
Tipo
O Manufacturing Data Engine (MDE) ajuda a transformar uma classe de mensagens de origem em registros de um tipo específico por meio da análise.
Os tipos são entidades de configuração que representam o destino da operação de análise e descrevem um conjunto de registros estruturalmente e semanticamente semelhantes com um nível comum de granularidade que, opcionalmente, compartilham um contexto de metadados específico.
Por exemplo, é possível criar tipos de "estado da máquina" e "leituras do sensor de vibração". O primeiro tipo pode ser usado para modelar eventos de mudança de estado da máquina, como "Em execução", "Inativo", "Manutenção programada" e "Manutenção não programada", enquanto o segundo pode ser usado para modelar um fluxo de leituras numéricas do sensor de vibração.
O MDE é fornecido com um conjunto de tipos padrão, mas é possível criar novos. Os tipos são definidos pelas seguintes características:
- Nome: o nome do tipo.
- Arquétipo: o nome do arquétipo em que um tipo é baseado. Um tipo no MDE é sempre associado a exatamente um arquétipo.
- Especificações de armazenamento: uma lista de configurações por coletor de dados. As especificações de armazenamento permitem configurar se os registros são gravados em um coletor de dados e fornecer outras configurações específicas do coletor.
- Parâmetros de configuração opcionais, incluindo:
- O esquema JSON do campo data (aplicável apenas a tipos de arquétipos discretos e contínuos).
- Associações de buckets de metadados: uma lista de buckets de metadados para os quais os registros do tipo precisam fornecer referências de instância.
Tipos e coletores de dados
O fluxo de registros de um determinado tipo é processado por coletores de dados ativados para um tipo. Os coletores de dados podem ser ativados (ativados ou desativados) para tipos. Por exemplo, os registros de um tipo podem ser configurados para serem gravados no BigQuery, mas não no Cloud Storage.
Coletores de dados compatíveis
O MDE é compatível com os seguintes coletores de dados:
- BigQuery
- API Bigtable/Federation
- Cloud Storage
- Pub/Sub (JSON e Protobuf)
Coletor de dados do BigQuery
Quando um novo tipo é criado, o MDE cria automaticamente uma tabela de tipo correspondente no BigQuery no conjunto de dados mde_data.
Os registros de cada tipo são gravados na tabela de tipo correspondente.
Coletor de dados do Cloud Storage
Os registros são armazenados em um bucket do Cloud Storage chamado
<project_id>-gcs-ingestion em arquivos AVRO usando o particionamento do Hive com uma janela de 10
minutos e 10 partições por janela. Os registros são agrupados em pastas por tipo.
Coletor de dados do Pub/Sub
O coletor do Pub/Sub publica registros em um tópico dedicado. O esquema de mensagens do Pub/Sub é descrito no esquema de mensagens do coletor do Pub/Sub.
Materialização de metadados
Cada coletor de dados em um tipo pode ser configurado para materializar metadados em registros. Se essa configuração estiver ativada, as referências de instância de metadados serão resolvidas para objetos de instância de metadados, e os objetos serão incluídos nos registros. A maneira precisa como os metadados são mantidos ou gerados depende do coletor de dados.
No BigQuery, por exemplo, os metadados materializados são gravados no materialized_metadata_field com o seguinte esquema:
{
"$schema": "http://json-schema.org/draft-04/schema#",
"type": "object",
"additionalProperties": {
"type": "object",
"description": "Metadata instance"
}
}
Arquétipos
Os arquétipos representam uma superclasse de tipos, e cada arquétipo foi projetado para fornecer um modelo ideal de processamento e armazenamento de registros. Os arquétipos definem os campos obrigatórios principais que precisam estar presentes em um registro de um determinado tipo emitido por um analisador. O MDE é fornecido com um conjunto de seis arquétipos padrão e agrupados definidos pelo sistema em três famílias de arquétipos:
- Série de dados numéricos (NDS)
- Série de dados discretos (DDS)
- Série de dados contínuos (CDS)
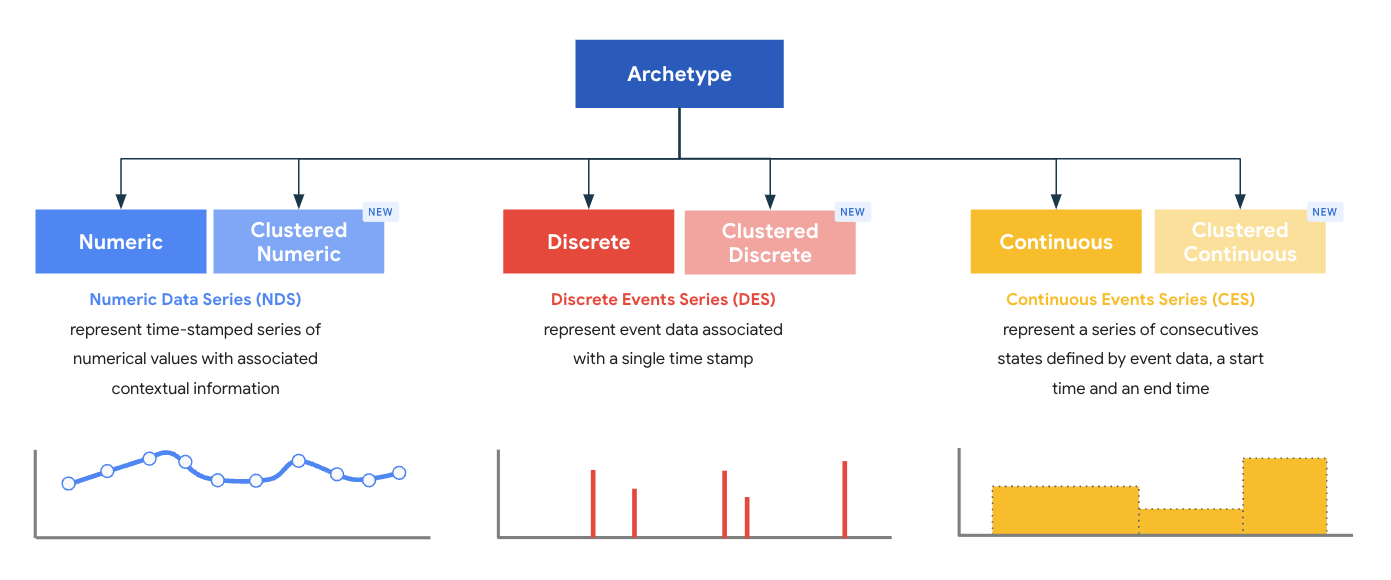
Um tipo no MDE é sempre associado a exatamente um arquétipo, e o arquétipo de um tipo é definido no momento da criação.
É possível usar tipos para definir outras restrições em registros proto emitidos por analisadores além daqueles impostos por arquétipos. Por exemplo, é possível especificar o formato do campo data para um tipo ou definir que os registros de um tipo precisam ser contextualizados por metadados específicos.
Em resumo, o esquema de registro proto é uma combinação de:
- Esquema de arquétipo
- Esquema de tipo
Famílias de arquétipos
Cada família de arquétipos contém dois tipos de arquétipos:
- Padrão
- Agrupado
O MDE v1.3 apresenta o conceito de arquétipos agrupados, que estendem a funcionalidade dos arquétipos padrão. Os arquétipos agrupados fornecem quatro campos genéricos que podem ser preenchidos com valores no analisador. Cada coletor de dados usa esses quatro campos para fornecer outros recursos de consulta e acesso a dados:
- BigQuery: as tabelas de tipo agrupadas no BigQuery são agrupadas pelos quatro campos genéricos em ordem. Isso permite filtrar dados no BigQuery de maneira eficiente nos campos agrupados.
- API Bigtable Federation: a API Federation usou os campos agrupados para construir chaves de linha no Bigtable, permitindo novos padrões de acesso a dados.
- Pub/Sub: as mensagens do Pub/Sub transmitem os campos como campos de primeiro nível na mensagem do Pub/Sub.
Família de arquétipos numéricos
A família de arquétipos numéricos foi projetada para servir como base para tipos que modelam uma série de mensagens numéricas com carimbo de data/hora, por exemplo, um sensor de temperatura que emite um fluxo de leituras.
As versões padrão e agrupada do arquétipo definem os seguintes esquemas de registro base:
Padrão
| Campo | Tipo de dado | Obrigatório |
|---|---|---|
tagName |
String | Sim |
value |
Numérico | Sim |
eventTimestamp |
Número inteiro (formatado como ms de época) | Sim |
Agrupado
| Campo | Tipo de dado | Obrigatório |
|---|---|---|
tagName |
String | Sim |
value |
Numérico | Sim |
eventTimestamp |
Número inteiro (formatado como ms de época) | Sim |
clustered_column_1 |
String | Não |
clustered_column_2 |
String | Não |
clustered_column_3 |
String | Não |
clustered_column_4 |
String | Não |
Família de arquétipos discretos
A família de arquétipos discretos foi projetada para servir como base para tipos que modelam eventos com carimbo de data/hora, por exemplo, uma mudança de parâmetro orientada pelo operador em uma máquina ou processo específico.
As versões padrão e agrupada do arquétipo definem os seguintes esquemas de registro base:
Padrão
| Campo | Tipo de dado | Obrigatório |
|---|---|---|
tagName |
String | Sim |
data |
objeto JSON | Sim |
eventTimestamp |
Número inteiro (formatado como ms de época) | Sim |
Agrupado
| Campo | Tipo de dado | Obrigatório |
|---|---|---|
tagName |
String | Sim |
data |
objeto JSON | Sim |
eventTimestamp |
Número inteiro (formatado como ms de época) | Sim |
clustered_column_1 |
String | Não |
clustered_column_2 |
String | Não |
clustered_column_3 |
String | Não |
clustered_column_4 |
String | Não |
Família de arquétipos contínuos
A família de arquétipos contínuos foi projetada para servir como base para tipos que modelam séries de estados consecutivos definidos por um carimbo de data/hora de início e fim, por exemplo, o estado operacional de uma máquina por um período contínuo.
As versões padrão e agrupada do arquétipo definem os seguintes esquemas de registro base:
Padrão
| Campo | Tipo de dado | Obrigatório |
|---|---|---|
tagName |
String | Sim |
data |
objeto JSON | Sim |
eventTimestampStart |
Número inteiro (formatado como ms de época) | Sim |
eventTimestampEnd |
Número inteiro (formatado como ms de época) | Sim |
Agrupado
| Campo | Tipo de dado | Obrigatório |
|---|---|---|
tagName |
String | Sim |
data |
objeto JSON | Sim |
eventTimestampStart |
Número inteiro (formatado como ms de época) | Sim |
eventTimestampEnd |
Número inteiro (formatado como ms de época) | Sim |
clustered_column_1 |
String | Não |
clustered_column_2 |
String | Não |
clustered_column_3 |
String | Não |
clustered_column_4 |
String | Não |
Campo de dados
Os arquétipos série de dados discretos e série de dados contínuos aceitam um esquema JSON para o campo data. Se um esquema JSON para o campo for definido, o valor do campo data contido em um registro emitido por um analisador será validado em relação ao esquema no tempo de execução. Por exemplo, imagine que você defina o seguinte esquema para um tipo de série temporal discreta:
{
"$schema": "http://json-schema.org/draft-04/schema#",
"type": "object",
"properties": {
"eventName": {
"type": "string"
}
},
"required": ["eventName"]
}
Com o esquema anterior para um tipo de série temporal discreta, o registro (parcial) a seguir desse tipo emitido por um analisador não é válido:
{
"data": {
"complex": {
"machineName": "example"
}
}
}
Se a validação de dados falhar, os registros serão movidos para a fila de mensagens não entregues. Os registros na fila de mensagens não entregues podem ser processados manualmente mais tarde.
Buckets de metadados
Os tipos podem referenciar buckets de metadados. Uma referência de bucket de metadados em um tipo define se os registros podem ou precisam (dependendo do valor do atributo required) fornecer uma referência a uma instância de bucket de metadados.
As referências de bucket de metadados em um tipo definem o contrato de metadados para registros desse tipo. Por exemplo, é possível definir que todos os registros de um tipo precisam ser contextualizados com metadados do dispositivo (fornecer uma referência a uma instância de metadados em um bucket de metadados chamado dispositivo).
Se um bucket de metadados estiver associado a um tipo e a flag required estiver definida como true, os registros desse tipo emitidos por um analisador que não fornecem uma referência a uma instância de bucket de metadados serão movidos para a fila de mensagens não entregues. Para
mais informações, consulte Consulte
Como reprocessar mensagens.
Controle de versões de tipo
Há diferentes tipos de controle de versões, e as seções a seguir descrevem cada um deles.
Criação de uma nova versão de tipo
É possível criar novas versões para um tipo específico. Cada nova versão pode especificar outras associações de bucket de metadados ou modificar o esquema do campo de dados. No entanto, para garantir a consistência dos dados durante o ciclo de vida de um tipo, as novas versões de tipo só podem evoluir para frente e precisam obedecer às regras de controle de versões. Novas versões de um tipo podem fazer as seguintes mudanças:
Pode:
- Adicionar novos campos opcionais ao esquema de dados.
- Marcar um campo obrigatório como opcional para o esquema de dados.
- Adicionar novas referências de bucket de metadados.
Não pode:
- Remover campos do esquema de dados.
- Mudar o tipo de dados dos campos atuais no esquema de dados.
- Marcar um atributo opcional como obrigatório no esquema de dados.
- Remover referências de bucket de metadados.
Edição da versão de tipo atual
As especificações de armazenamento e as transformações podem ser atualizadas em uma versão de tipo atual sem a necessidade de criar uma nova versão de tipo.
Edição de tipo
A maioria das operações em tipos exige a criação de uma nova versão de tipo ou a edição de uma versão de tipo atual. A única operação que pode ser realizada no tipo independente da versão é ativá-lo ou desativá-lo. Quando um tipo é desativado, todas as versões desse tipo param de aceitar dados.
Restrições de nomenclatura para tipos
Um nome de tipo pode conter o seguinte:
- Letras (maiúsculas e minúsculas), números e os caracteres especiais
-e_. - Pode ter até 255 caracteres.
É possível usar a seguinte expressão regular para validação: ^[a-z][a-z0-9\\-_]{1,255}$.
Se você tentar criar uma entidade que viole as restrições de nomenclatura, receberá um 400 error.