
Con la API, sin necesidad de escribir código, puedes crear y entrenar un modelo personalizado de Speech-to-Text para mejorar la precisión del reconocimiento a partir de un modelo de Cloud Speech-to-Text. Este servicio totalmente gestionado aprovisiona automáticamente los recursos informáticos, ejecuta el código de la aplicación de entrenamiento y se asegura de que se eliminen los recursos informáticos después del trabajo de entrenamiento. Obtendrás un modelo de transcripción totalmente optimizado que podrás usar en cualquier aplicación posterior.
Al igual que los modelos de aprendizaje automático, el entrenamiento de un modelo de transcripción de voz personalizado suele ser un proceso iterativo que implica seleccionar un modelo base como punto de partida, perfeccionarlo con tus conjuntos de datos de texto y audio y, a continuación, probar la calidad del reconocimiento del modelo. Si los resultados no son los esperados, puedes volver a entrenar un nuevo modelo con una combinación de datos diferente, volver a probarlo o usarlo directamente para la transcripción en tu dominio.
Antes de empezar
Asegúrate de que te has registrado para obtener una cuenta, has creado un proyecto y has habilitado la API Cloud Speech-to-Text. Para ello, ve a Speech en la consolaGoogle Cloud y accede a la API Cloud Speech-to-Text. Google Cloud Google CloudTrabaja en la sección Modelos personalizados de la barra de navegación de la izquierda.
Crear un modelo personalizado
Empieza creando un modelo personalizado de Speech-to-Text y definiendo sus parámetros, como el modelo base y el idioma de transcripción:
- Haz clic en Crear para crear un modelo personalizado.
- Introduce un nombre de modelo, que se usará para mostrarse y al que se hará referencia en tus solicitudes de API y en la consola de Google Cloud Speech.
- Escriba una descripción del modelo.
- Selecciona un modelo base que se adapte mejor a tu caso práctico.
- Selecciona el idioma de transcripción del modelo.
- Selecciona la región en la que se debe llevar a cabo la formación.
- Haz clic en Continuar.
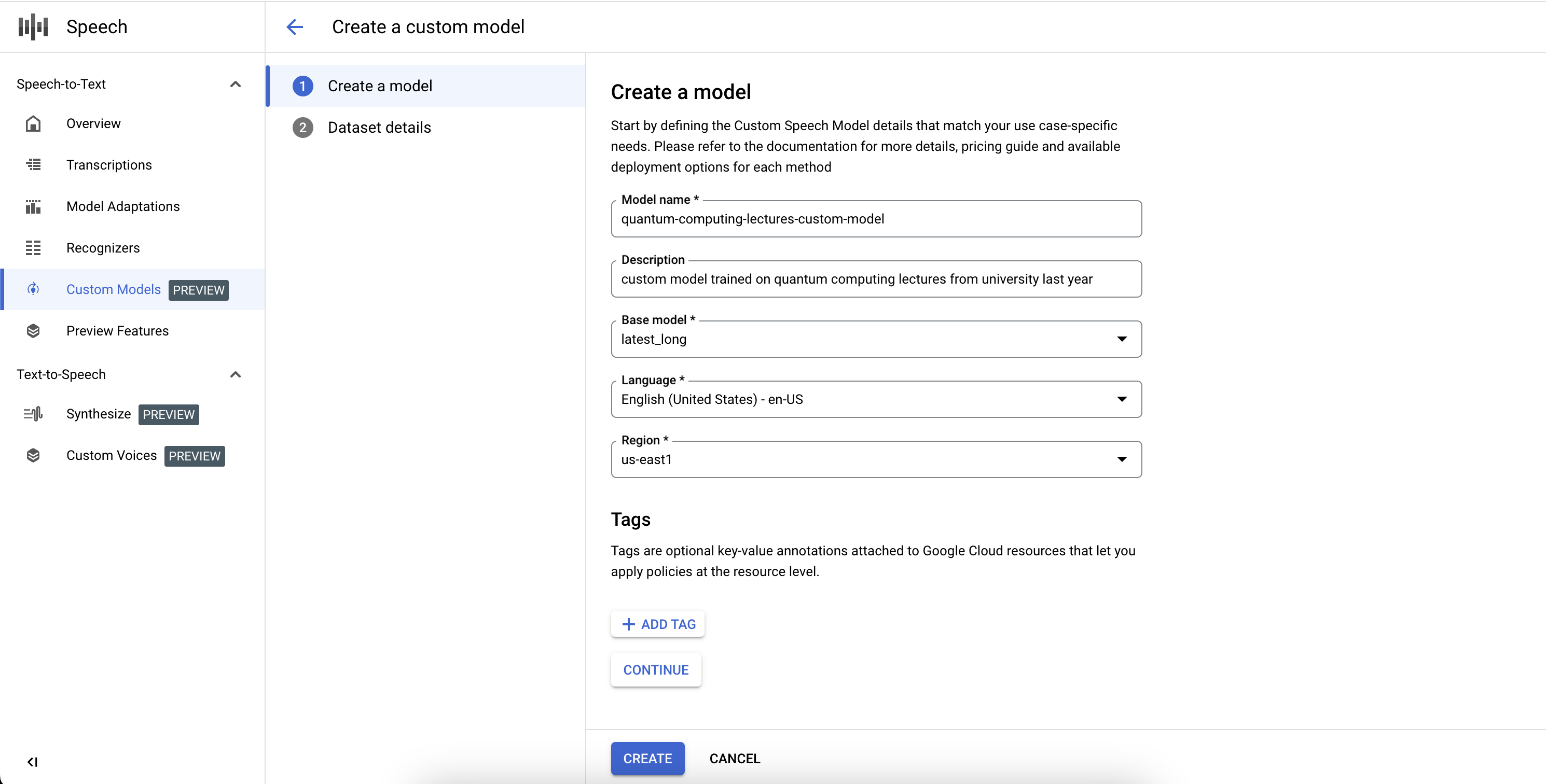
Para completar la definición del trabajo del modelo de Custom Speech-to-Text e iniciar el entrenamiento, debes definir los conjuntos de datos de entrenamiento y de validación.
- Selecciona un conjunto de datos de entrenamiento. Para ello, proporciona un URI de directorio de Cloud Storage válido. Asegúrate de que solo haya archivos de audio y de texto, y de que la duración total del audio cumpla los requisitos del conjunto de datos de entrenamiento.
- Selecciona un conjunto de datos de validación. Para ello, proporciona un URI de directorio de Cloud Storage válido. Asegúrate de que solo haya archivos de audio y de texto, y de que la duración total del audio cumpla los requisitos del conjunto de datos de validación.
- Haz clic en Crear para iniciar el proceso de entrenamiento.
- Selecciona un conjunto de datos de validación. Para ello, proporciona un URI de directorio de Cloud Storage válido. Asegúrate de que solo haya archivos de audio y de texto, y de que la duración total del audio cumpla los requisitos del conjunto de datos de validación.
Si no se indexan suficientes horas de audio o los archivos no cumplen las directrices, el trabajo de entrenamiento fallará.
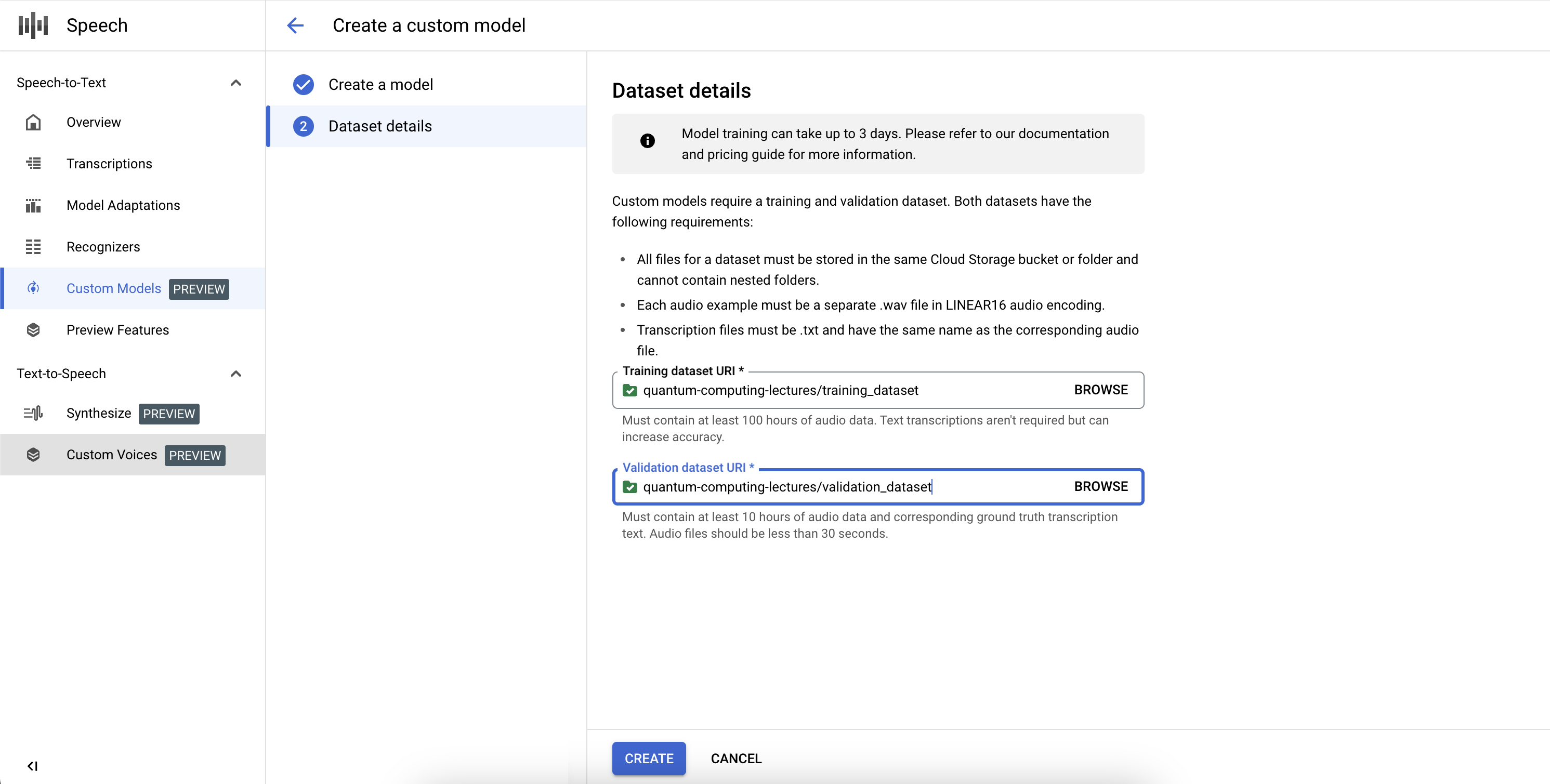
Las tareas de entrenamiento se pueden poner en cola detrás de otras tareas de nuestro sistema, y el entrenamiento de un modelo puede tardar desde un par de horas hasta varios días, en función del tamaño del conjunto de datos. Una vez que se haya entrenado el modelo, su estado se marcará como Activo.
Eliminar un modelo personalizado
Antes de empezar, asegúrate de que no haya tráfico dirigido a tu modelo de Speech-to-Text personalizado a través de ningún endpoint, ya que, si lo eliminas, dejará de atender solicitudes.
- Vaya a la pestaña Modelos de la sección Modelos personalizados.
- Haz clic para desplegar las opciones y, a continuación, haz clic en Eliminar. En unos instantes, se eliminará el modelo de Custom Speech-to-Text junto con todos sus endpoints y dejará de servir tráfico.
Listar tus modelos personalizados
Si seleccionas Modelos en la sección Modelos personalizados, también puedes ver una lista de todos tus modelos de Speech-to-Text personalizados, incluidos los que están en proceso de entrenamiento, activos y en proceso de eliminación.
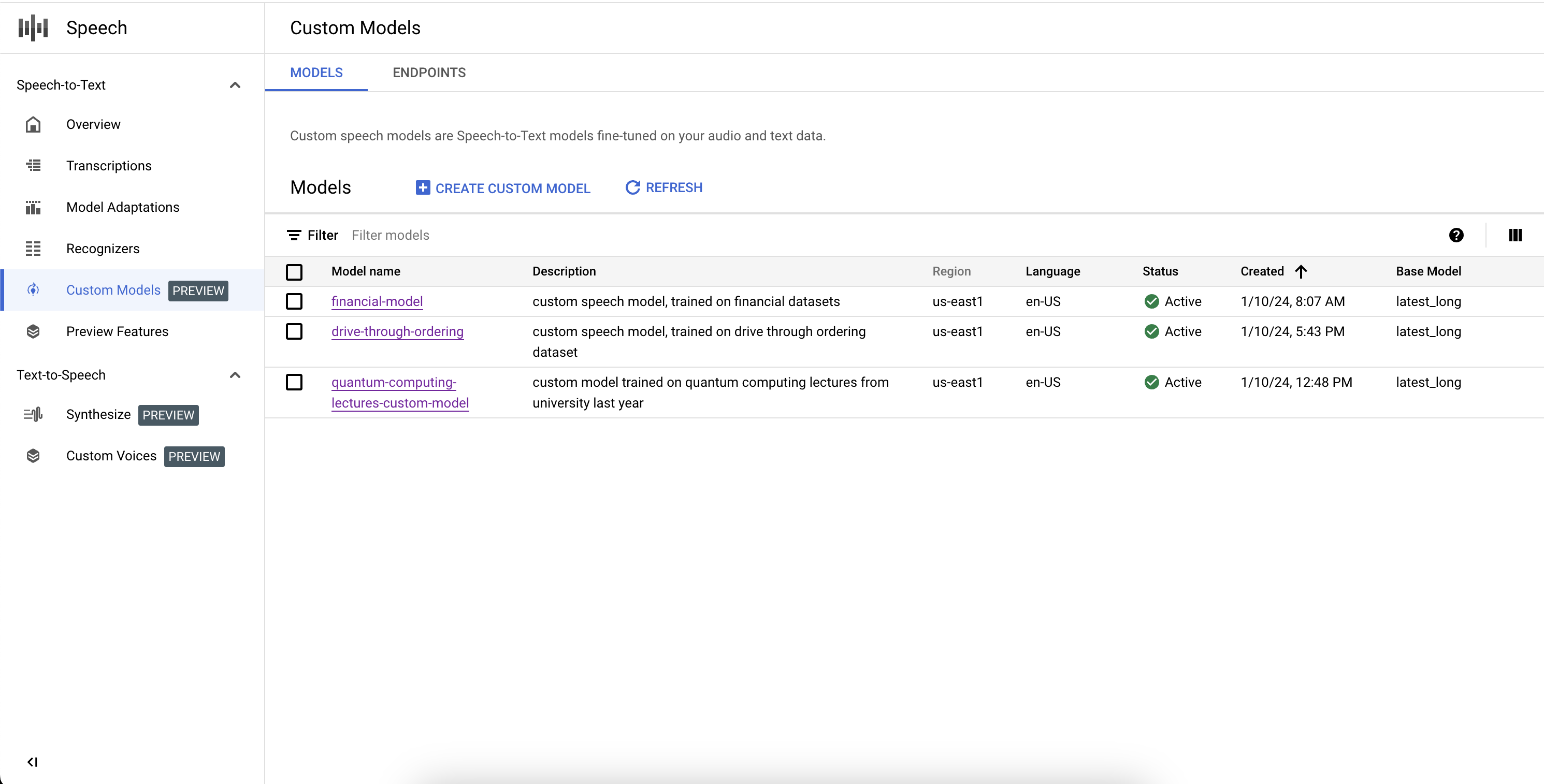
Siguientes pasos
Sigue los recursos para aprovechar los modelos de voz personalizados en tu aplicación:
- Desplegar y gestionar endpoints de modelos .
- Usar modelos personalizados
- Evaluar los modelos personalizados