
数组子查询与标量子查询类似,区别在于数组子查询可以使用多个输入行。Spanner 会将使用的行转换为单个标量输出数组,其中每个所使用的输入行都对应一个元素。
数据库架构
此页面上的查询和执行计划基于以下数据库架构:
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
BirthDate DATE
) PRIMARY KEY(SingerId);
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
MarketingBudget INT64
) PRIMARY KEY(SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget);
CREATE TABLE Songs (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
TrackId INT64 NOT NULL,
SongName STRING(MAX),
Duration INT64,
SongGenre STRING(25)
) PRIMARY KEY(SingerId, AlbumId, TrackId),
INTERLEAVE IN PARENT Albums ON DELETE CASCADE;
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC), INTERLEAVE IN Albums;
CREATE INDEX SongsBySongName ON Songs(SongName);
CREATE TABLE Concerts (
VenueId INT64 NOT NULL,
SingerId INT64 NOT NULL,
ConcertDate DATE NOT NULL,
BeginTime TIMESTAMP,
EndTime TIMESTAMP,
TicketPrices ARRAY<INT64>
) PRIMARY KEY(VenueId, SingerId, ConcertDate);
您可以使用以下数据操纵语言 (DML) 语句向这些表中添加数据:
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate)
VALUES (1, "Marc", "Richards", "1970-09-03"),
(2, "Catalina", "Smith", "1990-08-17"),
(3, "Alice", "Trentor", "1991-10-02"),
(4, "Lea", "Martin", "1991-11-09"),
(5, "David", "Lomond", "1977-01-29");
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle)
VALUES (1, 1, "Total Junk"),
(1, 2, "Go, Go, Go"),
(2, 1, "Green"),
(2, 2, "Forever Hold Your Peace"),
(2, 3, "Terrified"),
(3, 1, "Nothing To Do With Me"),
(4, 1, "Play");
INSERT INTO Songs (SingerId, AlbumId, TrackId, SongName, Duration, SongGenre)
VALUES (2, 1, 1, "Let's Get Back Together", 182, "COUNTRY"),
(2, 1, 2, "Starting Again", 156, "ROCK"),
(2, 1, 3, "I Knew You Were Magic", 294, "BLUES"),
(2, 1, 4, "42", 185, "CLASSICAL"),
(2, 1, 5, "Blue", 238, "BLUES"),
(2, 1, 6, "Nothing Is The Same", 303, "BLUES"),
(2, 1, 7, "The Second Time", 255, "ROCK"),
(2, 3, 1, "Fight Story", 194, "ROCK"),
(3, 1, 1, "Not About The Guitar", 278, "BLUES");
以下查询演示了数组子查询运算符:
SELECT a.albumid,
array
(
select concertdate
FROM concerts
WHERE concerts.singerid = a.singerid)
FROM albums AS a;
子查询如下:
SELECT concertdate
FROM concerts
WHERE concerts.singerid = a.singerid;
Spanner 会将每个 AlbumId 的子查询结果转换为与该 AlbumId 相对应的 ConcertDate 行的数组。该执行计划显示了一个数组子查询(标记为数组子查询,位于分布式联合运算符上方):
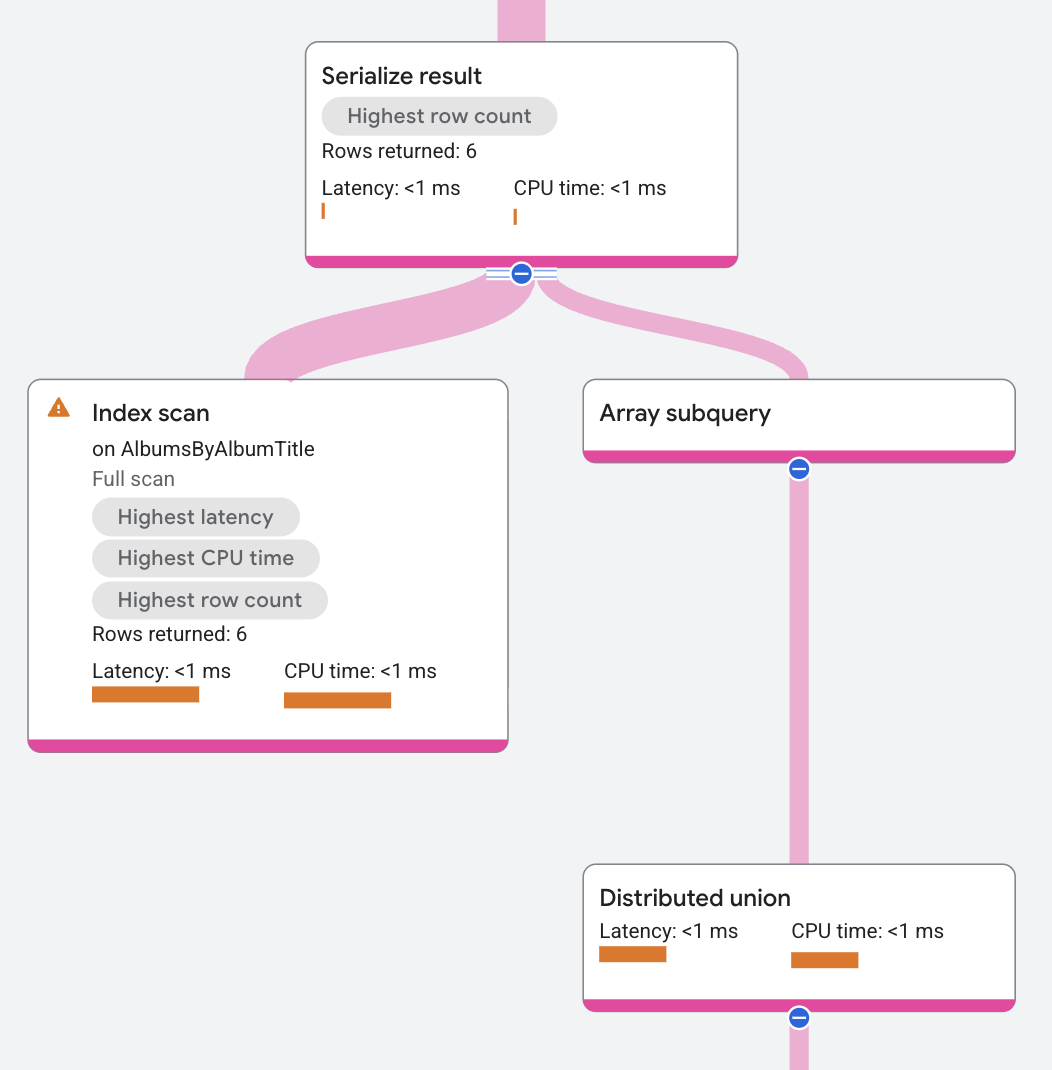
属性和执行统计信息
运算符的属性描述了在执行运算符时使用的特征。执行统计信息是在查询执行期间收集的值,可帮助您评估运算符的性能。
属性
| 名称 | 说明 |
|---|---|
| 执行方法 | 在行执行中,运算符一次处理一行。 在批处理执行中,运算符一次处理一批行。 |
执行统计信息
| 名称 | 说明 |
|---|---|
| 延迟时间 | 运算符中所有执行操作的耗时。 |
| 累计延迟时间 | 当前运算符及其后代的总时间。 |
| CPU 时间 | 执行运算符所花费的 CPU 时间总和。 |
| 累计 CPU 时间 | 执行相应运算符及其后代所花费的总 CPU 时间。 |
| 执行时间 | 运行查询和处理结果所花费的总时间。 |
| 返回的行数 | 相应运算符输出的行数 |
| 执行任务数量 | 相应运算符的执行次数。某些执行任务可以并行运行。 |