |
| Chinês, cantonês (Hong Kong tradicional) | yue-Hant-HK | Pré-visualização |
| Chinês, mandarim (tradicional, Taiwan) | cmn-Hant-TW | Pré-visualização |
| Checo (Chéquia) | cs-CZ | Pré-visualização |
| Inglês (Filipinas) | en-PH | Pré-visualização |
| Estónio (Estónia) | et-EE | Pré-visualização |
| Filipino (Filipinas) | fil-PH | Pré-visualização |
| Guzerate (Índia) | gu-IN | Pré-visualização |
| Hebraico (Israel) | iw-IL | Pré-visualização |
| Húngaro (Hungria) | hu-HU | Pré-visualização |
| Indonésio (Indonesia) | id-ID | Pré-visualização |
| Canarim (Índia) | kn-IN | Pré-visualização |
| Khmer (Camboja) | km-KH | Pré-visualização |
| Laosiano (Laos) | lo-LA | Pré-visualização |
| Letão (Letónia) | lv-LV | Pré-visualização |
| Lituano (Lituânia) | lt-LT | Pré-visualização |
| Malaio (Malásia) | ms-MY | Pré-visualização |
| Malaiala (Índia) | ml-IN | Pré-visualização |
| Marati (Índia) | mr-IN | Pré-visualização |
| Nepalês (Nepal) | ne-NP | Pré-visualização |
| Norueguês (Noruega) | no-NO | Pré-visualização |
| Persa (Irão) | fa-IR | Pré-visualização |
| Sérvio (Sérvia) | sr-RS | Pré-visualização |
| Eslovaco (Eslováquia) | sk-SK | Pré-visualização |
| Esloveno (Eslovénia) | sl-SI | Pré-visualização |
| Espanhol (México) | es-MX | Pré-visualização |
| Suaíli | sw | Pré-visualização |
| Tâmil (Índia) | ta-IN | Pré-visualização |
| Telugu (Índia) | te-IN | Pré-visualização |
| Tailandês (Tailândia) | th-TH | Pré-visualização |
| Usbeque (Usbequistão) | uz-UZ | Pré-visualização |
Idiomas disponíveis para a separação de oradores
O Chirp 3 suporta a transcrição e a identificação de oradores apenas em BatchRecognize e Recognize nos seguintes idiomas:
| Idioma | Código BCP-47 |
| Chinês (simplificado, China) | cmn-Hans-CN |
| Alemão (Alemanha) | de-DE |
| Inglês (Reino Unido) | en-GB |
| Inglês (Índia) | en-IN |
| Inglês (Estados Unidos) | en-US |
| Espanhol (Espanha) | es-ES |
| Espanhol (Estados Unidos) | es-US |
| Francês (Canadá) | fr-CA |
| Francês (França) | fr-FR |
| Hindi (Índia) | hi-IN |
| Italiano (Itália) | it-IT |
| Japonês (Japão) | ja-JP |
| Coreano (Coreia) | ko-KR |
| Português (Brasil) | pt-BR |
Suporte de funcionalidades e limitações
O Chirp 3 suporta as seguintes funcionalidades:
| Funcionalidade | Descrição | Fase de lançamento |
|---|---|---|
| Pontuação automática | Geradas automaticamente pelo modelo e podem ser desativadas opcionalmente. | DG |
| Letras maiúsculas automáticas | Geradas automaticamente pelo modelo e podem ser desativadas opcionalmente. | DG |
| Indicações de tempo ao nível da expressão | Gerado automaticamente pelo modelo. Disponível apenas em Speech.StreamingRecognize |
DG |
| Separação de oradores | Identifica automaticamente os diferentes oradores numa amostra de áudio de canal único. Disponível apenas em Speech.BatchRecognize |
DG |
| Adaptação da voz (tendência) | Fornece sugestões ao modelo sob a forma de expressões ou palavras para melhorar a precisão do reconhecimento de termos específicos ou nomes próprios. | DG |
| Transcrição de áudio sem diálogo | Deduz e transcreve automaticamente no idioma mais predominante. | DG |
O Chirp 3 não suporta as seguintes funcionalidades:
| Funcionalidade | Descrição |
|---|---|
| Indicações de tempo ao nível da palavra | Geradas automaticamente pelo modelo e podem ser ativadas opcionalmente, sendo esperada alguma degradação da transcrição. Disponível apenas em Speech.Recognize e Speech.BatchRecognize |
| Pontuações de confiança ao nível da palavra | A API devolve um valor, mas não é verdadeiramente uma pontuação de confiança. |
Transcreva com o Chirp 3
Descubra como usar o Chirp 3 para tarefas de transcrição.
Realize o reconhecimento de voz em streaming
Python
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
REGION = "us"
def transcribe_streaming_chirp3(
audio_file: str
) -> cloud_speech.StreamingRecognizeResponse:
"""Transcribes audio from audio file stream using the Chirp 3 model of Google Cloud Speech-to-Text v2 API.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API V2 containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint=f"{REGION}-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
content = f.read()
# In practice, stream should be a generator yielding chunks of audio data
chunk_length = len(content) // 5
stream = [
content[start : start + chunk_length]
for start in range(0, len(content), chunk_length)
]
audio_requests = (
cloud_speech.StreamingRecognizeRequest(audio=audio) for audio in stream
)
recognition_config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_3",
)
streaming_config = cloud_speech.StreamingRecognitionConfig(
config=recognition_config
)
config_request = cloud_speech.StreamingRecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/{REGION}/recognizers/_",
streaming_config=streaming_config,
)
def requests(config: cloud_speech.RecognitionConfig, audio: list) -> list:
yield config
yield from audio
# Transcribes the audio into text
responses_iterator = client.streaming_recognize(
requests=requests(config_request, audio_requests)
)
responses = []
for response in responses_iterator:
responses.append(response)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return responses
Realize o reconhecimento de voz síncrono
Python
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
REGION = "us"
def transcribe_sync_chirp3(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Transcribes an audio file using the Chirp 3 model of Google Cloud Speech-to-Text V2 API.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint=f"{REGION}-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_3",
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/{REGION}/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return response
Realize o reconhecimento de voz em lote
Python
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
REGION = "us"
def transcribe_batch_3(
audio_uri: str,
) -> cloud_speech.BatchRecognizeResults:
"""Transcribes an audio file from a Google Cloud Storage URI using the Chirp 3 model of Google Cloud Speech-to-Text v2 API.
Args:
audio_uri (str): The Google Cloud Storage URI of the input audio file.
E.g., gs://[BUCKET]/[FILE]
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint=f"{REGION}-speech.googleapis.com",
)
)
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_3",
)
file_metadata = cloud_speech.BatchRecognizeFileMetadata(uri=audio_uri)
request = cloud_speech.BatchRecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/{REGION}/recognizers/_",
config=config,
files=[file_metadata],
recognition_output_config=cloud_speech.RecognitionOutputConfig(
inline_response_config=cloud_speech.InlineOutputConfig(),
),
)
# Transcribes the audio into text
operation = client.batch_recognize(request=request)
print("Waiting for operation to complete...")
response = operation.result(timeout=120)
for result in response.results[audio_uri].transcript.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return response.results[audio_uri].transcript
Use as funcionalidades do Chirp 3
Explore como pode usar as funcionalidades mais recentes com exemplos de código:
Faça uma transcrição sem diálogo
O Chirp 3 pode identificar e transcrever automaticamente no idioma dominante falado no áudio, o que é essencial para aplicações multilingues. Para alcançar este objetivo, defina language_codes=["auto"] como indicado no exemplo de código:
Python
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
REGION = "us"
def transcribe_sync_chirp3_auto_detect_language(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Transcribes an audio file and auto-detect spoken language using Chirp 3.
Please see https://cloud.google.com/speech-to-text/docs/encoding for more
information on which audio encodings are supported.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint=f"{REGION}-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["auto"], # Set language code to auto to detect language.
model="chirp_3",
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/{REGION}/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
print(f"Detected Language: {result.language_code}")
return response
Faça uma transcrição restrita a um idioma
O Chirp 3 pode identificar e transcrever automaticamente o idioma dominante num ficheiro de áudio. Também pode condicioná-lo a locais específicos que espera, por exemplo: ["en-US", "fr-FR"], o que focaria os recursos do modelo nos idiomas mais prováveis para resultados mais fiáveis, conforme demonstrado no exemplo de código:
Python
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
REGION = "us"
def transcribe_sync_3_auto_detect_language(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Transcribes an audio file and auto-detect spoken language using Chirp 3.
Please see https://cloud.google.com/speech-to-text/docs/encoding for more
information on which audio encodings are supported.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint=f"{REGION}-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US", "fr-FR"], # Set language codes of the expected spoken locales
model="chirp_3",
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/{REGION}/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
print(f"Detected Language: {result.language_code}")
return response
Realizar a transcrição e a separação de oradores
Use o Chirp 3 para tarefas de transcrição e segmentação de oradores.
Python
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
REGION = "us"
def transcribe_batch_chirp3(
audio_uri: str,
) -> cloud_speech.BatchRecognizeResults:
"""Transcribes an audio file from a Google Cloud Storage URI using the Chirp 3 model of Google Cloud Speech-to-Text V2 API.
Args:
audio_uri (str): The Google Cloud Storage URI of the input
audio file. E.g., gs://[BUCKET]/[FILE]
Returns:
cloud_speech.RecognizeResponse: The response from the
Speech-to-Text API containing the transcription results.
"""
# Instantiates a client.
client = SpeechClient(
client_options=ClientOptions(
api_endpoint=f"{REGION}-speech.googleapis.com",
)
)
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"], # Use "auto" to detect language.
model="chirp_3",
features=cloud_speech.RecognitionFeatures(
# Enable diarization by setting empty diarization configuration.
diarization_config=cloud_speech.SpeakerDiarizationConfig(),
),
)
file_metadata = cloud_speech.BatchRecognizeFileMetadata(uri=audio_uri)
request = cloud_speech.BatchRecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/{REGION}/recognizers/_",
config=config,
files=[file_metadata],
recognition_output_config=cloud_speech.RecognitionOutputConfig(
inline_response_config=cloud_speech.InlineOutputConfig(),
),
)
# Creates audio transcription job.
operation = client.batch_recognize(request=request)
print("Waiting for transcription job to complete...")
response = operation.result(timeout=120)
for result in response.results[audio_uri].transcript.results:
print(f"Transcript: {result.alternatives[0].transcript}")
print(f"Detected Language: {result.language_code}")
print(f"Speakers per word: {result.alternatives[0].words}")
return response.results[audio_uri].transcript
Melhore a precisão com a adaptação do modelo
O Chirp 3 pode melhorar a precisão da transcrição para o seu áudio específico através da adaptação do modelo. Isto permite-lhe fornecer uma lista de palavras e expressões específicas, o que aumenta a probabilidade de o modelo as reconhecer. É especialmente útil para termos específicos do domínio, nomes próprios ou vocabulário único.
Python
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
REGION = "us"
def transcribe_sync_chirp3_model_adaptation(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Transcribes an audio file using the Chirp 3 model with adaptation, improving accuracy for specific audio characteristics or vocabulary.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint=f"{REGION}-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_3",
# Use model adaptation
adaptation=cloud_speech.SpeechAdaptation(
phrase_sets=[
cloud_speech.SpeechAdaptation.AdaptationPhraseSet(
inline_phrase_set=cloud_speech.PhraseSet(phrases=[
{
"value": "alphabet",
},
{
"value": "cell phone service",
}
])
)
]
)
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/{REGION}/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return response
Ative o cancelamento de ruído e a filtragem de SNR
O Chirp 3 pode melhorar a qualidade do áudio reduzindo o ruído de fundo e filtrando sons indesejados antes da transcrição. Pode melhorar os resultados em ambientes ruidosos ativando o redutor de ruído integrado e a filtragem da relação sinal/ruído (SNR).
A definição denoiser_audio=true pode ajudar a reduzir eficazmente a música de fundo ou os ruídos, como a chuva e o trânsito na rua.
Pode definir snr_threshold=X para controlar o volume mínimo da voz necessário para a transcrição. Isto ajuda a filtrar o áudio sem voz ou o ruído de fundo, evitando texto indesejado nos seus resultados. Um valor snr_threshold mais elevado significa que o utilizador tem de falar mais alto para que o modelo transcreva as expressões.
A filtragem de SNR pode ser usada em exemplos de utilização de streaming em tempo real para evitar o envio de sons desnecessários para um modelo de transcrição. Um valor mais elevado para esta definição significa que o volume da sua voz tem de ser mais alto em relação ao ruído de fundo para ser enviado para o modelo de transcrição.
A configuração de snr_threshold interage com o facto de denoise_audio ser true ou false. Quando denoise_audio=true, o ruído de fundo é removido e a voz torna-se relativamente mais clara. A relação sinal/ruído geral do áudio aumenta.
Se o seu exemplo de utilização envolver apenas a voz do utilizador sem outras pessoas a falar, defina denoise_audio=true para aumentar a sensibilidade da filtragem de SNR, que pode filtrar o ruído que não seja de voz. Se o seu exemplo de utilização envolver pessoas a falar em segundo plano e quiser evitar a transcrição da fala em segundo plano, considere definir denoise_audio=false e baixar o limite de SNR.
Seguem-se os valores de limite de SNR recomendados. Pode definir um valor snr_threshold
razoável entre 0 e 1000. Um valor de 0 significa que não filtra nada e 1000
significa que filtra tudo. Ajuste o valor se a definição recomendada não
funcionar para si.
| Remova o ruído do áudio | Limite de SNR | Sensibilidade da voz |
|---|---|---|
| verdadeiro | 10,0 | alta |
| verdadeiro | 20,0 | média |
| verdadeiro | 40,0 | baixos |
| verdadeiro | 100,0 | muito baixa |
| falso | 0,5 | alta |
| falso | 1,0 | média |
| falso | 2,0 | baixos |
| falso | 5.0 | muito baixa |
Python
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
REGION = "us"
def transcribe_sync_chirp3_with_timestamps(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Transcribes an audio file using the Chirp 3 model of Google Cloud Speech-to-Text v2 API, which provides word-level timestamps for each transcribed word.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint=f"{REGION}-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_3",
denoiser_config={
denoise_audio: True,
# Medium snr threshold
snr_threshold: 20.0,
}
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/{REGION}/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return response
Use o Chirp 3 na Google Cloud consola
- Inscreva-se numa Google Cloud conta e crie um projeto.
- Aceda a Voz na Google Cloud consola.
- Se a API não estiver ativada, ative-a.
Certifique-se de que tem uma consola de STT do Workspace. Se não tiver um espaço de trabalho, tem de criar um.
Aceda à página de transcrições e clique em Nova transcrição.
Abra o menu pendente Espaço de trabalho e clique em Novo espaço de trabalho para criar um espaço de trabalho para a transcrição.
Na barra lateral de navegação Criar um novo espaço de trabalho, clique em Procurar.
Clique para criar um novo contentor.
Introduza um nome para o seu depósito e clique em Continuar.
Clique em Criar para criar o contentor do Cloud Storage.
Depois de criar o contentor, clique em Selecionar para selecionar o contentor para utilização.
Clique em Criar para concluir a criação do espaço de trabalho para a consola da API Speech-to-Text V2.
Fazer uma transcrição do seu áudio real.
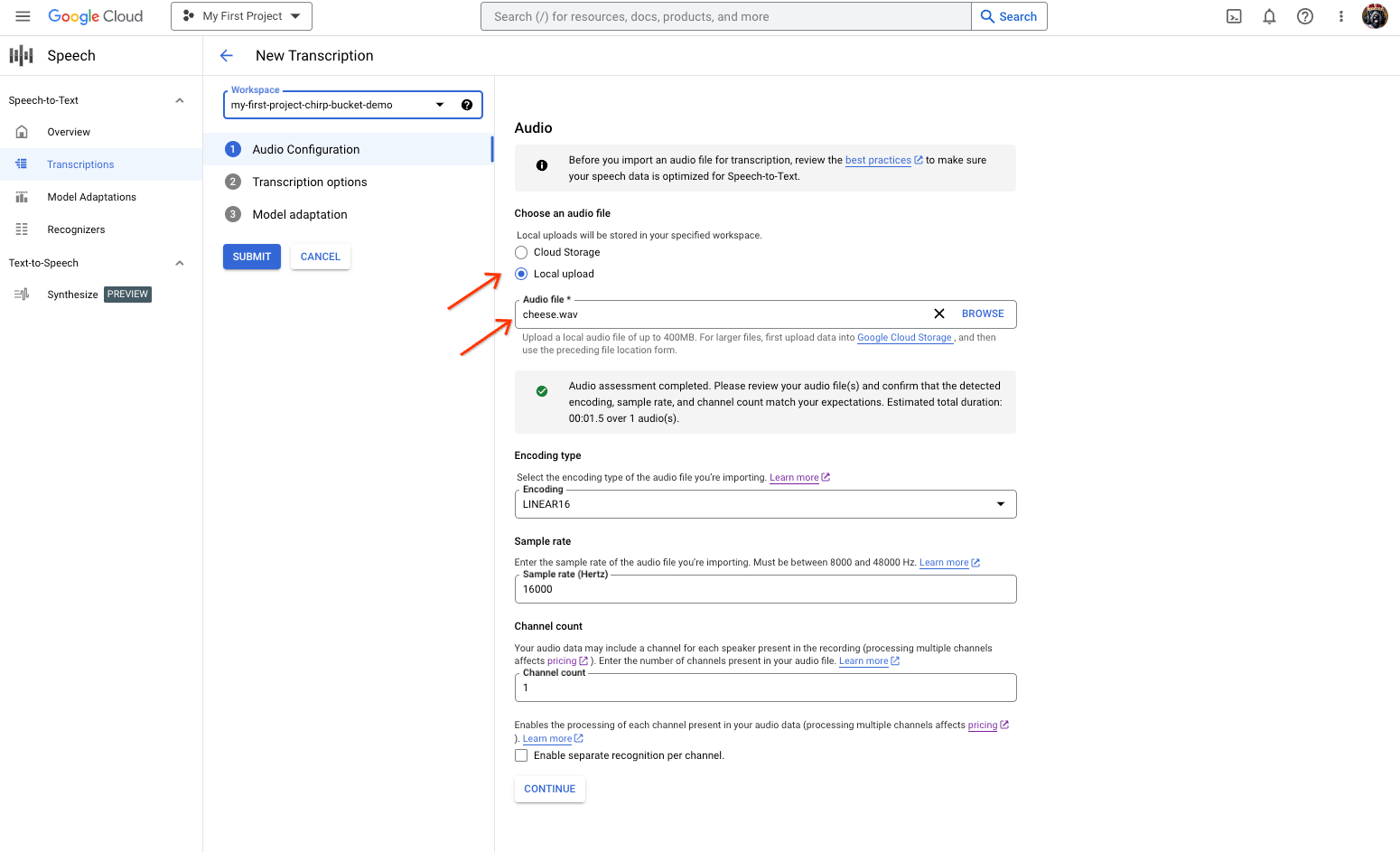
A página de criação de transcrições de conversão de voz em texto, que mostra a seleção ou o carregamento de ficheiros. Na página Nova transcrição, selecione o ficheiro de áudio carregando-o (Carregamento local) ou especificando um ficheiro do Cloud Storage existente (Armazenamento na nuvem).
Clique em Continuar para aceder às Opções de transcrição.
Selecione o idioma falado que planeia usar para o reconhecimento com o Chirp a partir do reconhecedor criado anteriormente.
No menu pendente do modelo, selecione chirp_3.
No menu pendente Reconhecedor, selecione o reconhecedor que acabou de criar.
Clique em Enviar para executar o seu primeiro pedido de reconhecimento através da API
chirp_3.
Veja o resultado da transcrição do Chirp 3.
Na página Transcrição, clique no nome da transcrição para ver o respetivo resultado.
Na página Detalhes da transcrição, veja o resultado da transcrição e, opcionalmente, ouça o áudio no navegador.