
Con la API, sin código, puedes crear y entrenar un modelo personalizado de Speech-to-Text para mejorar la exactitud del reconocimiento a partir de un modelo existente de Cloud Speech-to-Text. Este servicio completamente administrado aprovisiona automáticamente los recursos de procesamiento, ejecuta el código de la aplicación de entrenamiento y garantiza la eliminación de los recursos de procesamiento después del trabajo de entrenamiento. Obtienes un modelo de transcripción completamente ajustado que es útil para cualquier aplicación downstream.
Al igual que en los modelos de aprendizaje automático, el entrenamiento de un modelo de Speech-to-Text personalizado suele ser iterativo y, además, implica seleccionar un modelo base como punto de partida, ajustarlo con tus conjuntos de datos de texto y audio y, luego, probar la calidad de reconocimiento del modelo. Si los resultados no son los esperados, vuelve a entrenar un modelo nuevo con una mezcla diferente de datos, vuelve a realizar una prueba o úsalo directamente para la transcripción en tu dominio.
Antes de comenzar
Asegúrate de haberte registrado en una cuenta de Google Cloud , haber creado un proyecto de Google Cloudy haber habilitado la API de Cloud Speech-to-Text. Para eso, ve a Voz en la consola deGoogle Cloud y navega a la API de Cloud Speech-to-Text. Opera en la sección Modelos personalizados (Custom Models) de la barra de navegación de la izquierda.
Crear un modelo personalizado
Comienza por crear un modelo personalizado de Speech-to-Text y definir sus parámetros, como el modelo base y el lenguaje de transcripción:
- Haz clic en Crear (Create) para crear un modelo personalizado.
- Ingresa un Nombre de modelo (Model name), que se usará para la pantalla y al que se hará referencia en las solicitudes a la API y en la consola de Google Cloud Speech.
- Ingresa una Descripción (Description) para el modelo.
- Selecciona el Modelo base (Base model) que se adapte mejor a tu caso de uso.
- Selecciona el Idioma (Language) de transcripción del modelo.
- Selecciona la Región (Region) en la que se debe realizar el entrenamiento.
- Haz clic en Continuar (Continue).

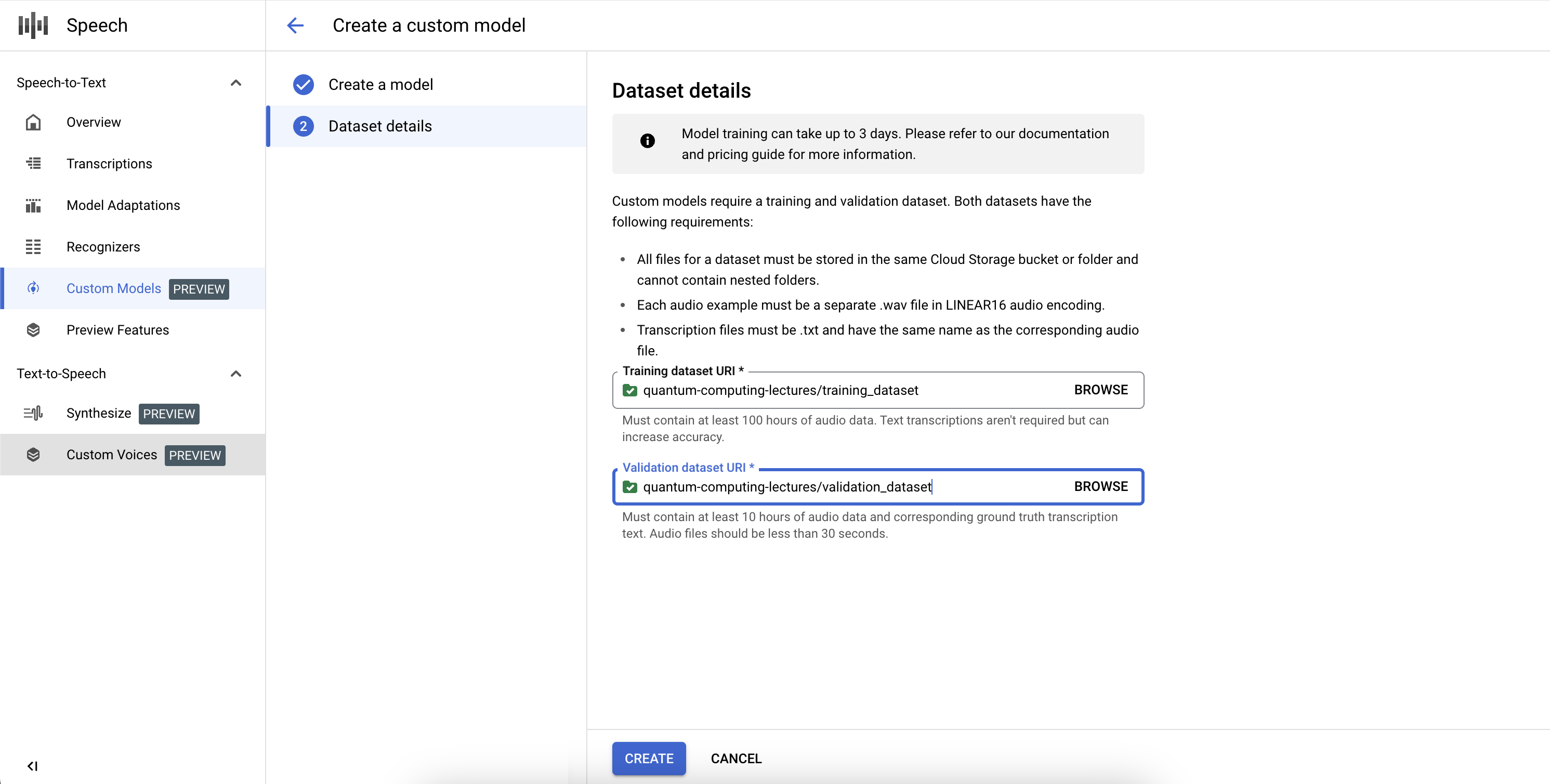
Para completar la definición del trabajo de modelo personalizado de Speech-to-Text y comenzar el entrenamiento, deberás definir los conjuntos de datos de entrenamiento y validación.
- Para seleccionar un conjunto de datos de entrenamiento (Training dataset URI), proporciona un URI de directorio de Cloud Storage válido. Asegúrate de que solo estén presentes los archivos de audio y de texto, y que la duración total del audio cumpla con los requisitos del conjunto de datos de entrenamiento.
- Para seleccionar un conjunto de datos de validación (Validation Dataset URI), proporciona un URI de directorio de Cloud Storage válido. Asegúrate de que solo estén presentes archivos de audio y de texto, y que la duración total del audio cumpla con los requisitos del conjunto de datos de validación.
- Haz clic en Crear (Create) para iniciar el proceso de entrenamiento.
- Para seleccionar un conjunto de datos de validación (Validation Dataset URI), proporciona un URI de directorio de Cloud Storage válido. Asegúrate de que solo estén presentes archivos de audio y de texto, y que la duración total del audio cumpla con los requisitos del conjunto de datos de validación.
Si no se indexan suficientes horas de audio o los archivos no siguen los lineamientos, el trabajo de entrenamiento fallará.
Los trabajos de entrenamiento pueden estar en cola detrás de otros trabajos en nuestro sistema. El entrenamiento de un modelo puede tardar desde un par de horas hasta unos días, según el tamaño del conjunto de datos. Después del entrenamiento de modelos, su estado se marcará como Activo.
Borra un modelo personalizado
Antes de comenzar, asegúrate de que no se enrute tráfico a tu modelo personalizado de Speech-to-Text con ningún extremo. Si lo borras, dejará de entregar solicitudes.
- Accede a la pestaña Modelos de la sección Modelos personalizados.
- Haz clic para expandir las opciones y, luego, en Borrar. En unos instantes, se borrará el modelo personalizado de Speech-to-Text, junto con todos sus extremos, y ya no entregará tráfico.
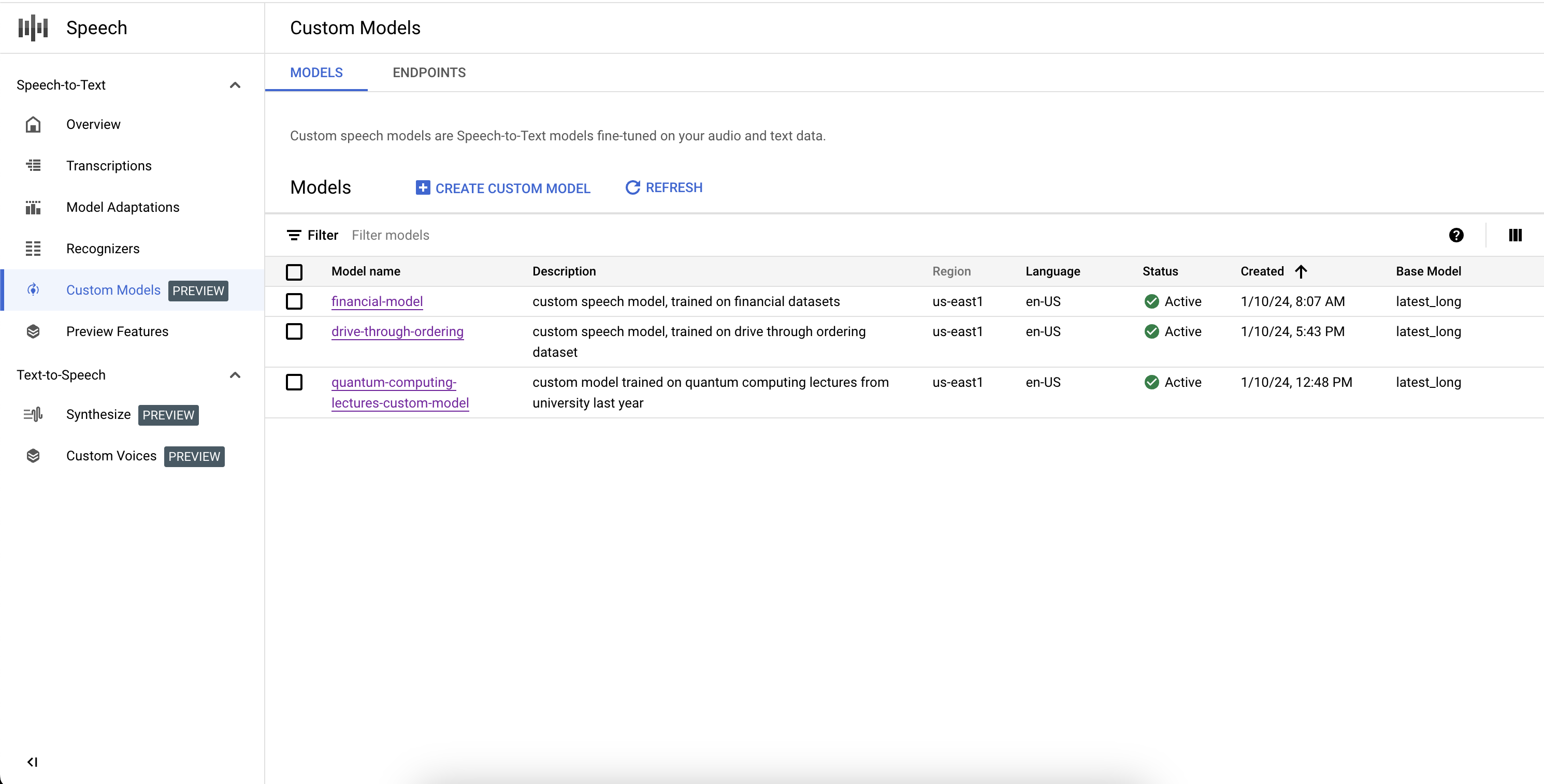
Enumera los modelos personalizados
Si seleccionas los Modelos (Models) en la sección Modelos personalizados (Custom Models), también puedes enumerar todos tus modelos personalizados de Speech-to-Text, incluidos los activos y los que se están entrenando y borrando.
¿Qué sigue?
Consulta los recursos para aprovechar los modelos de voz personalizados en tu aplicación:
- Implementa y administra extremos de modelos.
- Usa tus modelos personalizados.
- Evalúa tus modelos personalizados.