
이 문서에서는 데이터 에이전트 애플리케이션에서 높은 QueryData 쿼리 정확도를 달성하는 데 도움이 되는 컨텍스트 세트를 만들고 최적화하는 방법을 설명합니다. 컨텍스트 엔지니어링 에이전트는 컨텍스트 세트의 생성 및 최적화를 자동화하여 컨텍스트 세트를 빌드, 평가, 개선하는 데 도움이 됩니다.
컨텍스트 세트 및 QueryData에 대해 알아보려면 컨텍스트 세트 개요 및 QueryData 개요를 참고하세요.엔터프라이즈급 데이터 애플리케이션을 빌드하려면 텍스트-SQL 모델 정확도가 일반적으로 100% 에 가까운 품질을 달성해야 합니다. 잘못된 쿼리 결과는 전체 애플리케이션 사용성과 사용자 환경에 영향을 미칩니다. 높은 정확도로 설명 가능하고 비즈니스와 관련된 답변을 얻으려면 컨텍스트 엔지니어링이 필요합니다. 컨텍스트 엔지니어링은 최적의 정확도를 달성하기 위해 컨텍스트를 생성하고 반복적으로 최적화하는 프로세스입니다.
비즈니스 애플리케이션을 타겟팅하는 컨텍스트와 함께 QueryData를 제공하면 시스템에서 미묘한 사용자 의도를 해결하는 데 필요한 정확한 비즈니스 규칙을 제공할 수 있습니다.
컨텍스트 엔지니어링 에이전트
컨텍스트 엔지니어링 에이전트는 이 최적화 워크플로를 자동화합니다. 상담사와 대화하여 임시 작업을 처리하여 컨텍스트를 최적화할 수 있습니다. 다음 목록에는 상담사에게 지시하는 데 사용할 수 있는 자연어 프롬프트의 예와 상담사의 응답 방식에 대한 설명이 나와 있습니다. 다음 예시를 사용하여 컨텍스트를 빌드하고 최적화하세요.
- 실패 분석을 위한 프롬프트 예시: '디즈니 월드 항공편'과 같은 질문에 대해 공항을 올바르게 식별할 수 있도록 컨텍스트를 업데이트해 줘.' 에이전트는 실패를 분석하고, 격차에 대해 추론하며, 값 검색어와 같은 적절한 컨텍스트 항목을 추가하도록 추천합니다.
- 컨텍스트 제안을 위한 프롬프트 예시: '내 앱 코드를 읽고 추가할 컨텍스트를 제안해 줘.' 에이전트는 코드를 파싱하고, 애플리케이션의 도메인에 대해 추론하며, 관련 컨텍스트 항목을 제안합니다.
- 일괄 처리를 위한 프롬프트 예시: "다음은 질문과 SQL 쿼리의 10가지 예시입니다. 템플릿으로 변환하세요.' 에이전트가 입력을 일괄 처리하고 컨텍스트 세트를 업데이트합니다.
골든 데이터 세트의 중요성
컨텍스트를 최적화하려면 먼저 애플리케이션의 자연어 입력과 일치하는 데이터 세트를 만들어야 합니다. 상담사는 사용자 질문과 예상되는 데이터베이스 쿼리로 구성된 표준 데이터 세트를 빌드하는 데 도움을 줄 수 있습니다. 골든 데이터 세트를 사용하면 다음 작업을 할 수 있습니다.
- 쿼리 성능 기준을 설정합니다.
- 정답 데이터베이스 쿼리에 대해 업데이트를 검증합니다.
- 여러 반복에 걸쳐 정확도 개선을 측정합니다.
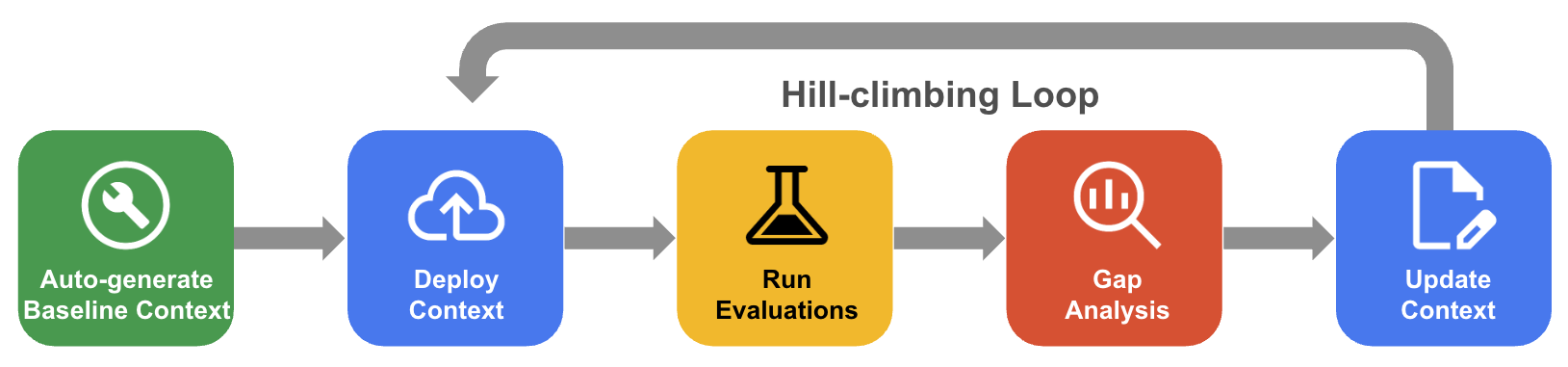
체계적인 언덕 오르기 프로세스
체계적인 언덕 오르기에서 에이전트는 골든 데이터 세트 평가, 격차 분석, 업데이트를 통해 컨텍스트 세트를 반복적으로 개선하여 정확도를 100%에 가깝게 만듭니다.
- 기준 컨텍스트 자동 생성: 데이터베이스 스키마 및 애플리케이션 아티팩트에서 파생된 시작 컨텍스트 세트를 만듭니다.
- 언덕 오르기 최적화 워크플로: 에이전트가 QueryData 정확도를 평가하고, 실패에 대한 격차 분석을 실행하고, 정확도를 높이기 위한 개선사항을 자동으로 제안하도록 합니다.
다음 다이어그램은 체계적인 언덕 오르기 워크플로를 보여줍니다.
시작하기 전에
컨텍스트 엔지니어링 에이전트를 사용하기 전에 다음 기본 요건을 완료하세요.
필수 서비스 사용 설정
프로젝트에 다음 서비스를 사용 설정합니다.Spanner 인스턴스 준비
- Spanner 인스턴스를 사용할 수 있는지 확인합니다. 자세한 내용은 인스턴스 만들기를 참고하세요.
- 테이블을 만들 인스턴스에 데이터베이스를 만들어야 합니다. 자세한 내용은 Spanner 인스턴스에서 데이터베이스 만들기를 참고하세요.
이 튜토리얼을 진행하려면 Spanner 인스턴스에 데이터베이스가 있어야 합니다. 자세한 내용은 데이터베이스 만들기를 참고하세요.
필수 역할 및 권한
- 클러스터에 IAM 사용자 또는 서비스 계정을 추가합니다. 자세한 내용은 IAM 역할 적용을 참고하세요.
- 프로젝트 수준에서 IAM 사용자에게
spanner.databaseReader및geminidataanalytics.queryDataUser역할을 부여합니다. 자세한 내용은 프로젝트의 IAM 정책 바인딩 추가를 참고하세요. - 필요한 데이터베이스에 대해 프로젝트 수준에서 IAM 사용자에게 역할과 권한을 부여합니다.
개발 환경 준비
로컬 개발 환경이나 IDE에서 컨텍스트 세트 파일을 빌드할 수 있습니다. 환경을 준비하려면 다음 단계를 완료하세요.
- 컨텍스트 엔지니어링 에이전트 설치
- 데이터베이스 연결 설정
컨텍스트 엔지니어링 에이전트 설치
컨텍스트 엔지니어링 에이전트는 기본 Python 패키지를 관리하는 데 uv가 필요한 모델 컨텍스트 프로토콜 (MCP) 서버를 실행합니다.
uv설치의 안내에 따라uv를 설치합니다.uv이 설치되어 있고 명령줄에서 액세스할 수 있는지 확인합니다.uv --version
환경을 준비하려면 선택한 에이전트 하네스(예: Antigravity CLI, Claude Code, Gemini CLI)에 컨텍스트 엔지니어링 에이전트를 설치합니다.
선택한 에이전트 하니스에 따라 해당 설치 단계를 따르세요.
Antigravity CLI
Antigravity CLI에 컨텍스트 엔지니어링 에이전트를 설치하려면 다음 단계를 따르세요.
- Antigravity CLI를 설치합니다. Antigravity CLI 시작하기를 참고하세요.
- 컨텍스트 생성 워크플로가 포함된 컨텍스트 엔지니어링 에이전트 플러그인을 설치합니다. VERSION을 필요한 출시된 버전으로 바꿉니다.
agy plugin install https://github.com/GoogleCloudPlatform/db-context-enrichment/tree/VERSION
- Antigravity CLI를 시작합니다.
agy
- 선택사항입니다. 플러그인을 업데이트합니다.
agy plugin uninstall google-cloud-db-context-engineering agy plugin install https://github.com/GoogleCloudPlatform/db-context-enrichment/tree/NEW_VERSION
Claude Code
Claude Code에 컨텍스트 엔지니어링 에이전트를 설치하려면 다음 단계를 따르세요.
- 플러그인 마켓 추가:
/plugin marketplace add https://github.com/GoogleCloudPlatform/db-context-enrichment.git
- 플러그인 설치:
/plugin install db-context-engineering@db-context-enrichment-marketplace
- 플러그인을 다시 로드하여 변경사항을 활성화합니다.
/reload-plugins
- 선택사항입니다. 플러그인을 업데이트합니다.
/plugin update db-context-engineering@db-context-enrichment-marketplace
Gemini CLI (지원 중단됨)
Gemini CLI에 컨텍스트 엔지니어링 에이전트를 설치하려면 다음 단계를 따르세요.
- Gemini CLI를 설치합니다. Gemini CLI 시작하기를 참고하세요.
- 확장 프로그램을 설치합니다.
gemini extensions install https://github.com/GoogleCloudPlatform/db-context-enrichment
- 선택사항입니다. 확장 프로그램을 업데이트합니다.
gemini extensions update mcp-db-context-enrichment
데이터베이스 연결 설정
에이전트가 스키마를 가져오기 위한 데이터베이스 연결과 생성된 SQL 컨텍스트의 구문을 검증하는 기능이 필요합니다. 에이전트가 데이터베이스와 상호작용하도록 하려면 인증 사용자 인증 정보를 구성하고 데이터베이스 연결 구성을 정의하세요.
애플리케이션 기본 사용자 인증 정보 구성
컨텍스트 엔지니어링 에이전트에서 Google Cloud 리소스에 액세스하기 위한 사용자 인증 정보를 제공하도록 애플리케이션 기본 사용자 인증 정보 (ADC)를 구성합니다.
- 도구 상자 MCP 서버: 사용자 인증 정보를 사용하여 데이터베이스에 연결하고, 스키마를 가져오고, 유효성 검사를 위해 SQL을 실행합니다.
- Evalbench: 사용자 인증 정보를 사용하여 평가를 위해 QueryData를 호출합니다.
터미널에서 다음 명령어를 실행하여 인증합니다.
gcloud auth application-default login데이터베이스 연결 파일 구성
에이전트에는 컨텍스트 생성을 위한 데이터베이스 연결이 필요하며, 이는 MCP 도구 상자에서 지원하고 구성 파일 내에 정의합니다.
구성 파일은 스키마를 가져오거나 SQL을 실행하는 데 필요한 데이터베이스 소스와 도구를 지정합니다. 컨텍스트 엔지니어링 에이전트에는 구성을 생성하는 데 도움이 되는 사전 설치된 에이전트 기술이 함께 제공됩니다.
에이전트 환경을 시작합니다.
에이전트에게 데이터베이스 연결 설정에 도움을 요청합니다(예: '데이터베이스 연결을 설정하는 데 도움을 줘'). 에이전트의 안내에 따라 현재 작업 디렉터리에
autoctx/tools.yaml로 구성 파일을 만듭니다.새
tools.yaml구성을 적용하려면 연결을 새로고침하세요.- Antigravity CLI에서
/mcp를 실행하고toolbox를 선택하여 다시 시작합니다. - Gemini CLI에서
/mcp reload를 실행합니다. - Claude Code에서
/mcp를 실행하고toolbox을 선택한 후Reconnect를 선택합니다.
- Antigravity CLI에서
데이터베이스 구성 파일을 수동으로 구성하는 방법에 대한 자세한 내용은 MCP 도구 상자 구성을 참고하세요.
컨텍스트 생성 및 최적화
컨텍스트 엔지니어링 에이전트는 코딩 에이전트의 컨텍스트 엔지니어링 기능을 향상하기 위한 에이전트 기술 및 MCP 도구 세트를 제공합니다. 이러한 도구를 함께 사용하여 기준을 생성하고, 효과를 측정하고, 개선사항을 반복적으로 적용할 수 있습니다. 하지만 워크플로의 어느 단계에서든 시작할 수 있습니다.
- 이미 컨텍스트가 설정되어 있다면 평가로 바로 진행할 수 있습니다.
- 수정하려는 실패한 쿼리가 있는 경우 격차 분석으로 바로 진행하면 됩니다.
각 기능은 에이전트의 작업, 사용 사례, 호출 명령어를 설명합니다.
프롬프트 예시에서는 자연어로 에이전트에 질문하는 방법을 보여줍니다. 상담사가 요청을 완료하는 데 추가 세부정보가 필요한 경우 명확한 정보를 묻는 메시지가 표시됩니다.
평가 데이터 세트 빌드 및 확장
성능을 개선하려면 먼저 성능을 측정해야 합니다. 사용자 질문과 예상 SQL로 구성된 골든 데이터 세트가 없는 컨텍스트 엔지니어링에는 체계적인 검증이 부족합니다. 골든 데이터 세트를 사용하면 모든 변경사항이 정답에 대해 검증할 수 있는 측정 가능한 개선사항이 됩니다.
대표적인 골든 데이터 세트를 수동으로 만드는 데는 시간이 많이 걸리며 작은 데이터 세트에는 사용자 표현의 변형이 누락될 수 있습니다. 에이전트는 다음을 통해 이 문제를 해결합니다.
- 데이터베이스 스키마를 기반으로 후보 질문-SQL 쌍을 생성합니다.
- 필터 변형, 동의어, 바꿔쓰기를 사용하여 작은 시드 데이터 세트를 확장합니다.
원하는 경우 에이전트가 생성된 SQL을 데이터베이스에 대해 실행하도록 할 수 있습니다. 이 확인을 통해 데이터 세트에 추가하기 전에 쿼리가 성공적으로 실행되는지 확인할 수 있습니다.
데이터 세트는 질문-SQL 쌍이 포함된 JSON 파일입니다.
[
{
"id": "example_001",
"nlq": "What is the total revenue for the top 5 products?",
"golden_sql": "SELECT product_id, sum(net_revenue) FROM sales GROUP BY product_id ORDER BY sum(net_revenue) DESC LIMIT 5;"
}
]
승인된 쌍은 평가할 준비가 된 작업공간의 autoctx/golden.json 파일을 채웁니다. 기존 파일을 제공하거나 에이전트가 확장할 수 있도록 평가 예시를 인라인으로 작성할 수 있습니다.
다음 예시 프롬프트를 사용하여 에이전트에게 지시할 수 있습니다.
- '내 스키마에서 평가 데이터 세트를 생성해 줘.'
- '다음은 시드 질문과 SQL입니다. 이를 더 광범위한 데이터 세트로 확장하고 쿼리가 실행되는지 확인하세요.'
기준 컨텍스트 세트 생성
컨텍스트를 처음부터 만드는 것을 방지하려면 에이전트가 데이터베이스 스키마와 애플리케이션 아티팩트(예: 비즈니스 규칙, 샘플 쿼리, README 파일)에서 초기 컨텍스트 세트를 파생하도록 하면 됩니다. 이 기준 컨텍스트는 최종적인 것은 아니지만 데이터베이스 모델에 기반한 검증된 시작점을 제공합니다.
다음 예시 프롬프트를 사용하여 에이전트에게 지시할 수 있습니다.
- '내 스키마에서 컨텍스트 세트를 생성해 줘.'
- '이 스키마와
requirements.md의 비즈니스 규칙을 사용하여 초기 컨텍스트를 생성해 줘.'
에이전트에서 생성된 아티팩트를 정리하는 실험의 이름을 지정하라는 메시지가 표시되며, 데이터베이스 스키마가 큰 경우 범위를 좁히라는 메시지가 표시될 수 있습니다. Spanner Studio를 사용하여 컨텍스트를 업로드하려면 에이전트가 JSON 파일을 생성한 후 안내를 따르세요.
컨텍스트 효과 평가
컨텍스트 세트와 골든 데이터 세트를 설정한 후 각 골든 질문으로 데이터 에이전트의 QueryData API를 쿼리하여 에이전트가 컨텍스트 성능을 측정하도록 할 수 있습니다. 에이전트는 생성된 SQL과 실행 결과를 Evalbench를 사용하여 예상 답변과 비교하여 비교를 처리합니다.
평가를 실행하면 다음이 제공됩니다.
- 컨텍스트 반복 전반의 진행 상황을 추적하기 위한 통과 및 실패 결과, 집계 점수와 같은 정량적 측정항목
- 인라인 대화 요약과 실험 폴더의
eval_reports/디렉터리에 작성된 자세한 CSV 보고서
평가를 시작하려면 골드 데이터 세트 경로와 컨텍스트 세트 ID를 제공하세요. 컨텍스트 세트 ID를 찾는 방법을 알아보려면 에이전트 컨텍스트 ID 찾기를 참고하세요.
다음 예시 프롬프트를 사용하여 에이전트에게 지시할 수 있습니다.
- "내 컨텍스트를
golden.json와 비교해 줘." - '내 마지막 실험의 구성을 사용하여 평가를 다시 실행해 줘.'
이전에 생성된 평가 구성을 다시 설정하지 않고 다시 실행하려면 에이전트에게 요청하거나 CLI를 직접 호출하세요.
uvx google-evalbench --run_config=autoctx/experiments/my-experiment/eval_configs/run_config.json
평가 구성 스키마와 평가 실행을 맞춤설정하는 방법에 관한 자세한 내용은 Evalbench 문서를 참고하세요.
갭 분석을 수행하고 개선사항 제안
쿼리 실패를 해결하려면 잘못된 열, 누락된 테이블 조인, 해결되지 않은 퍼지 용어와 같은 근본 원인을 파악해야 합니다. 이러한 문제를 수동으로 식별하려면 평가 보고서를 광범위하게 분석해야 합니다.
에이전트는 이 분석 및 수정 루프를 자동화합니다.
- 격차 분석: 에이전트가 평가 결과와 설정된 컨텍스트를 읽어 유사한 실패를 그룹화하고 템플릿, 패싯, 값 검색과 같은 타겟팅된 컨텍스트 추가를 추천합니다.
- 제안된 수정사항: 에이전트는 구체적인 수정사항을 제안하고 선택적으로 데이터베이스에 대해 SQL을 테스트하여 해결 방법을 확인합니다.
- 기준 보존: 에이전트는 기준 컨텍스트와 함께 새로운 JSON 파일에 개선사항을 작성하여 원본 파일을 보존합니다.
다음 예시 프롬프트를 사용하여 에이전트에게 지시할 수 있습니다.
- '마지막 평가에서 격차 분석을 실행하고 수정사항을 제안해 줘.'
- '
golden.json에 대해 이 컨텍스트 세트를 최적화해 줘.'
다음 반복을 준비하려면 데이터 에이전트 스튜디오를 사용하여 개선된 컨텍스트를 타겟 컨텍스트 세트에 업로드하고 안내를 따르세요.
요청 시 작성자별 컨텍스트 항목
특정 질문의 템플릿, 반복되는 필터의 패싯 또는 특정 열의 값 검색과 같은 필수 컨텍스트를 이미 알고 있는 경우 컨텍스트 JSON을 수동으로 작성하면 매개변수 이름, 유형 메타데이터 또는 프래그먼트 구문에서 직렬화 오류가 발생할 수 있습니다. 에이전트가 JSON 형식을 처리하므로 비즈니스 의도에 집중할 수 있습니다.
새 쿼리 패턴을 지원하거나 누락된 스키마 세부정보를 해결해야 하는 경우와 같은 임시 업데이트에도 이 기능을 사용할 수 있습니다. JSON을 가져오려면 평가를 실행하거나 실험을 설정하지 않고 필요한 컨텍스트를 에이전트에게 설명하세요.
일회성 작업을 맡았을 때도 이 기능을 사용하는 것이 좋습니다. 이해관계자가 지원을 원하는 새로운 질문-SQL 쌍을 제공하거나 코드 검토 중에 누락된 패싯을 발견하는 경우입니다. 이 문제를 해결하기 위해 실험을 설정하거나 평가를 실행할 필요가 없습니다. 원하는 내용을 설명하면 에이전트가 JSON을 생성합니다.
다음 예시 프롬프트를 사용하여 에이전트에게 지시할 수 있습니다.
- "SQL:
SELECT name FROM airports WHERE country = 'United States' AND state = 'CA'을 사용하여 '캘리포니아에 있는 공항은 어디야?'에 대한 템플릿을 만들어 줘." - '빨간 눈'이라는 라벨이 지정된 필터
departure_time BETWEEN '00:00:00' AND '06:00:00'의 패싯을 만들어 줘. - '
airports.iata의 값 검색을 만들어 줘.'
컨텍스트 유형 선택에 관한 이유
템플릿, 패싯 또는 값 검색 여부와 관계없이 올바른 컨텍스트 유형을 선택하면 컨텍스트 블로트 및 데이터베이스 쿼리 회귀를 방지할 수 있습니다. 예를 들어 패싯 대신 템플릿을 사용하면 규칙이 중복될 수 있으며, 템플릿으로 충분한 곳에 값 검색을 도입하면 쿼리 지연 시간이 늘어날 수 있습니다. 올바른 스키마 형식을 찾으려면 컨텍스트 항목을 만들기 전에 질문 구조 또는 데이터베이스 열을 기반으로 유형을 추천하도록 에이전트에게 요청하세요. 에이전트는 맥락 옵션을 이해할 수 있도록 추론을 설명합니다.
다음 예시 프롬프트를 사용하여 에이전트에게 지시할 수 있습니다.
- "여러 쿼리에
departure_time BETWEEN '00:00:00' AND '06:00:00'필터를 계속 작성하고 있습니다. 이 내용을 가장 잘 포착하는 방법은 무엇인가요?' - "사용자가 자유 텍스트로 항공편 상태를 설명하면 이를
flights.status와 매칭하고 싶어. 어떤 종류의 값 검색을 설정해야 하나요?' - '템플릿과 패싯의 차이점은 무엇이며 각각 언제 사용해야 하나요?'
컨텍스트 세트에 일괄 작업 적용
에이전트는 대규모 컨텍스트 세트를 일관되게 관리하기 위해 일괄 업데이트를 지원합니다. 데이터베이스 열의 이름이 바뀌거나, 코드 값의 형식이 변경되거나, 템플릿이 지원 중단된 테이블을 참조하는 등 여러 컨텍스트 항목을 동시에 업데이트해야 하는 경우 에이전트는 관련 없는 항목을 변경하지 않고 영향을 받는 모든 항목에 변경사항을 적용할 수 있습니다.
다음 예시 프롬프트를 사용하여 에이전트에게 지시할 수 있습니다.
- '
golden.txt을 읽고 모든 쌍을 템플릿으로 변환해 줘.' - 'United'를 참조하는 항목의 경우
context_set.json에서airline = 'UA'를airline = 'United Airlines'로 바꿉니다. 관련 없는 항목은 그대로 두세요.'
다음 단계
- 컨텍스트 세트에 대해 자세히 알아보세요.
- Spanner Studio에서 컨텍스트 세트를 만들거나 삭제하는 방법을 알아보세요.
- 컨텍스트 세트를 테스트하는 방법을 알아보세요.