
Chirp 3 è l'ultima generazione di modelli generativi multilingue specifici per il riconoscimento vocale automatico (ASR) di Google, progettati per soddisfare le esigenze degli utenti in base al feedback e all'esperienza. Chirp 3 offre maggiore precisione e velocità rispetto ai modelli Chirp precedenti e fornisce la diarizzazione e il rilevamento automatico della lingua.
Dettagli modello
Chirp 3: la trascrizione è disponibile esclusivamente nell'API Speech-to-Text V2.
Identificatori modello
Puoi utilizzare Chirp 3: Trascrizione come qualsiasi altro modello specificando l'identificatore del modello appropriato nella richiesta di riconoscimento quando utilizzi l'API o il nome del modello nella console Google Cloud . Specifica l'identificatore appropriato nel riconoscimento.
| Modello | Identificatore modello |
|---|---|
| Chirp 3 | chirp_3 |
Metodi dell'API
Non tutti i metodi di riconoscimento supportano gli stessi set di disponibilità delle lingue, poiché Chirp 3 è disponibile nell'API Speech-to-Text V2, supporta i seguenti metodi di riconoscimento:
| Versione API | Metodo API | Assistenza |
|---|---|---|
| V2 | Speech.StreamingRecognize (ideale per lo streaming e l'audio in tempo reale) | Supportato |
| V2 | Speech.Recognize (ideale per audio di durata inferiore a un minuto) | Supportato |
| V2 | Speech.BatchRecognize (ideale per audio lunghi da 1 minuto a 1 ora in generale, ma fino a 20 minuti con il timestamp a livello di parola attivato) | Supportato |
Disponibilità a livello di regione
Chirp 3 è disponibile nelle seguenti regioni Google Cloud , ma ne sono previste altre:
| ZonaGoogle Cloud | Stato del lancio |
|---|---|
us (multi-region) |
GA |
eu (multi-region) |
GA |
asia-northeast1 |
Anteprima |
asia-southeast1 |
Anteprima |
asia-south1 |
Anteprima |
europe-west2 |
Anteprima |
europe-west3 |
Anteprima |
northamerica-northeast1 |
Anteprima |
Utilizzando l'API Locations come spiegato qui, puoi trovare l'elenco più recente di regioni, lingue, impostazioni internazionali e funzionalità supportate per ogni modello di trascrizione. Google Cloud
Lingue disponibili per la trascrizione
Chirp 3 supporta la trascrizione in StreamingRecognize, Recognize e BatchRecognize nelle seguenti lingue:
| Lingua | BCP-47 Code |
Idoneità al lancio |
| Catalano (Spagna) | ca-ES | GA |
| Cinese semplificato (Cina) | cmn-Hans-CN | GA |
| Croato (Croazia) | hr-HR | GA |
| Danese (Danimarca) | da-DK | GA |
| Olandese (Paesi Bassi) | nl-NL | GA |
| Inglese (Australia) | en-AU | GA |
| Inglese (India) | en-IN | GA |
| Inglese (Regno Unito) | en-GB | GA |
| Inglese (Stati Uniti) | en-US | GA |
| Finlandese (Finlandia) | fi-FI | GA |
| Francese (Canada) | fr-CA | GA |
| Francese (Francia) | fr-FR | GA |
| Tedesco (Germania) | de-DE | GA |
| Greco (Grecia) | el-GR | GA |
| Hindi (India) | hi-IN | GA |
| Italiano (Italia) | it-IT | GA |
| Giapponese (Giappone) | ja-JP | GA |
| Coreano (Corea) | ko-KR | GA |
| Polacco (Polonia) | pl-PL | GA |
| Portoghese (Brasile) | pt-BR | GA |
| Portoghese (Portogallo) | pt-PT | GA |
| Rumeno (Romania) | ro-RO | GA |
| Russo (Russia) | ru-RU | GA |
| Spagnolo (Spagna) | es-ES | GA |
| Spagnolo (Stati Uniti) | es-US | GA |
| Svedese (Svezia) | sv-SE | GA |
| Turco (Turchia) | tr-TR | GA |
| Ucraino (Ucraina) | uk-UA | GA |
| Vietnamita (Vietnam) | vi-VN | GA |
| Afrikaans (Sudafrica) | af-ZA | Anteprima |
| Albanese (Albania) | sq-AL | Anteprima |
| Amarico (Etiopia) | am-ET | Anteprima |
| Arabo (Algeria) | ar-DZ | Anteprima |
| Arabo (Bahrain) | ar-BH | Anteprima |
| Arabo (Egitto) | ar-EG | Anteprima |
| Arabo (Israele) | ar-IL | Anteprima |
| Arabo (Giordania) | ar-JO | Anteprima |
| Arabo (Kuwait) | ar-KW | Anteprima |
| Arabo (Libano) | ar-LB | Anteprima |
| Arabo (Mauritania) | ar-MR | Anteprima |
| Arabo (Marocco) | ar-MA | Anteprima |
| Arabo (Oman) | ar-OM | Anteprima |
| Arabo (Qatar) | ar-QA | Anteprima |
| Arabo (Arabia Saudita) | ar-SA | Anteprima |
| Arabo (Stato di Palestina) | ar-PS | Anteprima |
| Arabo (Siria) | ar-SY | Anteprima |
| Arabo (Tunisia) | ar-TN | Anteprima |
| Arabo (Emirati Arabi Uniti) | ar-AE | Anteprima |
| Arabo (Yemen) | ar-YE | Anteprima |
| Arabo | ar-XA | Anteprima |
| Armeno (Armenia) | hy-AM | Anteprima |
| Assamese (India) | as-IN | Anteprima |
| Asturiano (Spagna) | ast-ES | Anteprima |
| Azero (Azerbaigian) | az-AZ | Anteprima |
| Basco (Spagna) | eu-ES | Anteprima |
| Bengalese (Bangladesh) | bn-BD | Anteprima |
| Bengalese (India) | bn-IN | Anteprima |
| Bulgaro (Bulgaria) | bg-BG | Anteprima |
| Birmano (Myanmar) | my-MM | Anteprima |
| Curdo centrale (Iraq) | ar-IQ | Anteprima |
| Cinese, cantonese (Hong Kong, tradizionale) | yue-Hant-HK | Anteprima |
| Cinese, mandarino (tradizionale, Taiwan) | cmn-Hant-TW | Anteprima |
| Ceco (Repubblica Ceca) | cs-CZ | Anteprima |
| Inglese (Filippine) | en-PH | Anteprima |
| Estone (Estonia) | et-EE | Anteprima |
| Filippino (Filippine) | fil-PH | Anteprima |
| Galiziano (Spagna) | gl-ES | Anteprima |
| Georgiano (Georgia) | ka-GE | Anteprima |
| Gujarati (India) | gu-IN | Anteprima |
| Hausa (Nigeria) | ha-NG | Anteprima |
| Ebraico (Israele) | iw-IL | Anteprima |
| Ungherese (Ungheria) | hu-HU | Anteprima |
| Islandese (Islanda) | is-IS | Anteprima |
| Indonesiano (Indonesia) | id-ID | Anteprima |
| Giavanese (Indonesia) | jv-ID | Anteprima |
| Kannada (India) | kn-IN | Anteprima |
| Kazako (Kazakistan) | kk-KZ | Anteprima |
| Khmer (Cambogia) | km-KH | Anteprima |
| Kirghizistan | ky-KG | Anteprima |
| Lao (Laos) | lo-LA | Anteprima |
| Lettone (Lettonia) | lv-LV | Anteprima |
| Lituano (Lituania) | lt-LT | Anteprima |
| Lussemburghese (Lussemburgo) | lb-LU | Anteprima |
| Macedone (Macedonia del Nord) | mk-MK | Anteprima |
| Malese (Malaysia) | ms-MY | Anteprima |
| Malayalam (India) | ml-IN | Anteprima |
| Maltese (Malta) | mt-MT | Anteprima |
| Maori (Nuova Zelanda) | mi-NZ | Anteprima |
| Marathi (India) | mr-IN | Anteprima |
| Mongolo (Mongolia) | mn-MN | Anteprima |
| Nepalese (Nepal) | ne-NP | Anteprima |
| Sotho del Nord (Sudafrica) | nso-ZA | Anteprima |
| Norvegese (Norvegia) | no-NO | Anteprima |
| Oriya (India) | or-IN | Anteprima |
| Persiano (Iran) | fa-IR | Anteprima |
| Punjabi (gurmukhi, India) | pa-Guru-IN | Anteprima |
| Serbo (Serbia) | sr-RS | Anteprima |
| Slovacco (Slovacchia) | sk-SK | Anteprima |
| Sloveno (Slovenia) | sl-SI | Anteprima |
| Spagnolo (Messico) | es-MX | Anteprima |
| Swahili (Kenya) | sw-KE | Anteprima |
| Swahili | sw | Anteprima |
| Tamil (India) | ta-IN | Anteprima |
| Telugu (India) | te-IN | Anteprima |
| Thailandese (Thailandia) | th-TH | Anteprima |
| Uzbeko (Uzbekistan) | uz-UZ | Anteprima |
| Gallese (Regno Unito) | cy-GB | Anteprima |
| Wolof (Senegal) | wo-SN | Anteprima |
| Xhosa (Sudafrica) | xh-ZA | Anteprima |
| Yoruba (Nigeria) | yo-NG | Anteprima |
| Zulu (Sudafrica) | zu-ZA | Anteprima |
Lingue disponibili per la diarizzazione
Chirp 3 supporta la trascrizione e la diarizzazione solo in BatchRecognize e Recognize nelle seguenti lingue:
| Lingua | Codice BCP-47 |
| Cinese semplificato (Cina) | cmn-Hans-CN |
| Tedesco (Germania) | de-DE |
| Inglese (Regno Unito) | en-GB |
| Inglese (India) | en-IN |
| Inglese (Stati Uniti) | en-US |
| Spagnolo (Spagna) | es-ES |
| Spagnolo (Stati Uniti) | es-US |
| Francese (Canada) | fr-CA |
| Francese (Francia) | fr-FR |
| Hindi (India) | hi-IN |
| Italiano (Italia) | it-IT |
| Giapponese (Giappone) | ja-JP |
| Coreano (Corea) | ko-KR |
| Portoghese (Brasile) | pt-BR |
Supporto e limitazioni delle funzionalità
Chirp 3 supporta le seguenti funzionalità:
| Funzionalità | Descrizione | Fase di lancio |
|---|---|---|
| Punteggiatura automatica | Vengono generati automaticamente dal modello e possono essere disattivati facoltativamente. | GA |
| Maiuscole automatiche | Vengono generati automaticamente dal modello e possono essere disattivati facoltativamente. | GA |
| Timestamp a livello di enunciato | Generato automaticamente dal modello. Disponibile solo in Speech.StreamingRecognize |
GA |
| Speaker Diarization | Identifica automaticamente i diversi speaker in un campione audio a un solo canale. Disponibile solo in Speech.BatchRecognize |
GA |
| Adattamento vocale (biasing) | Fornisce suggerimenti al modello sotto forma di frasi o parole per migliorare l'accuratezza del riconoscimento di termini specifici o nomi propri. | GA |
| Trascrizione audio indipendente dalla lingua | Deduce e trascrive automaticamente nella lingua più diffusa. | GA |
Chirp 3 non supporta le seguenti funzionalità:
| Funzionalità | Descrizione |
|---|---|
| Timestamp a livello di parola | Generati automaticamente dal modello e possono essere abilitati facoltativamente, il che comporta un certo degrado della trascrizione. Disponibile solo in Speech.Recognize e Speech.BatchRecognize |
| Punteggi di confidenza a livello di parola | L'API restituisce un valore, ma non si tratta di un vero e proprio punteggio di confidenza. |
Trascrivere utilizzando Chirp 3
Scopri come utilizzare Chirp 3 per le attività di trascrizione.
Esegui il riconoscimento vocale di audio in streaming
Python
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
REGION = "us"
def transcribe_streaming_chirp3(
audio_file: str
) -> cloud_speech.StreamingRecognizeResponse:
"""Transcribes audio from audio file stream using the Chirp 3 model of Google Cloud Speech-to-Text v2 API.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API V2 containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint=f"{REGION}-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
content = f.read()
# In practice, stream should be a generator yielding chunks of audio data
chunk_length = len(content) // 5
stream = [
content[start : start + chunk_length]
for start in range(0, len(content), chunk_length)
]
audio_requests = (
cloud_speech.StreamingRecognizeRequest(audio=audio) for audio in stream
)
recognition_config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_3",
)
streaming_config = cloud_speech.StreamingRecognitionConfig(
config=recognition_config
)
config_request = cloud_speech.StreamingRecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/{REGION}/recognizers/_",
streaming_config=streaming_config,
)
def requests(config: cloud_speech.RecognitionConfig, audio: list) -> list:
yield config
yield from audio
# Transcribes the audio into text
responses_iterator = client.streaming_recognize(
requests=requests(config_request, audio_requests)
)
responses = []
for response in responses_iterator:
responses.append(response)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return responses
Esegui il riconoscimento vocale sincrono
Python
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
REGION = "us"
def transcribe_sync_chirp3(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Transcribes an audio file using the Chirp 3 model of Google Cloud Speech-to-Text V2 API.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint=f"{REGION}-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_3",
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/{REGION}/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return response
Esecuzione del riconoscimento vocale batch
Python
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
REGION = "us"
def transcribe_batch_3(
audio_uri: str,
) -> cloud_speech.BatchRecognizeResults:
"""Transcribes an audio file from a Google Cloud Storage URI using the Chirp 3 model of Google Cloud Speech-to-Text v2 API.
Args:
audio_uri (str): The Google Cloud Storage URI of the input audio file.
E.g., gs://[BUCKET]/[FILE]
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint=f"{REGION}-speech.googleapis.com",
)
)
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_3",
)
file_metadata = cloud_speech.BatchRecognizeFileMetadata(uri=audio_uri)
request = cloud_speech.BatchRecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/{REGION}/recognizers/_",
config=config,
files=[file_metadata],
recognition_output_config=cloud_speech.RecognitionOutputConfig(
inline_response_config=cloud_speech.InlineOutputConfig(),
),
)
# Transcribes the audio into text
operation = client.batch_recognize(request=request)
print("Waiting for operation to complete...")
response = operation.result(timeout=120)
for result in response.results[audio_uri].transcript.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return response.results[audio_uri].transcript
Utilizzare le funzionalità di Chirp 3
Scopri come utilizzare le ultime funzionalità con esempi di codice:
Eseguire una trascrizione indipendente dalla lingua
Chirp 3 è in grado di identificare e trascrivere automaticamente la lingua dominante parlata nell'audio, il che è essenziale per le applicazioni multilingue. Per ottenere questo risultato, imposta language_codes=["auto"] come indicato nell'esempio di codice:
Python
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
REGION = "us"
def transcribe_sync_chirp3_auto_detect_language(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Transcribes an audio file and auto-detect spoken language using Chirp 3.
Please see https://cloud.google.com/speech-to-text/docs/encoding for more
information on which audio encodings are supported.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint=f"{REGION}-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["auto"], # Set language code to auto to detect language.
model="chirp_3",
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/{REGION}/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
print(f"Detected Language: {result.language_code}")
return response
Eseguire una trascrizione con limitazioni linguistiche
Chirp 3 può identificare e trascrivere automaticamente la lingua dominante in un file audio. Puoi anche impostare una condizione per località specifiche che prevedi, ad esempio: ["en-US", "fr-FR"], che concentrerebbe le risorse del modello sulle lingue più probabili per risultati più affidabili, come mostrato nell'esempio di codice:
Python
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
REGION = "us"
def transcribe_sync_3_auto_detect_language(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Transcribes an audio file and auto-detect spoken language using Chirp 3.
Please see https://cloud.google.com/speech-to-text/docs/encoding for more
information on which audio encodings are supported.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint=f"{REGION}-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US", "fr-FR"], # Set language codes of the expected spoken locales
model="chirp_3",
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/{REGION}/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
print(f"Detected Language: {result.language_code}")
return response
Eseguire la trascrizione e la diarizzazione degli interlocutori
Utilizza Chirp 3 per le attività di trascrizione e diarizzazione.
Python
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
REGION = "us"
def transcribe_batch_chirp3(
audio_uri: str,
) -> cloud_speech.BatchRecognizeResults:
"""Transcribes an audio file from a Google Cloud Storage URI using the Chirp 3 model of Google Cloud Speech-to-Text V2 API.
Args:
audio_uri (str): The Google Cloud Storage URI of the input
audio file. E.g., gs://[BUCKET]/[FILE]
Returns:
cloud_speech.RecognizeResponse: The response from the
Speech-to-Text API containing the transcription results.
"""
# Instantiates a client.
client = SpeechClient(
client_options=ClientOptions(
api_endpoint=f"{REGION}-speech.googleapis.com",
)
)
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"], # Use "auto" to detect language.
model="chirp_3",
features=cloud_speech.RecognitionFeatures(
# Enable diarization by setting empty diarization configuration.
diarization_config=cloud_speech.SpeakerDiarizationConfig(),
),
)
file_metadata = cloud_speech.BatchRecognizeFileMetadata(uri=audio_uri)
request = cloud_speech.BatchRecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/{REGION}/recognizers/_",
config=config,
files=[file_metadata],
recognition_output_config=cloud_speech.RecognitionOutputConfig(
inline_response_config=cloud_speech.InlineOutputConfig(),
),
)
# Creates audio transcription job.
operation = client.batch_recognize(request=request)
print("Waiting for transcription job to complete...")
response = operation.result(timeout=120)
for result in response.results[audio_uri].transcript.results:
print(f"Transcript: {result.alternatives[0].transcript}")
print(f"Detected Language: {result.language_code}")
print(f"Speakers per word: {result.alternatives[0].words}")
return response.results[audio_uri].transcript
Migliorare l'accuratezza con l'adattamento del modello
Chirp 3 può migliorare l'accuratezza della trascrizione per il tuo audio specifico utilizzando l'adattamento del modello. In questo modo, puoi fornire un elenco di parole e frasi specifiche, aumentando la probabilità che il modello le riconosca. È particolarmente utile per termini specifici del dominio, nomi propri o vocabolario unico.
Python
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
REGION = "us"
def transcribe_sync_chirp3_model_adaptation(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Transcribes an audio file using the Chirp 3 model with adaptation, improving accuracy for specific audio characteristics or vocabulary.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint=f"{REGION}-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_3",
# Use model adaptation
adaptation=cloud_speech.SpeechAdaptation(
phrase_sets=[
cloud_speech.SpeechAdaptation.AdaptationPhraseSet(
inline_phrase_set=cloud_speech.PhraseSet(phrases=[
{
"value": "alphabet",
},
{
"value": "cell phone service",
}
])
)
]
)
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/{REGION}/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return response
Abilita il riduttore del rumore
Chirp 3 può migliorare la qualità audio riducendo il rumore di fondo. Puoi migliorare i risultati in ambienti rumorosi attivando il denoiser integrato.
L'impostazione denoiser_audio=true può aiutarti a ridurre la musica di sottofondo o i rumori
come la pioggia e il traffico stradale.
Python
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
REGION = "us"
def transcribe_sync_chirp3_with_timestamps(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Transcribes an audio file using the Chirp 3 model of Google Cloud Speech-to-Text v2 API, which provides word-level timestamps for each transcribed word.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint=f"{REGION}-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_3",
denoiser_config={
denoise_audio: True,
snr_threshold: 0.0, # snr_threshold is deprecated in Chirp3; set to 0.0 to maintain compatibility.
}
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/{REGION}/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return response
Regolare la sensibilità dell'endpoint
L'API Cloud Speech-to-Text ti consente di controllare il compromesso tra latenza e precisione per le applicazioni di streaming e in tempo reale per Chirp 3. Per impostazione predefinita, il modello di riconoscimento attende un breve periodo di silenzio dopo il rilevamento del parlato per assicurarsi che l'utente abbia terminato una frase o un'espressione completa. In questo modo si garantisce la massima precisione, ma si introduce un piccolo ritardo nella risposta finale.
endpointing_sensitivity può essere regolato per applicazioni sensibili al tempo, come
comandi vocali o bot vocali, per finalizzare i risultati più rapidamente.
Livelli di sensibilità
La sensibilità dell'endpoint può essere configurata su uno dei seguenti livelli in base al caso d'uso:
ENDPOINTING_SENSITIVITY_STANDARD(valore predefinito): l'impostazione standard che bilancia latenza e precisione. È ottimizzato per la maggior parte dei casi d'uso, tra cui la dettatura di testi lunghi e la conversazione naturale. Il modello attende per assicurarsi che l'enunciato sia completo prima di finalizzare il risultato.ENDPOINTING_SENSITIVITY_SHORT: ottimizzato per espressioni brevi, come frasi o comandi singoli, ad esempio "Ricordami di chiamare il dentista domani". Questa impostazione riduce il tempo di attesa dopo il rilevamento del parlato, il che fornisce una risposta più rapida rispetto all'impostazione standard, mantenendo una precisione ragionevole a livello di frase.ENDPOINTING_SENSITIVITY_SUPERSHORT: ottimizzato per comandi molto brevi o singole parole, come "Sì", "No" o "Stop". Questa impostazione offre la latenza più bassa e finalizza il risultato immediatamente dopo aver rilevato la fine del discorso. È consigliato solo per le applicazioni in cui la velocità è fondamentale e le espressioni devono essere brevi.
Python
import time
from google.api_core.client_options import ClientOptions
from google.cloud import speech_v2
RATE = 16000
def transcribe_streaming(
project_id: str,
audio_file: str,
# 'us' is a multi-region that currently supports the 'chirp_3' model.
# Other valid regions include 'eu' or specific regions like 'asia-southeast1'.
region: str = "us"
):
recognizer_path = f"projects/{project_id}/locations/{region}/recognizers/_"
# Setup client with the correct regional endpoint
client = speech_v2.SpeechClient(
client_options=ClientOptions(
api_endpoint=f"{region}-speech.googleapis.com",
quota_project_id=project_id
)
)
recognition_config_obj = speech_v2.RecognitionConfig(
explicit_decoding_config=speech_v2.ExplicitDecodingConfig(
encoding=speech_v2.ExplicitDecodingConfig.AudioEncoding.LINEAR16,
sample_rate_hertz=RATE,
audio_channel_count=1,
),
language_codes=["en-US"],
model="chirp_3",
features=speech_v2.RecognitionFeatures(
enable_automatic_punctuation=True,
),
)
config_request = speech_v2.StreamingRecognizeRequest(
recognizer=recognizer_path,
streaming_config=speech_v2.StreamingRecognitionConfig(
config=recognition_config_obj,
streaming_features=speech_v2.StreamingRecognitionFeatures(
interim_results=False,
enable_voice_activity_events=True,
# Set sensitivity to SUPERSHORT (Low Latency)
endpointing_sensitivity=speech_v2.StreamingRecognitionFeatures.EndpointingSensitivity.ENDPOINTING_SENSITIVITY_SUPERSHORT,
),
)
)
def request_generator():
yield config_request
with open(audio_file, "rb") as f:
while chunk := f.read(4096):
yield speech_v2.StreamingRecognizeRequest(audio=chunk)
start_time = time.time()
print(f"Streaming audio to {region}-speech.googleapis.com...")
for response in client.streaming_recognize(requests=request_generator()):
if response.results:
for result in response.results:
if result.is_final:
print(f"Transcript: {result.alternatives[0].transcript}")
print(f"Time taken: {time.time() - start_time:.3f}s")
def main() -> None:
# TODO: Replace with your Project ID and File Path
PROJECT_ID = "your-project-id"
AUDIO_FILE_PATH = "path/to/your/audio.wav"
transcribe_streaming(
project_id=PROJECT_ID,
audio_file=AUDIO_FILE_PATH
)
if __name__ == "__main__":
main()
Utilizzare Chirp 3 nella console Google Cloud
- Registrati per creare un account Google Cloud e crea un progetto.
- Vai a Speech nella console Google Cloud .
- Se l'API non è abilitata, abilitala.
Assicurati di avere una console STT Workspace. Se non hai uno spazio di lavoro, devi crearne uno.
Vai alla pagina delle trascrizioni e fai clic su Nuova trascrizione.
Apri il menu a discesa Workspace e fai clic su Nuovo workspace per creare un workspace per la trascrizione.
Nella barra di navigazione Crea un nuovo spazio di lavoro, fai clic su Sfoglia.
Fai clic per creare un nuovo bucket.
Inserisci un nome per il bucket e fai clic su Continua.
Fai clic su Crea per creare il bucket Cloud Storage.
Una volta creato il bucket, fai clic su Seleziona per selezionarlo per l'utilizzo.
Fai clic su Crea per completare la creazione dello spazio di lavoro per la console dell'API Speech-to-Text V2.
Esegui una trascrizione sull'audio effettivo.
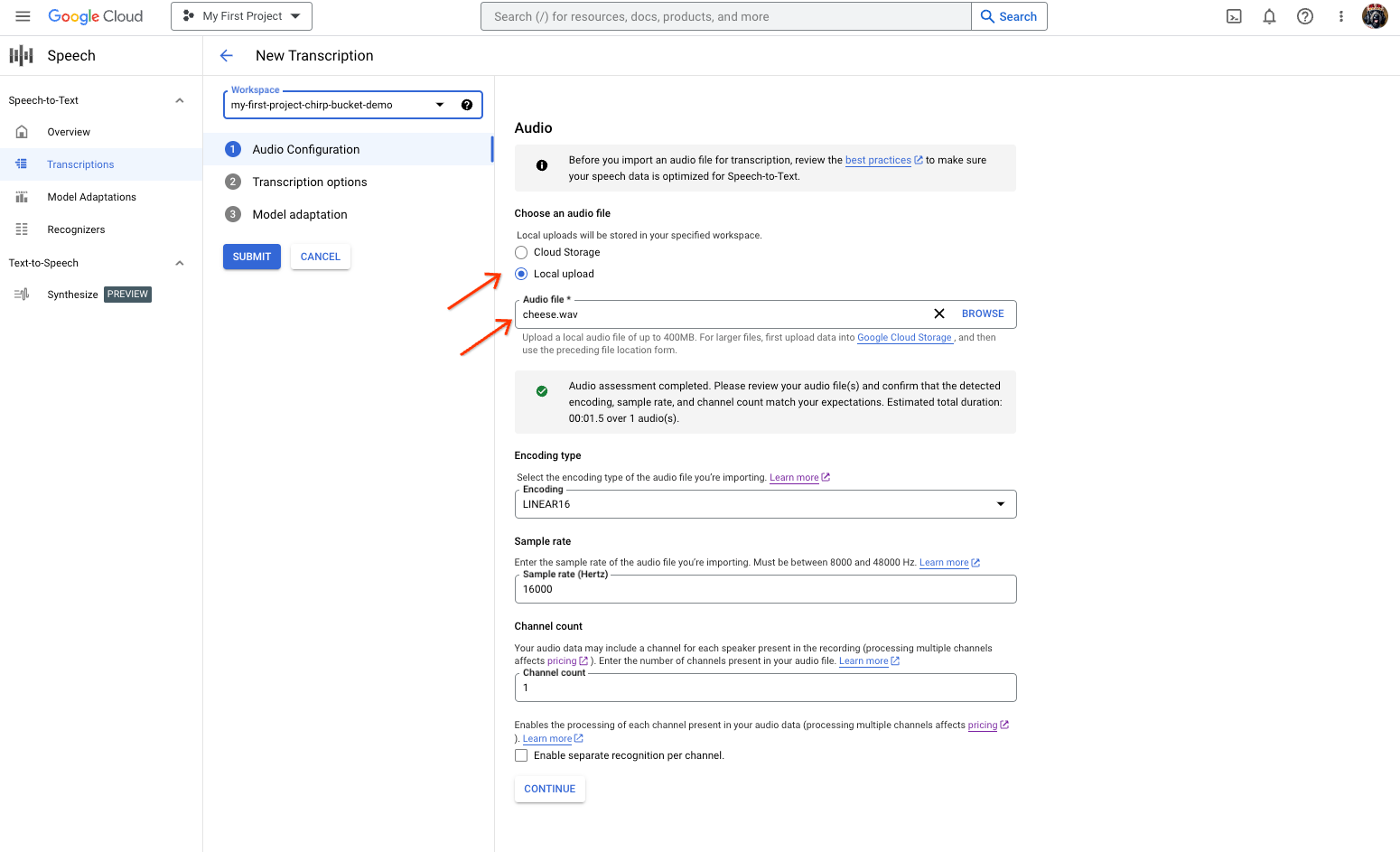
La pagina di creazione della trascrizione Speech-to-Text, che mostra la selezione o il caricamento dei file. Nella pagina Nuova trascrizione, seleziona il file audio tramite caricamento (Caricamento locale) o specificando un file Cloud Storage esistente (Cloud Storage).
Fai clic su Continua per passare alle Opzioni di trascrizione.
Seleziona la lingua parlata che prevedi di utilizzare per il riconoscimento con Chirp dal riconoscitore creato in precedenza.
Nel menu a discesa del modello, seleziona chirp_3.
Nel menu a discesa Riconoscitore, seleziona il riconoscitore appena creato.
Fai clic su Invia per eseguire la prima richiesta di riconoscimento utilizzando
chirp_3.
Visualizza il risultato della trascrizione di Chirp 3.
Nella pagina Trascrizioni, fai clic sul nome della trascrizione per visualizzarne il risultato.
Nella pagina Dettagli della trascrizione, visualizza il risultato della trascrizione e, se vuoi, riproduci l'audio nel browser.