
类型
Manufacturing Data Engine (MDE) 可帮助您通过解析将一类源消息转换为特定类型的记录。
类型是配置实体,表示解析操作的目标,并描述一组结构和语义上相似的记录,这些记录具有共同的粒度级别,并且可以选择性地共享特定的元数据上下文。
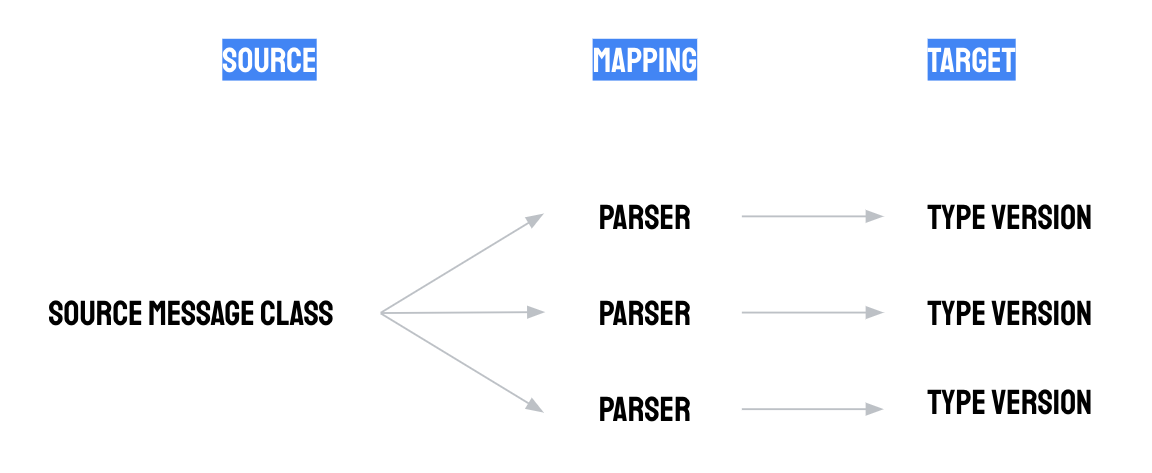
例如,您可以创建“机器状态”和“振动传感器读数”类型。第一种类型可用于对机器状态更改事件(例如“运行”“空闲”“计划内维护”和“计划外维护”)进行建模,而第二种类型可用于对数字振动传感器读数流进行建模。
MDE 附带一组默认类型,但您可以创建新类型。类型由以下特征定义:
- 名称:类型的名称。
- 原型:类型所基于的原型的名称。MDE 中的类型始终与一个原型相关联
- 存储规范:每个数据接收器的设置列表。存储规范允许配置是否将记录写入数据接收器,并允许提供更多接收器专用设置。
- 可选配置参数,包括:
- 数据字段的 JSON 架构(仅适用于离散和连续原型类型)。
- 元数据存储桶关联:一种元数据存储桶的列表,其中记录的类型必须提供实例引用。
类型和数据接收器
给定类型的记录流由针对该类型启用的数据接收器处理。您可以为类型启用(启用或停用)数据接收器。例如,您可以将某种类型的记录配置为写入 BigQuery,但不写入 Cloud Storage。
支持的数据接收器
MDE 支持以下数据接收器:
- BigQuery
- Bigtable/Federation API
- Cloud Storage
- Pub/Sub(JSON 和 Protobuf)
BigQuery 数据接收器
创建新类型时,MDE 会自动在 BigQuery 的 mde_data 数据集中创建相应的类型表。每种类型的记录都会写入相应的类型表。
Cloud Storage 数据接收器
记录存储在名为 <project_id>-gcs-ingestion 的 Cloud Storage 存储桶中,以 AVRO 文件格式存储,并使用 Hive 分区(10 分钟窗口,每个窗口 10 个分区)。记录按类型分组到文件夹中。
Pub/Sub 数据接收器
Pub/Sub 接收器将记录发布到专用主题。Pub/Sub 消息架构在 Pub/Sub sink 消息架构中进行了说明。
元数据具体化
可以配置类型上的每个数据接收器,以在记录中具体化元数据。如果启用此设置,元数据实例引用会解析为元数据实例对象,并且这些对象会包含在记录中。元数据的持久保留或输出的具体方式取决于数据接收器。例如,在 BigQuery 中,具体化元数据会写入具有以下架构的 materialized_metadata_field:
{
"$schema": "http://json-schema.org/draft-04/schema#",
"type": "object",
"additionalProperties": {
"type": "object",
"description": "Metadata instance"
}
}
原型
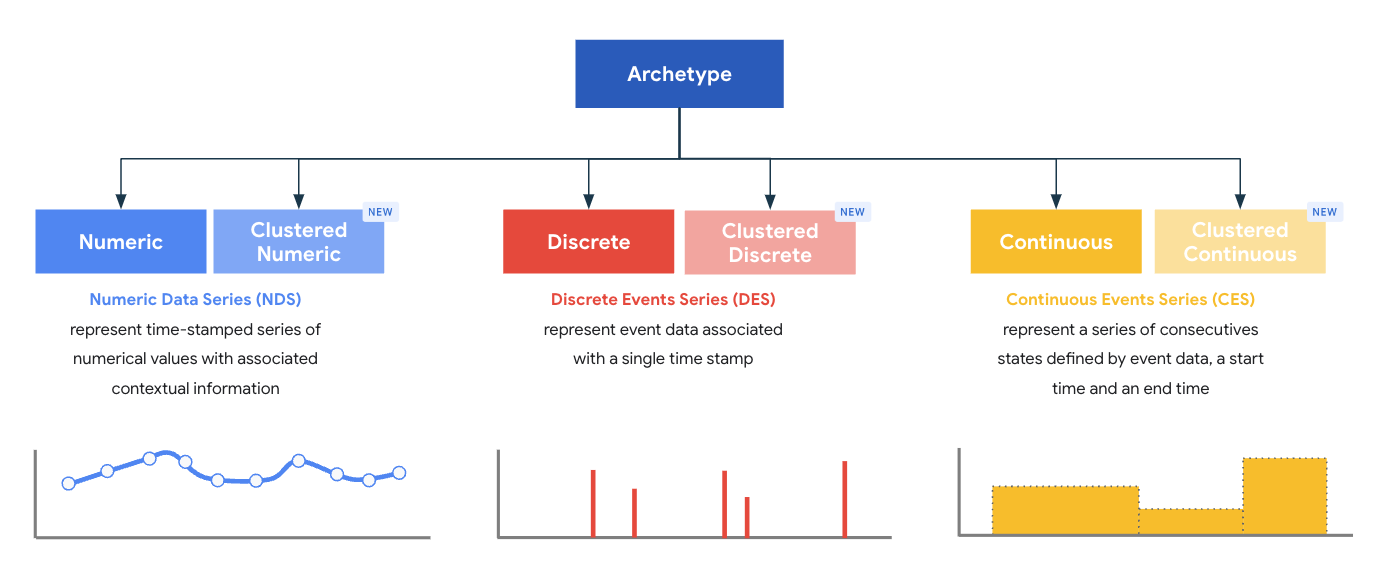
原型表示类型的父类,每个原型都旨在为记录提供最佳处理和存储模型。原型定义了必须存在于解析器发出的给定类型记录中的核心必填字段。MDE 随附一组六个系统定义的标准和聚类原型,分为三个原型系列:
- 数值数据系列 (NDS)
- 离散数据系列 (DDS)
- 连续数据系列 (CDS)
MDE 中的类型始终与一个原型相关联,并且类型的原型是在创建时定义的。
除了原型施加的限制之外,您还可以使用类型来进一步限制解析器发出的 proto 记录。例如,您可以为某种类型指定 data 字段的形状,也可以定义某种类型的记录必须通过特定元数据进行情境化。
总而言之,Proto 记录架构是以下各项的组合:
- 原型架构
- 类型架构
原型系列
每个原型系列都包含两种类型的原型:
- 标准
- 聚类
MDE v1.3 引入了聚类原型的概念,该概念扩展了标准原型的功能。聚类原型提供了四个通用字段,这些字段可以使用解析器中的值进行填充。每个数据接收器都使用以下四个字段来提供额外的查询和数据访问权限功能:
- BigQuery:BigQuery 中的聚簇类型表按顺序由四个通用字段聚簇。这样一来,您就可以根据聚簇字段在 BigQuery 中高效地过滤数据。
- Bigtable Federation API:联合查询 API 使用聚类字段在 Bigtable 中构建行键,从而实现新的数据访问模式。
- Pub/Sub:Pub/Sub 消息将这些字段作为 Pub/Sub 消息中的第一级字段传递。
数字原型系列
数字原型系列旨在作为对一系列带时间戳的数字消息(例如,发出读数流的温度传感器)进行建模的类型的基础。
原型(标准版和集群版)定义了以下基本记录架构:
标准
| 字段 | 数据类型 | 必需 |
|---|---|---|
tagName |
字符串 | 是 |
value |
数字 | 是 |
eventTimestamp |
整数(格式为纪元毫秒数) | 是 |
聚类
| 字段 | 数据类型 | 必需 |
|---|---|---|
tagName |
字符串 | 是 |
value |
数字 | 是 |
eventTimestamp |
整数(格式为纪元毫秒数) | 是 |
clustered_column_1 |
字符串 | 否 |
clustered_column_2 |
字符串 | 否 |
clustered_column_3 |
字符串 | 否 |
clustered_column_4 |
字符串 | 否 |
离散原型系列
离散原型系列旨在作为对带时间戳的事件(例如特定机器或流程中由操作员驱动的参数更改)进行建模的类型的基础。
原型(标准版和集群版)定义了以下基本记录架构:
标准
| 字段 | 数据类型 | 必需 |
|---|---|---|
tagName |
字符串 | 是 |
data |
JSON 对象 | 是 |
eventTimestamp |
整数(格式为纪元毫秒数) | 是 |
聚类
| 字段 | 数据类型 | 必需 |
|---|---|---|
tagName |
字符串 | 是 |
data |
JSON 对象 | 是 |
eventTimestamp |
整数(格式为纪元毫秒数) | 是 |
clustered_column_1 |
字符串 | 否 |
clustered_column_2 |
字符串 | 否 |
clustered_column_3 |
字符串 | 否 |
clustered_column_4 |
字符串 | 否 |
连续型原型系列
连续原型系列旨在作为以下类型的基础:用于对由开始和结束时间戳定义的一系列连续状态进行建模,例如机器在一段连续时间内的运行状态。
原型(标准版和集群版)定义了以下基本记录架构:
标准
| 字段 | 数据类型 | 必需 |
|---|---|---|
tagName |
字符串 | 是 |
data |
JSON 对象 | 是 |
eventTimestampStart |
整数(格式为纪元毫秒数) | 是 |
eventTimestampEnd |
整数(格式为纪元毫秒数) | 是 |
聚类
| 字段 | 数据类型 | 必需 |
|---|---|---|
tagName |
字符串 | 是 |
data |
JSON 对象 | 是 |
eventTimestampStart |
整数(格式为纪元毫秒数) | 是 |
eventTimestampEnd |
整数(格式为纪元毫秒数) | 是 |
clustered_column_1 |
字符串 | 否 |
clustered_column_2 |
字符串 | 否 |
clustered_column_3 |
字符串 | 否 |
clustered_column_4 |
字符串 | 否 |
“Data”(数据)字段
离散数据系列和连续数据系列原型接受 data 字段的 JSON 架构。如果定义了字段的 JSON 架构,则在运行时,系统会根据该架构验证解析器发出的记录中包含的 data 字段的值。例如,假设您为离散时序类型定义了以下架构:
{
"$schema": "http://json-schema.org/draft-04/schema#",
"type": "object",
"properties": {
"eventName": {
"type": "string"
}
},
"required": ["eventName"]
}
对于离散时序类型,如果采用之前的架构,解析器发出的以下(部分)记录将无效:
{
"data": {
"complex": {
"machineName": "example"
}
}
}
如果数据验证失败,记录会被移至死信队列。死信队列中的记录稍后可以手动处理。
元数据存储分区
类型可以引用元数据桶。类型上的元数据存储桶引用用于定义记录是否可以或必须(取决于 required 属性的值)提供对元数据存储桶实例的引用。
类型上的元数据存储桶引用定义了相应类型记录的元数据协定。例如,您可以定义某种类型的所有记录都必须通过设备元数据进行情境化(在名为 device 的元数据存储桶中提供对元数据实例的引用)。
如果元数据存储桶与某个类型相关联,并且 required 标志设置为 true,则由不提供对元数据存储桶实例的引用的解析器发出的该类型的记录会被移至死信队列。如需了解详情,请参阅如何重新处理消息。
类型版本控制
版本控制类型有很多种,以下部分将分别介绍每种类型。
创建新的类型版本
您可以为特定类型创建新版本。每个新版本都可以指定其他元数据存储桶关联,或修改数据字段的架构。不过,为了确保类型在整个生命周期内的数据一致性,新类型版本只能向前演进,并且必须遵守版本控制规则。新版本的类型可以进行以下更改:
5 月:
- 向数据架构添加新的可选字段。
- 将数据架构中的必需字段标记为可选。
- 添加了新的元数据存储桶引用。
不得:
- 从数据架构中移除字段。
- 更改数据架构中现有字段的数据类型。
- 在数据架构中将可选属性标记为必需属性。
- 移除元数据存储桶引用。
现有类型版本编辑
您可以在现有类型版本上更新存储规范和转换,而无需创建新的类型版本。
输入修改
对类型执行的大多数操作都需要创建新的类型版本或修改现有类型版本。可以对独立于其版本的类型执行的唯一操作是启用或停用该类型。停用某个类型后,该类型的所有版本都会停止接受数据。
类型的命名限制
类型名称可以包含以下内容:
- 字母(大写和小写)、数字以及特殊字符
-和_。 - 最长不得超过 255 个字符。
您可以使用以下正则表达式进行验证:^[a-z][a-z0-9\\-_]{1,255}$。
如果您尝试创建违反命名限制的实体,则会收到 400 error。