
Chirp 2 ist die neueste Generation mehrsprachiger Modelle von Google für die automatische Spracherkennung. Sie wurden auf Grundlage von Feedback und Erfahrungen entwickelt, um Nutzeranforderungen zu erfüllen. Diese Generation bietet eine höhere Accuracy und Geschwindigkeit als das ursprüngliche Chirp-Modell sowie wichtige neue Funktionen wie Zeitstempel auf Wortebene, Modellanpassung und Sprachübersetzung.
Modelldetails
Chirp 2 ist ausschließlich in der Speech-to-Text API V2 verfügbar.
Modellbezeichnungen
Sie können Chirp 2 wie jedes andere Modell verwenden. Wenn Sie die API nutzen, geben Sie die entsprechende Modellbezeichnung in Ihrer Erkennungsanfrage an. Wenn Sie die Google Cloud Console nutzen, geben Sie den Modellnamen an.
| Modell | Modellbezeichnung |
|---|---|
| Chirp 2 | chirp_2 |
API-Methoden
Da Chirp 2 ausschließlich in der Speech-to-Text API V2 verfügbar ist, werden die folgenden Erkennungsmethoden unterstützt:
| Modell | Modellbezeichnung | Sprachunterstützung |
|---|---|---|
V2 |
Speech.StreamingRecognize (geeignet für Audiostreams und Echtzeit-Audioinhalte) |
Begrenzt* |
V2 |
Speech.Recognize (geeignet für kurze Audioinhalte, < 1 Min.) |
Wie Chirp |
V2 |
Speech.BatchRecognize (geeignet für längere Audioinhalte, 1 Min. bis 8 Std.) |
Wie Chirp |
* Eine aktuelle Liste der unterstützten Sprachen und Funktionen für jedes Transkriptionsmodell können Sie jederzeit mit der Locations API abrufen.
Regionale Verfügbarkeit
Chirp 2 wird in den folgenden Regionen unterstützt:
| Google Cloud -Zone | Einführungsreife |
|---|---|
us-central1 |
GA |
europe-west4 |
GA |
asia-southeast1 |
GA |
Die aktuelle Liste der unterstützten Google Cloud -Regionen sowie der unterstützten Sprachen und Funktionen für jedes Transkriptionsmodell können Sie jederzeit mit der Locations API abrufen, wie auf dieser Seite erklärt wird.
Verfügbare Sprachen für die Transkription
Chirp 2 unterstützt die Transkription für die Spracherkennungsmethoden StreamingRecognize, Recognize und BatchRecognize. Die Sprachunterstützung variiert jedoch je nach der verwendeten Methode. BatchRecognize bietet die umfangreichste Sprachunterstützung.
StreamingRecognize unterstützt die folgenden Sprachen:
| Sprache | BCP-47-Code |
|---|---|
| Chinesisch, vereinfacht (China) | cmn-Hans-CN |
| Chinesisch, traditionell (Taiwan) | cmn-Hant-TW |
| Chinesisch, Kantonesisch (traditionell, Hongkong) | yue-Hant-HK |
| Englisch (Australien) | en-AU |
| Englisch (Indien) | en-IN |
| Englisch (Vereinigtes Königreich) | en-GB |
| Englisch (USA) | en-US |
| Französisch (Kanada) | fr-CA |
| Französisch (Frankreich) | fr-FR |
| Deutsch (Deutschland) | de-DE |
| Italienisch (Italien) | it-IT |
| Japanisch (Japan) | ja-JP |
| Koreanisch (Südkorea) | ko-KR |
| Portugiesisch (Brasilien) | pt-BR |
| Spanisch (Spanien) | es-ES |
| Spanisch (USA) | es-US |
Verfügbare Sprachen für die Übersetzung
Dies sind die unterstützten Sprachen für die Sprachübersetzung. Die Sprachunterstützung von Chirp 2 für die Übersetzung ist nicht symmetrisch. Das bedeutet, dass zwar möglicherweise von Sprache A in Sprache B übersetzt werden kann, aber nicht selbstverständlich auch von Sprache B in Sprache A. Die folgenden Sprachpaare werden für die Sprachübersetzung unterstützt.
Übersetzung ins Englische:
| Ausgangssprache -> Zielsprache | Ausgangssprache -> Zielsprache (Codes) |
|---|---|
| Arabisch (Ägypten) -> Englisch | ar-EG -> en-US |
| Arabisch (Golfregion) -> Englisch | ar-x-gulf -> en-US |
| Arabisch (Levantinisch) -> Englisch | ar-x-levant -> en-US |
| Arabisch (Maghreb) -> Englisch | ar-x-maghrebi -> en-US |
| Katalanisch (Spanien) -> Englisch | ca-ES -> en-US |
| Walisisch (Vereinigtes Königreich) -> Englisch | cy-GB -> en-US |
| Deutsch (Deutschland) -> Englisch | de-DE -> en-US |
| Spanisch (Lateinamerika) -> Englisch | es-419 -> en-US |
| Spanisch (Spanien) -> Englisch | es-ES -> en-US |
| Spanisch (USA) -> Englisch | es-US -> en-US |
| Estnisch (Estland) -> Englisch | et-EE -> en-US |
| Französisch (Kanada) -> Englisch | fr-CA -> en-US |
| Französisch (Frankreich) -> Englisch | fr-FR -> en-US |
| Persisch (Iran) -> Englisch | fa-IR -> en-US |
| Indonesisch (Indonesien) -> Englisch | id-ID -> en-US |
| Italienisch (Italien) -> Englisch | it-IT -> en-US |
| Japanisch (Japan) -> Englisch | ja-JP -> en-US |
| Lettisch (Lettland) -> Englisch | lv-LV -> en-US |
| Mongolisch (Mongolei) -> Englisch | mn-MN -> en-US |
| Niederländisch (Niederlande) -> Englisch | nl-NL -> en-US |
| Portugiesisch (Brasilien) -> Englisch | pt-BR -> en-US |
| Russisch (Russland) -> Englisch | ru-RU -> en-US |
| Slowenisch (Slowenien) -> Englisch | sl-SI -> en-US |
| Schwedisch (Schweden) -> Englisch | sv-SE -> en-US |
| Tamil (Indien) -> Englisch | ta-IN -> en-US |
| Türkisch (Türkei) -> Englisch | tr-TR -> en-US |
| Chinesisch, vereinfacht (China) -> Englisch | cmn-Hans-CN -> en-US |
Übersetzung aus dem Englischen:
| Ausgangssprache -> Zielsprache | Ausgangssprache -> Zielsprache (Codes) |
|---|---|
| Englisch -> Arabisch (Ägypten) | en-US -> ar-EG |
| Englisch -> Arabisch (Golfregion) | en-US -> ar-x-gulf |
| Englisch -> Arabisch (Levantinisch) | en-US -> ar-x-levant |
| Englisch -> Arabisch (Maghreb) | en-US -> ar-x-maghrebi |
| Englisch -> Katalanisch (Spanien) | en-US -> ca-ES |
| Englisch -> Walisisch (Vereinigtes Königreich) | en-US -> cy-GB |
| Englisch -> Deutsch (Deutschland) | en-US -> de-DE |
| Englisch -> Estnisch (Estland) | en-US -> et-EE |
| Englisch -> Persisch (Iran) | en-US -> fa-IR |
| Englisch -> Indonesisch (Indonesien) | en-US -> id-ID |
| Englisch -> Japanisch (Japan) | en-US -> ja-JP |
| Englisch -> Lettisch (Lettland) | en-US -> lv-LV |
| Englisch -> Mongolisch (Mongolei) | en-US -> mn-MN |
| Englisch -> Slowenisch (Slowenien) | en-US -> sl-SI |
| Englisch -> Schwedisch (Schweden) | en-US -> sv-SE |
| Englisch -> Tamil (Indien) | en-US -> ta-IN |
| Englisch -> Türkisch (Türkei) | en-US -> tr-TR |
| Englisch -> Chinesisch, vereinfacht (China) | en-US -> cmn-Hans-CN |
Funktionsunterstützung und Einschränkungen
Chirp 2 unterstützt die folgenden Funktionen:
| Funktion | Beschreibung |
|---|---|
| Automatische Zeichensetzung | Wird automatisch vom Modell generiert und kann optional deaktiviert werden. |
| Automatische Großschreibung | Wird automatisch vom Modell generiert und kann optional deaktiviert werden. |
| Sprachanpassung (Gewichtung) | Gibt dem Modell Hinweise in Form von einfachen Wörtern oder Wortgruppen, um die Accuracy der Erkennung für bestimmte Begriffe oder Eigennamen zu verbessern. Klassentokens oder benutzerdefinierte Klassen werden nicht unterstützt. |
| Zeitangaben für Wörter (Zeitstempel) | Werden automatisch vom Modell generiert und können optional aktiviert werden. Wenn diese Funktion aktiviert wird, können Qualität und Geschwindigkeit der Transkription etwas abnehmen. |
| Filter für vulgäre Sprache | Erkennt vulgäre Wörter und gibt nur den ersten Buchstaben gefolgt von Sternchen im Transkript zurück (z. B. f***). |
| Sprachunabhängige Audiotranskription | Das Modell leitet die in der Audiodatei gesprochene Sprache automatisch ab und transkribiert die Inhalte in der am häufigsten verwendeten Sprache. |
| Sprachspezifische Übersetzung | Das Modell übersetzt automatisch aus der gesprochenen Sprache in die Zielsprache. |
| Erzwungene Normalisierung | Wenn dies im Anfragetext definiert wird, kann die API bestimmte Begriffe oder Wortgruppen ersetzen, um die Konsistenz der Transkription zu unterstützen. |
| Konfidenzwerte auf Wortebene | Die API gibt einen Wert zurück, der jedoch kein echter Konfidenzwert ist. Bei einer Übersetzung werden keine Konfidenzwerte zurückgegeben. |
| Rauschunterdrückung und SNR-Filter | Entfernt Rauschen aus den Audiodaten, bevor sie an das Modell gesendet werden. Filtert Audiosegmente heraus, deren Signal-Rausch-Verhältnis (Signal-to-Noise Ratio, SNR) unter dem angegebenen Grenzwert liegt. |
Chirp 2 unterstützt die folgenden Funktionen nicht:
| Funktion | Beschreibung |
|---|---|
| Sprecherbestimmung | Nicht unterstützt |
| Spracherkennung | Nicht unterstützt |
Mit Chirp 2 transkribieren
Erfahren Sie, wie Sie mit Chirp 2 transkribieren und übersetzen können.
Streamingspracherkennung durchführen
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
def transcribe_streaming_chirp2(
audio_file: str
) -> cloud_speech.StreamingRecognizeResponse:
"""Transcribes audio from audio file stream using the Chirp 2 model of Google Cloud Speech-to-Text V2 API.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API V2 containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint="us-central1-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
content = f.read()
# In practice, stream should be a generator yielding chunks of audio data
chunk_length = len(content) // 5
stream = [
content[start : start + chunk_length]
for start in range(0, len(content), chunk_length)
]
audio_requests = (
cloud_speech.StreamingRecognizeRequest(audio=audio) for audio in stream
)
recognition_config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_2",
)
streaming_config = cloud_speech.StreamingRecognitionConfig(
config=recognition_config
)
config_request = cloud_speech.StreamingRecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/us-central1/recognizers/_",
streaming_config=streaming_config,
)
def requests(config: cloud_speech.RecognitionConfig, audio: list) -> list:
yield config
yield from audio
# Transcribes the audio into text
responses_iterator = client.streaming_recognize(
requests=requests(config_request, audio_requests)
)
responses = []
for response in responses_iterator:
responses.append(response)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return responses
Synchrone Spracherkennung durchführen
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
def transcribe_sync_chirp2(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Transcribes an audio file using the Chirp 2 model of Google Cloud Speech-to-Text V2 API.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint="us-central1-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_2",
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/us-central1/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return response
Batch-Spracherkennung durchführen
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
def transcribe_batch_chirp2(
audio_uri: str,
) -> cloud_speech.BatchRecognizeResults:
"""Transcribes an audio file from a Google Cloud Storage URI using the Chirp 2 model of Google Cloud Speech-to-Text V2 API.
Args:
audio_uri (str): The Google Cloud Storage URI of the input audio file.
E.g., gs://[BUCKET]/[FILE]
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint="us-central1-speech.googleapis.com",
)
)
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_2",
)
file_metadata = cloud_speech.BatchRecognizeFileMetadata(uri=audio_uri)
request = cloud_speech.BatchRecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/us-central1/recognizers/_",
config=config,
files=[file_metadata],
recognition_output_config=cloud_speech.RecognitionOutputConfig(
inline_response_config=cloud_speech.InlineOutputConfig(),
),
)
# Transcribes the audio into text
operation = client.batch_recognize(request=request)
print("Waiting for operation to complete...")
response = operation.result(timeout=120)
for result in response.results[audio_uri].transcript.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return response.results[audio_uri].transcript
Chirp 2-Funktionen verwenden
Hier erfahren Sie, wie Sie die neuesten Funktionen einsetzen. Sehen Sie sich auch die Codebeispiele an.
Sprachunabhängige Transkription durchführen
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
def transcribe_sync_chirp2_auto_detect_language(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Transcribes an audio file and auto-detect spoken language using Chirp 2.
Please see https://cloud.google.com/speech-to-text/docs/encoding for more
information on which audio encodings are supported.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint="us-central1-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["auto"], # Set language code to auto to detect language.
model="chirp_2",
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/us-central1/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
print(f"Detected Language: {result.language_code}")
return response
Sprachübersetzung durchführen
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
def translate_sync_chirp2(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Translates an audio file using Chirp 2.
Args:
audio_file (str): Path to the local audio file to be translated.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the translated results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint="us-central1-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["fr-FR"], # Set language code to targeted to detect language.
translation_config=cloud_speech.TranslationConfig(target_language="fr-FR"), # Set target language code.
model="chirp_2",
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/us-central1/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Translated transcript: {result.alternatives[0].transcript}")
return response
Zeitstempel auf Wortebene aktivieren
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
def transcribe_sync_chirp2_with_timestamps(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Transcribes an audio file using the Chirp 2 model of Google Cloud Speech-to-Text V2 API, providing word-level timestamps for each transcribed word.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint="us-central1-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_2",
features=cloud_speech.RecognitionFeatures(
enable_word_time_offsets=True, # Enabling word-level timestamps
)
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/us-central1/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return response
Accuracy durch Modellanpassung verbessern
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
def transcribe_sync_chirp2_model_adaptation(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Transcribes an audio file using the Chirp 2 model with adaptation, improving accuracy for specific audio characteristics or vocabulary.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint="us-central1-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_2",
# Use model adaptation
adaptation=cloud_speech.SpeechAdaptation(
phrase_sets=[
cloud_speech.SpeechAdaptation.AdaptationPhraseSet(
inline_phrase_set=cloud_speech.PhraseSet(phrases=[
{
"value": "alphabet",
},
{
"value": "cell phone service",
}
])
)
]
)
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/us-central1/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return response
Details zur Rauschunterdrückung und zum SNR-Filter
Mit „denoiser_audio=true“ können Sie Hintergrundmusik oder Geräusche wie Regen und Straßenverkehr effektiv reduzieren. Die Rauschunterdrückung kann keine menschlichen Stimmen entfernen, die im Hintergrund zu hören sind.
Mit snr_threshold=X können Sie die Mindestlautstärke der Sprache festlegen, die für die Transkription erforderlich ist. So werden Audioinhalte, die keine Sprache enthalten, oder Hintergrundgeräusche herausgefiltert, um unerwünschten Text in den Ergebnissen zu vermeiden. Ein höherer Wert für snr_threshold bedeutet, dass der Nutzer lauter sprechen muss, damit das Modell die Äußerungen transkribiert.
Der SNR-Filter kann in Anwendungsfällen mit Streaming in Echtzeit verwendet werden, um zu vermeiden, dass unnötige Geräusche zur Transkription an ein Modell gesendet werden. Ein höherer Wert für diese Einstellung bedeutet, dass Ihre Stimme im Verhältnis zu den Hintergrundgeräuschen lauter sein muss, damit sie an das Transkriptionsmodell gesendet wird.
Die Konfiguration von snr_threshold steht in Wechselwirkung mit der Konfiguration von denoise_audio (true oder false). Wenn denoise_audio=true konfiguriert ist, werden Hintergrundgeräusche entfernt und Sprache wird klarer. Das gesamte SNR des Audioinhalts steigt.
Wenn in Ihrem Anwendungsfall nur die Stimme des Nutzers ohne andere Sprecher vorliegt, legen Sie denoise_audio=true fest. Das erhöht die Empfindlichkeit des SNR-Filters, damit andere Geräusche als Sprache herausgefiltert werden können. Wenn in Ihrem Anwendungsfall Personen im Hintergrund sprechen und Sie deren Transkription vermeiden möchten, legen Sie denoise_audio=false fest und senken Sie den SNR-Grenzwert.
Im Folgenden finden Sie empfohlene SNR-Grenzwerte. Es kann für snr_threshold ein geeigneter Wert zwischen 0 und 1000 festgelegt werden. Ein Wert von 0 bedeutet, dass nichts gefiltert wird, und 1000 bedeutet, dass alles gefiltert wird. Passen Sie den Wert an, wenn die empfohlene Einstellung nicht für Ihre Anforderungen geeignet ist.
| Audio-Rauschunterdrückung | SNR-Grenzwert | Sprachempfindlichkeit |
|---|---|---|
| true | 10.0 | hoch |
| true | 20.0 | mittel |
| true | 40.0 | niedrig |
| true | 100.0 | sehr niedrig |
| false | 0.5 | hoch |
| false | 1.0 | mittel |
| false | 2.0 | niedrig |
| false | 5.0 | sehr niedrig |
Rauschunterdrückung und SNR-Filter aktivieren
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
def transcribe_sync_chirp2_with_timestamps(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Transcribes an audio file using the Chirp 2 model of Google Cloud Speech-to-Text V2 API, providing word-level timestamps for each transcribed word.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint="us-central1-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_2",
denoiser_config={
denoise_audio: True,
# Medium snr threshold
snr_threshold: 20.0,
}
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/us-central1/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return response
Chirp 2 in der Google Cloud Console verwenden
- Registrieren Sie sich bei Google Cloud für ein Konto und erstellen Sie ein Projekt.
- Rufen Sie in der Google Cloud Console Sprache auf.
- Wenn die API nicht aktiviert ist, aktivieren Sie sie.
Sie benötigen einen Arbeitsbereich in der STT Console. Wenn Sie noch keinen Arbeitsbereich haben, erstellen Sie einen.
Rufen Sie die Seite Transkriptionen auf und klicken Sie auf Neue Transkription.
Öffnen Sie das Drop-down-Menü Arbeitsbereich und klicken Sie auf Neuer Arbeitsbereich, um einen Arbeitsbereich für die Transkription zu erstellen.
Klicken Sie in der Navigationsleiste Neuen Arbeitsbereich erstellen auf Durchsuchen.
Klicken Sie, um einen neuen Bucket zu erstellen.
Geben Sie einen Namen für den Bucket ein und klicken Sie auf Weiter.
Klicken Sie auf Erstellen, um den Cloud Storage-Bucket zu erstellen.
Klicken Sie nach der Erstellung des Buckets auf Auswählen, um Ihren Bucket auszuwählen.
Klicken Sie auf Erstellen, um den Arbeitsbereich für die Speech-to-Text API V2 Console zu erstellen.
Transkribieren Sie Ihre Audiodatei.
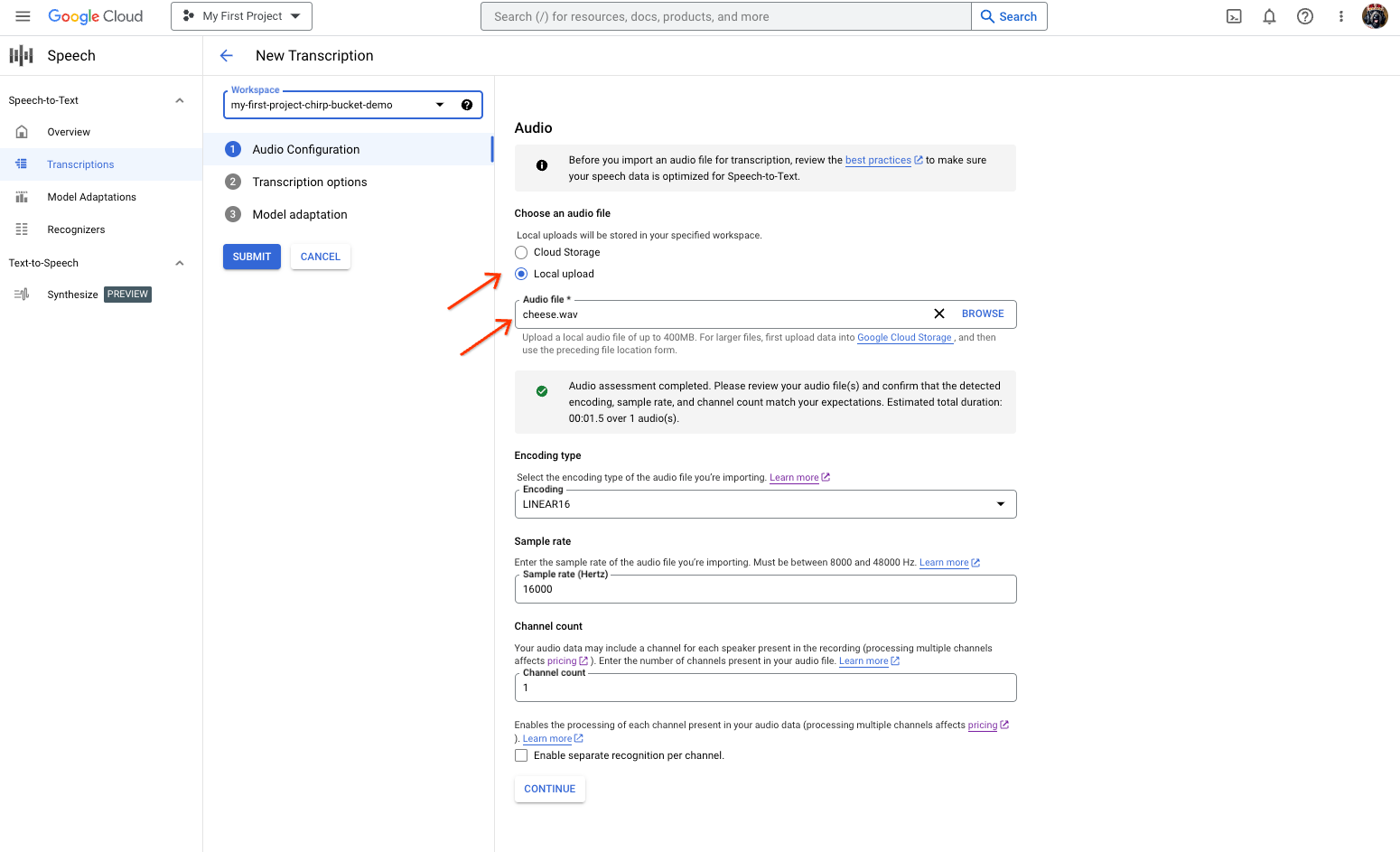
Seite zum Erstellen von Speech-to-Text-Transkriptionen mit Optionen zum Auswählen oder Hochladen einer Datei Wählen Sie auf der Seite Neue Transkription Ihre Audiodatei entweder durch einen Upload (Lokaler Upload) oder durch Angabe einer vorhandenen Cloud Storage-Datei (Cloud Storage) aus.
Klicken Sie auf Weiter, um zu den Sprache-zu-Text-Optionen zu gelangen.
Wählen Sie die Gesprochene Sprache aus, die Sie für die Erkennung mit Chirp und Ihrem zuvor erstellten Erkennungssystem verwenden möchten.
Wählen Sie im Drop-down-Menü für das Modell chirp_2 aus.
Wählen Sie im Drop-down-Menü Erkennungssystem Ihr neu erstelltes Erkennungssystem aus.
Klicken Sie auf Senden, um Ihre erste Erkennungsanfrage mit
chirp_2auszuführen.
Sehen Sie sich das Transkriptionsergebnis von Chirp 2 an.
Klicken Sie auf der Seite Transkriptionen auf den Namen der Transkription, um das Ergebnis aufzurufen.
Auf der Seite Transkriptionsdetails können Sie Ihr Transkriptionsergebnis anzeigen und optional die Audioinhalte im Browser wiedergeben.
Bereinigen
Mit den folgenden Schritten vermeiden Sie, dass Ihrem Konto bei Google Cloud die auf dieser Seite verwendeten Ressourcen in Rechnung gestellt werden:
-
Optional: Revoke the authentication credentials that you created, and delete the local credential file.
gcloud auth application-default revoke
-
Optional: Revoke credentials from the gcloud CLI.
gcloud auth revoke
Console
gcloud
Weitere Informationen
- Audiostreams transkribieren
- Kurze Audiodateien transkribieren
- Lange Audiodateien transkribieren
- Best Practices-Dokumentation mit Tipps zu Leistung, Accuracy und anderen Themen