
En este instructivo, se describe una conmutación por error completa de recuperación ante desastres (DR) y un proceso de resguardo en Cloud SQL para MySQL con réplicas de lectura entre regiones.
Aquí configurarás una instancia de Cloud SQL para MySQL de alta disponibilidad para DR y simularás una interrupción. Luego, realizarás el proceso de DR a fin de recuperar tu implementación inicial después de que se haya resuelto la interrupción.
Este instructivo está dirigido a ingenieros, administradores y arquitectos de bases de datos.
Para leer una descripción general sobre cómo funciona la recuperación ante desastres de SQL, consulta Información sobre la recuperación ante desastres en Cloud SQL.
Objetivos
- Crear una instancia Cloud SQL para MySQL de alta disponibilidad
- Implementar una réplica de lectura entre regiones en Google Cloud con Cloud SQL para MySQL
- Simular un desastre y una conmutación por error con Cloud SQL para MySQL
- Comprender los pasos para recuperar la implementación inicial usando un resguardo con Cloud SQL para MySQL
Este documento se centra solo en los procesos de conmutación por error y resguardo de DR entre regiones. Para obtener información sobre un proceso de conmutación por error con alta disponibilidad de una sola región, consulta Descripción general de la configuración de alta disponibilidad.
Costos
En este documento, usarás los siguientes componentes facturables de Google Cloud:
Para obtener una estimación de costos en función del uso previsto,
usa la calculadora de precios.
Cuando completes las tareas que se describen en este documento, podrás borrar los recursos que creaste para evitar que se te siga facturando. Para obtener más información, consulta Realiza una limpieza.
Antes de comenzar
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, activate Cloud Shell.
Fase 1: Configura una instancia de base de datos de alta disponibilidad para DR
Las siguientes fases (de 1 a 3) te guiarán a través de un proceso de conmutación por error y resguardo completo. Ejecuta todos los comandos usando el comando
gclouden Cloud Shell. Para simplificar el proceso, en el instructivo se usa la configuración predeterminada cuando es posible (por ejemplo, la versión predeterminada de Cloud SQL). En tu entorno de producción, puedes agregar otras opciones de configuración.Configura las variables de entorno
En esta sección, se proporcionan ejemplos de variables de entorno que definen los distintos nombres y regiones que se requieren para los comandos que ejecutarás en este instructivo. Puedes ajustar estas variables de ejemplo para que se adapten a tus necesidades.
En las siguientes tablas, se describen los nombres de instancias, sus roles y regiones de implementación para cada fase del proceso de DR y resguardo de este instructivo. También puedes proporcionar tus propios nombres y regiones.
Fase inicial Nombre de la instancia Rol Región instance-1Principal us-west1instance-2En suspensión us-west1instance-3Réplica de lectura entre regiones us-west2Fase de desastre Nombre de la instancia Rol Región instance-3Principal us-west2instance-4En suspensión us-west2instance-5Réplica de lectura entre regiones us-west3instance-6Réplica de lectura entre regiones us-west1Fase de resguardo (final) Nombre de la instancia Rol Región instance-6Principal us-west1instance-7En suspensión us-west1instance-8Réplica de lectura entre regiones us-west2Los nombres de instancia en las tablas anteriores no están codificados con sus roles. En una situación de DR, la función de una instancia puede cambiar; por ejemplo, una réplica puede convertirse en principal. Si el nombre de la principal nueva contiene la palabra
replica, puede haber conflictos y confusión. Por lo tanto, recomendamos que no se codifiquen nombres de instancias con la función o rol que estas realicen.En las tablas anteriores, se enumeran los nombres de instancias en espera. Aunque en este instructivo no se produce una conmutación por error de alta disponibilidad, en el instructivo se incluyen los nombres de instancias en espera para su finalización.
La fase de resguardo vuelve a crear la implementación original de la fase inicial en las mismas regiones originales. Sin embargo, en un resguardo, los nombres de las instancias deben cambiar porque los nombres originales no están disponibles de inmediato, incluso después de que se borre la instancia original. Para admitir la creación rápida de instancias en la fase de resguardo, debes usar nombres de instancia que no coincidan con los nombres usados en la fase inicial.
En Cloud Shell, configura las variables de entorno que se basen en las especificaciones de las tablas anteriores:
export primary_name=instance-1 export primary_tier=db-n1-standard-2 export primary_region=us-west1 export primary_root_password=my-root-password export primary_backup_start_time=22:00 export cross_region_replica_name=instance-3 export cross_region_replica_region=us-west2Si deseas usar un nivel diferente para la instancia principal, enumera los niveles que estén disponibles para ti y, luego, asigna un valor diferente a primary_tier:
gcloud sql tiers listPara obtener una lista de regiones donde puedes implementar Cloud SQL, consulta Configuración de instancias.
Crea una instancia de base de datos principal
En Cloud Shell, crea una sola instancia de Cloud SQL:
gcloud sql instances create $primary_name \ --tier=$primary_tier \ --region=$primary_regionEl comando
gcloudse detiene hasta que se crea la instancia.Configura la contraseña raíz:
gcloud sql users set-password root \ --host=% \ --instance $primary_name \ --password $primary_root_password
Crea una base de datos principal
En Cloud Shell, accede a la shell de MySQL y escribe la contraseña raíz en el mensaje:
gcloud sql connect $primary_name --user=rootEn el cuadro de MySQL, crea una base de datos y sube datos de prueba:
CREATE DATABASE guestbook; USE guestbook; CREATE TABLE entries (guestName VARCHAR(255), content VARCHAR(255), entryID INT NOT NULL AUTO_INCREMENT, PRIMARY KEY(entryID)); INSERT INTO entries (guestName, content) values ("first guest", "I got here!"); INSERT INTO entries (guestName, content) values ("second guest", "Me too!");Verifica que los datos se hayan confirmado de forma correcta.
SELECT * FROM entries;Verifica que se devuelven dos filas de datos.
Sal de la shell de MySQL:
exit;
En este punto, tienes una sola base de datos que incluye una tabla y algunos datos de prueba.
Cambia la instancia principal a una instancia de base de datos de alta disponibilidad
Solo puedes configurar Cloud SQL como un sistema de alta disponibilidad regional, no como un sistema interregional. (Configurar una réplica de lectura entre regiones es diferente a configurar Cloud SQL como un sistema interregional). Si deseas obtener más información, consulta Habilitar o inhabilitar la alta disponibilidad en una instancia.
En Cloud Shell, crea una instancia de Cloud SQL habilitada para alta disponibilidad:
gcloud sql instances patch $primary_name \ --availability-type REGIONAL \ --enable-bin-log \ --backup-start-time=$primary_backup_start_time
Agrega una réplica de lectura entre regiones para la DR con actualización automática
Los siguientes pasos son suficientes para crear una réplica de lectura entre regiones para este instructivo:
En Cloud Shell, configura una réplica de lectura entre regiones:
gcloud sql instances create $cross_region_replica_name \ --master-instance-name=$primary_name \ --region=$cross_region_replica_region(Opcional) Para verificar que la base de datos se haya replicado, en la consola deGoogle Cloud , ve a la página Instancias de Cloud SQL.
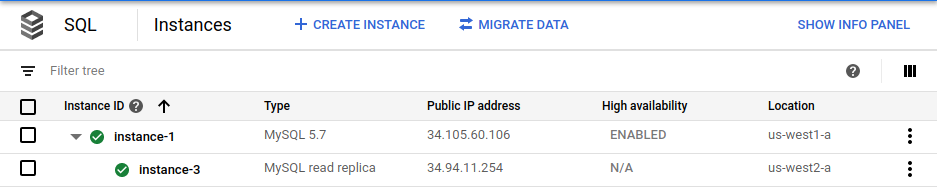
La consola de Google Cloud muestra que la instancia principal (
instance-1) está habilitada para alta disponibilidad y que existe una réplica de lectura entre regiones (instance-3).Con la misma contraseña raíz para la principal, accede a la réplica de lectura entre regiones:
gcloud sql connect $cross_region_replica_name --user=rootCuando aparezca el cuadro de MySQL, selecciona los datos para asegurarte de que la replicación funciona:
USE guestbook; SELECT * FROM entries;Sal de la shell de MySQL:
exit;
Si deseas obtener detalles para configurar una réplica de lectura entre regiones completa, consulta la documentación de Cloud SQL.
Para bases de datos grandes en un entorno de producción, te recomendamos que hagas una copia de seguridad de la base de datos principal y crees la réplica de lectura entre regiones a partir de esa copia. Este paso ayuda a reducir el tiempo que tarda la réplica de lectura en sincronizarse con la base de datos principal. Este proceso se describe en la siguiente sección. Sin embargo, puedes optar por omitir este paso y continuar con la Fase 2.
Agrega una réplica de lectura entre regiones según un archivo de volcado
Una forma de optimizar la creación de una réplica de lectura entre regiones es sincronizar la réplica de un estado de base de datos principal anterior y coherente, en lugar de sincronizarla en el momento en que se accede a la principal nueva. Esta optimización requiere la creación de un archivo de volcado que la réplica usa como estado de inicio.
Si quieres conocer los pasos para crear una réplica basada en un archivo de volcado, consulta Replicar desde un servidor externo a Cloud SQL (v1.1). Este enfoque puede ser útil para bases de datos de producción grandes. Sin embargo, en este instructivo se omite este paso, ya que el conjunto de datos de prueba es lo suficientemente pequeño como para llevar a cabo una replicación completa.
Fase 2: Simula un desastre (interrupción de la región)
En esta fase, simularás la interrupción de una región principal en una configuración de producción haciendo que la base de datos principal no esté disponible.
Verifica el retraso de réplica de lectura entre regiones
En los pasos siguientes, determinarás el retraso de replicación de la réplica de lectura entre regiones:
En la consola de Google Cloud , ve a la página Instancias de Cloud SQL.
Haz clic en la réplica de lectura (instance-3).
En la lista desplegable de métricas, haz clic en Retraso de la replicación:
La métrica cambia a Retraso de la replicación. El gráfico no muestra retrasos:
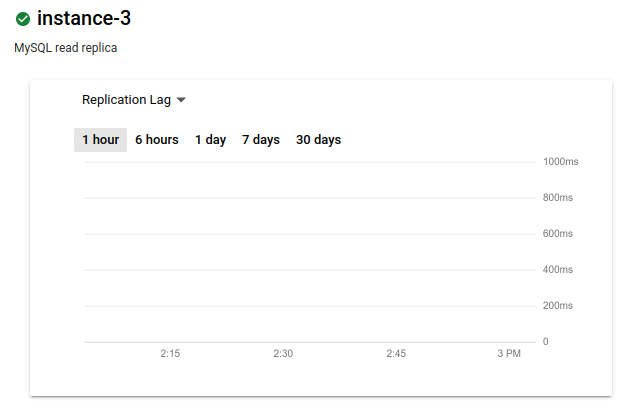
Lo ideal es que el retraso de la replicación sea cero cuando se produce una interrupción de la región principal, ya que una demora de cero garantiza que todas las transacciones se repliquen. Si no es cero, es posible que algunas transacciones no se repliquen. En este caso, la réplica de lectura entre regiones no contendrá todas las transacciones confirmadas en la principal.
Haz que la instancia principal no esté disponible
En los siguientes pasos, simularás un desastre deteniendo la principal. Si se adjunta una réplica de lectura entre regiones a la instancia principal, primero debes desconectar la réplica; de lo contrario, no podrás detener la instancia de Cloud SQL.
En Cloud Shell, quita la réplica de lectura entre regiones de la principal:
gcloud sql instances patch $cross_region_replica_name \ --no-enable-database-replicationCuando se te indique, acepta la opción para continuar.
Detén la instancia de base de datos principal:
gcloud sql instances patch $primary_name --activation-policy NEVER
Implementa la DR
En Cloud Shell, asciende la réplica de lectura entre regiones a una instancia independiente:
gcloud sql instances promote-replica $cross_region_replica_nameCuando se te indique, acepta la opción para continuar. La página Instancias de Cloud SQL muestra la réplica de lectura entre regiones anterior (
instance-3) como la instancia principal nueva; y la principal anterior (instance-1) se muestra como detenida:
Luego de promover la réplica de lectura entre regiones como la nueva instancia principal, la habilitas para alta disponibilidad. Como práctica recomendada, debes actualizar las variables de entorno con una denominación adecuada.
Actualiza las variables de entorno:
export former_primary_name=$primary_name export primary_name=$cross_region_replica_name export primary_tier=db-n1-standard-2 export primary_region=$cross_region_replica_region export primary_root_password=my-root-password export primary_backup_start_time=22:00 export cross_region_replica_name=instance-5 export cross_region_replica_region=us-west3Inicia la principal nueva:
gcloud sql instances patch $primary_name --activation-policy ALWAYSHabilita la instancia principal nueva como una instancia regional de alta disponibilidad:
gcloud sql instances patch $primary_name \ --availability-type REGIONAL \ --enable-bin-log \ --backup-start-time=$backup_start_timeCrea una réplica de lectura entre regiones en una tercera región:
gcloud sql instances create $cross_region_replica_name \ --master-instance-name=$primary_name \ --region=$cross_region_replica_regionEn un paso anterior, estableciste la variable de entorno
cross_region_replica_regionenus-west3.Una vez que se completa la conmutación por error, la página Instancias de Cloud SQL en la consola de Google Cloud muestra que la nueva instancia principal ( Google Cloud ) está habilitada como de alta disponibilidad y tiene una réplica de lectura entre regiones (
instance-3):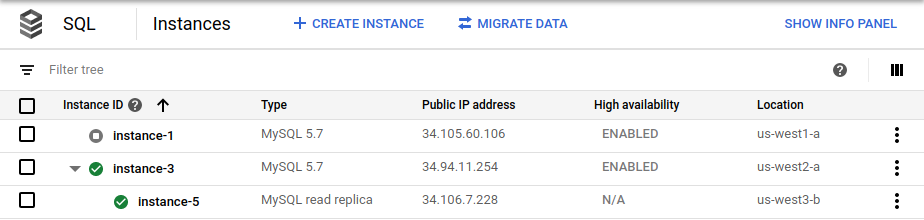
(Opcional) Si tienes copias de seguridad regulares, sigue el proceso que se describió antes para sincronizar la versión principal nueva con la última versión de la copia de seguridad.
(Opcional) Si usas un proxy de Cloud SQL, configura el proxy para que use la instancia principal nueva a fin de reanudar el procesamiento de la aplicación.
Controla una interrupción de región de corta duración
Es posible que la interrupción que activa una conmutación por error se resuelva antes de que la conmutación de complete. En este caso, tendría sentido cancelar el proceso de conmutación por error y seguir usando la instancia principal de Cloud SQL original en la región donde se produjo la interrupción.
Según el estado específico del proceso de conmutación por error, la réplica de lectura entre regiones ya podría haberse ascendido. En este caso, debes borrarla y volver a crear una réplica de lectura entre regiones.
Borra la principal original para evitar una situación de cerebro dividido
Para evitar una situación de cerebro dividido, debes borrar la principal original (o hacer que sea inaccesible para los clientes de la base de datos).
Después de una conmutación por error, una situación de cerebro dividido puede ocurrir cuando los clientes escriben en la base de datos principal original y en la nueva base de datos principal al mismo tiempo. En este caso, el contenido de las dos bases de datos no es coherente. Después de una conmutación por error, la base de datos principal original está desactualizada y no debe recibir tráfico de lectura o escritura.
En Cloud Shell, borra la principal original:
gcloud sql instances delete $former_primary_nameCuando se te indique, acepta la opción para continuar.
En la consola de Google Cloud , la página Instancias de Cloud SQL ya no muestra la instancia principal original (
instance-1) como parte de la implementación: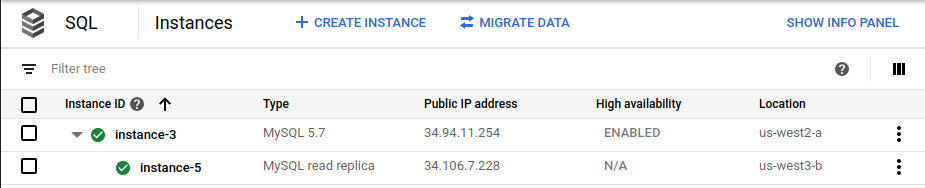
Fase 3: Implementa un resguardo
Para implementar un resguardo en tu región original (R1), una vez que esté disponible, sigue el mismo proceso que se describe en la Fase 2. Este proceso se resume de la siguiente manera:
Crea una segunda réplica de lectura entre regiones en la región original (R1). En este punto, la instancia principal tiene dos réplicas de lectura entre regiones: una en la región R3 y otra en la región R1.
Promueve la réplica de lectura entre regiones en R1 como la instancia principal final.
Habilita la alta disponibilidad para la principal final.
Crea una réplica de lectura entre regiones de la instancia principal final en
us-west2.Para evitar una situación de cerebro dividido, borra todas las instancias que ya no sean necesarias (la principal original y la réplica de lectura entre regiones en R3).
Como se explicó antes, se recomienda crear una copia de seguridad inicial que contenga el estado de inicio definido para la nueva base de datos principal.
La implementación final ahora tiene una instancia principal de alta disponibilidad (con el nombre
instance-6) y una réplica de lectura entre regiones (con el nombreinstance-8).Compara las ventajas y desventajas de una DR manual y una automática
En la siguiente tabla, se analizan las ventajas y las desventajas de implementar un proceso de DR de forma manual o automática. El objetivo no es determinar un enfoque correcto frente a uno incorrecto, sino también proporcionar criterios que te ayuden a determinar el mejor enfoque para tus necesidades.
Ejecución manual Ejecución automática Ventajas
- Tienes control estricto sobre cada paso.
- Puedes ver, abordar y documentar de inmediato cualquier problema en el proceso.
- Puedes ver y revisar cada paso del proceso durante una conmutación por error.
Ventajas
- Puedes implementar y probar los procesos de conmutación por error.
- La automatización ofrece la implementación más rápida y minimiza los retrasos.
- La implementación no depende de los operadores humanos, su conocimiento ni disponibilidad.
Desventajas:
- La implementación manual de los pasos del proceso ralentiza el proceso.
- Los errores de escritura humana pueden generar problemas.
- Por lo general, probar el proceso implica varios roles y tiempo, lo que puede desalentar las pruebas regulares.
Desventajas:
- Si se produce un error inesperado, debes realizar una depuración durante la conmutación por error de producción.
- Si encuentras errores durante el proceso, necesitas secuencias de comandos para retomar (recuperar) desde el punto donde se detuvo el proceso.
- Se requiere el conocimiento suficiente de la secuencia de comandos y de su implementación para comprender su comportamiento, en especial en situaciones de error.
Como práctica recomendada, te sugerimos que comiences con una implementación manual. Luego, ejecuta la implementación regularmente (en lo posible, en producción) para garantizar que el proceso manual funcione y que todos los miembros del equipo conozcan sus roles y responsabilidades. Te recomendamos que definas tu proceso manual en un documento de proceso paso a paso. Después de cada implementación, debes confirmar o definir mejor el documento del proceso.
Después de ajustar el proceso y asegurarte de que sea confiable, determinas si deseas automatizar el proceso. Si seleccionas y, luego, implementas un proceso automatizado, debes probar el proceso de forma periódica en producción para garantizar que puedas implementarlo de manera confiable.
Realiza una limpieza
Para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos que usaste en este instructivo, puedes borrar el proyecto de Google Cloud que creaste para este instructivo.
Borra el proyecto
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
¿Qué sigue?
- Lee sobre la recuperación ante desastres de Cloud SQL.
- Lee sobre la recuperación ante desastres para MySQL en Compute Engine.
- Obtén información sobre las arquitecturas de recuperación ante desastres para interrupciones de la infraestructura de nube.
- Explora arquitecturas de referencia, diagramas y prácticas recomendadas sobre Google Cloud. Consulta el Cloud Architecture Center.