
유형
Manufacturing Data Engine (MDE)을 사용하면 파싱을 통해 소스 메시지 클래스를 특정 유형의 레코드로 변환할 수 있습니다.
유형은 파싱 작업의 타겟을 나타내는 구성 항목이며, 공통된 세부사항 수준을 갖는 구조적, 의미적으로 유사한 레코드 집합을 설명합니다. 이러한 레코드 집합은 선택적으로 특정 메타데이터 컨텍스트를 공유합니다.
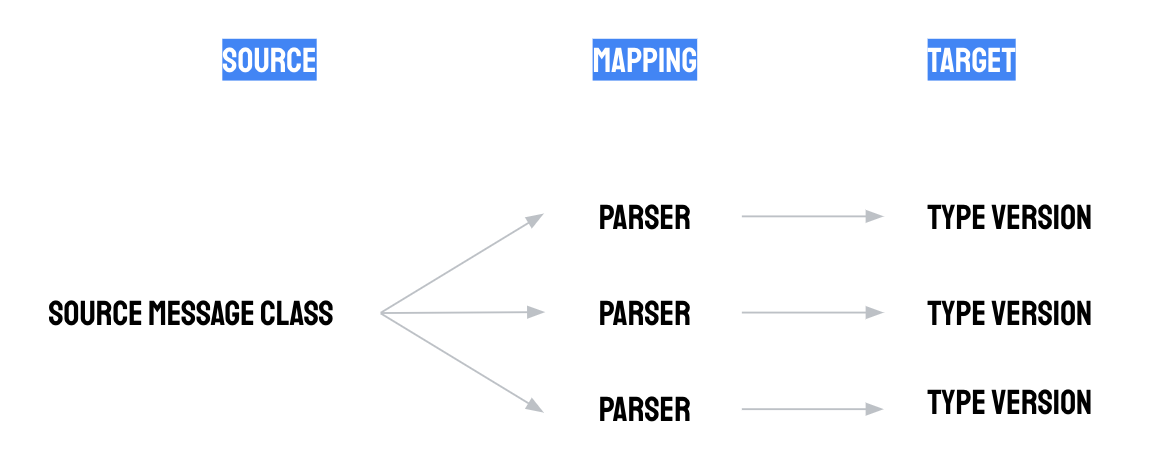
예를 들어 '머신 상태' 및 '진동 센서 판독값' 유형을 만들 수 있습니다. 첫 번째 유형은 '실행 중', '유휴', '예약된 유지보수', '예약되지 않은 유지보수'와 같은 머신 상태 변경 이벤트를 모델링하는 데 사용할 수 있고, 두 번째 유형은 숫자 진동 센서 판독값 스트림을 모델링하는 데 사용할 수 있습니다.
MDE는 기본 유형 집합과 함께 제공되지만 새 유형을 만들 수 있습니다. 유형은 다음 특성으로 정의됩니다.
- 이름: 유형의 이름입니다.
- 원형: 유형이 기반하는 원형의 이름입니다. MDE의 유형은 항상 정확히 하나의 원형과 연결됩니다.
- 스토리지 사양: 데이터 싱크별 설정 목록입니다. 스토리지 사양을 사용하면 레코드를 데이터 싱크에 쓸지 여부를 구성하고 싱크별 설정을 추가로 제공할 수 있습니다.
- 선택적 구성 매개변수(다음 포함):
- data 필드의 JSON 스키마 (이산 및 연속 원형 유형에만 적용됨)
- 메타데이터 버킷 연결: 이 유형의 레코드가 인스턴스 참조를 제공해야 하는 메타데이터 버킷 목록입니다.
유형 및 데이터 싱크
특정 유형의 레코드 스트림은 유형에 대해 사용 설정된 데이터 싱크에 의해 처리됩니다. 데이터 싱크는 유형에 대해 활성화 (사용 설정 또는 사용 중지)할 수 있습니다. 예를 들어 특정 유형의 레코드는 BigQuery에 작성되도록 구성할 수 있지만 Cloud Storage에는 작성되지 않도록 구성할 수 있습니다.
지원되는 데이터 싱크
MDE는 다음 데이터 싱크를 지원합니다.
- BigQuery
- Bigtable/Federation API
- Cloud Storage
- Pub/Sub (JSON 및 Protobuf)
BigQuery 데이터 싱크
새 유형이 생성되면 MDE는 mde_data 데이터 세트의 BigQuery에 해당 유형 테이블을 자동으로 생성합니다.
각 유형의 레코드는 해당 유형 테이블에 기록됩니다.
Cloud Storage 데이터 싱크
레코드는 10분 창과 창당 10개 파티션을 사용하여 Hive 파티셔닝을 사용하는 AVRO 파일의 <project_id>-gcs-ingestion라는 Cloud Storage 버킷에 저장됩니다. 레코드는 유형별로 폴더에 그룹화됩니다.
Pub/Sub 데이터 싱크
Pub/Sub 싱크는 전용 주제에 레코드를 게시합니다. Pub/Sub 메시지 스키마는 Pub/Sub 싱크 메시지 스키마에 설명되어 있습니다.
메타데이터 구체화
유형의 각 데이터 싱크는 레코드에 메타데이터를 구체화하도록 구성할 수 있습니다. 이 설정을 사용 설정하면 메타데이터 인스턴스 참조가 메타데이터 인스턴스 객체로 확인되고 객체가 레코드에 포함됩니다. 메타데이터가 유지되거나 출력되는 정확한 방식은 데이터 싱크에 따라 다릅니다.
예를 들어 BigQuery에서 구체화된 메타데이터는 다음 스키마를 사용하여 materialized_metadata_field에 작성됩니다.
{
"$schema": "http://json-schema.org/draft-04/schema#",
"type": "object",
"additionalProperties": {
"type": "object",
"description": "Metadata instance"
}
}
원형
원형은 유형의 상위 클래스를 나타내며 각 원형은 레코드에 최적의 처리 및 스토리지 모델을 제공하도록 설계되었습니다. 원형은 파서에서 내보낸 특정 유형의 레코드에 있어야 하는 핵심 필수 필드를 정의합니다. MDE는 세 가지 원형 패밀리로 그룹화된 6개의 시스템 정의 표준 및 클러스터링된 원형 집합과 함께 제공됩니다.
- 숫자 데이터 계열 (NDS)
- 이산형 데이터 계열 (DDS)
- 연속 데이터 계열 (CDS)
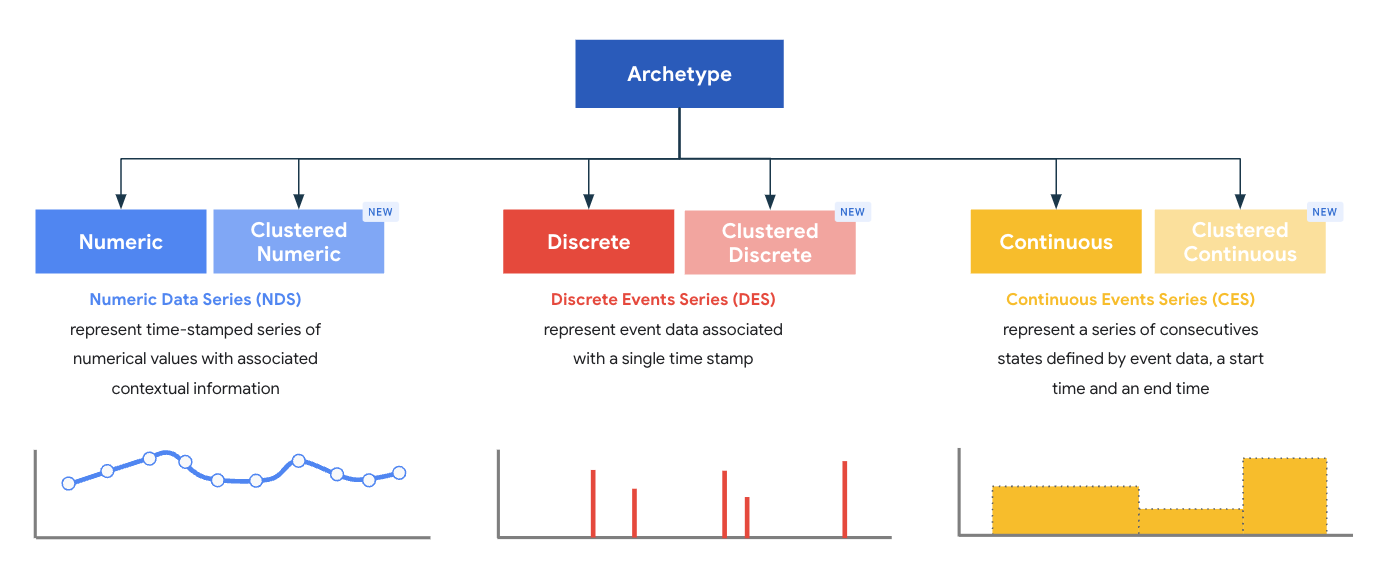
MDE의 유형은 항상 정확히 하나의 원형과 연결되며 유형의 원형은 생성 시간에 정의됩니다.
유형을 사용하면 원형에 의해 적용되는 제약조건 외에 파서에서 내보낸 프로토 레코드에 대한 추가 제약조건을 정의할 수 있습니다. 예를 들어 유형의 data 필드 모양을 지정하거나 유형의 레코드가 특정 메타데이터로 컨텍스트화되어야 한다고 정의할 수 있습니다.
요약하자면 proto 레코드 스키마는 다음의 조합입니다.
- 원형 스키마
- 스키마 입력
원형 계열
각 원형 계열에는 두 가지 유형의 원형이 포함됩니다.
- 표준
- 클러스터링됨
MDE v1.3에서는 표준 원형의 기능을 확장하는 클러스터링된 원형이라는 개념을 도입합니다. 클러스터링된 원형은 파서의 값으로 채울 수 있는 네 개의 일반 필드를 제공합니다. 각 데이터 싱크는 다음 네 가지 필드를 사용하여 추가 쿼리 및 데이터 액세스 기능을 제공합니다.
- BigQuery: BigQuery의 클러스터링된 유형 테이블은 순서대로 네 개의 일반 필드로 클러스터링됩니다. 이렇게 하면 클러스터링된 필드에서 BigQuery의 데이터를 효율적으로 필터링할 수 있습니다.
- Bigtable Federation API: Federation API는 클러스터링된 필드를 사용하여 Bigtable에서 행 키를 구성하여 새로운 데이터 액세스 패턴을 지원합니다.
- Pub/Sub: Pub/Sub 메시지는 필드를 Pub/Sub 메시지의 최상위 필드로 전달합니다.
숫자 원형 패밀리
숫자 원형 계열은 타임스탬프가 지정된 일련의 숫자 메시지를 모델링하는 유형의 기반으로 사용하도록 설계되었습니다. 예를 들어 온도 센서가 일련의 판독값을 내보내는 경우입니다.
원형의 표준 버전과 클러스터링된 버전은 다음 기본 레코드 스키마를 정의합니다.
표준
| 필드 | 데이터 유형 | 필수 |
|---|---|---|
tagName |
문자열 | 예 |
value |
숫자 | 예 |
eventTimestamp |
정수 (epoch ms로 형식이 지정됨) | 예 |
클러스터링됨
| 필드 | 데이터 유형 | 필수 |
|---|---|---|
tagName |
문자열 | 예 |
value |
숫자 | 예 |
eventTimestamp |
정수 (epoch ms로 형식이 지정됨) | 예 |
clustered_column_1 |
문자열 | 아니요 |
clustered_column_2 |
문자열 | 아니요 |
clustered_column_3 |
문자열 | 아니요 |
clustered_column_4 |
문자열 | 아니요 |
이산형 원형 패밀리
개별 원형 계열은 타임스탬프가 지정된 이벤트를 모델링하는 유형의 기반으로 사용하도록 설계되었습니다(예: 특정 머신이나 프로세스에서 작업자가 주도하는 매개변수 변경).
원형의 표준 버전과 클러스터링된 버전은 다음 기본 레코드 스키마를 정의합니다.
표준
| 필드 | 데이터 유형 | 필수 |
|---|---|---|
tagName |
문자열 | 예 |
data |
JSON 객체 | 예 |
eventTimestamp |
정수 (epoch ms로 형식이 지정됨) | 예 |
클러스터링됨
| 필드 | 데이터 유형 | 필수 |
|---|---|---|
tagName |
문자열 | 예 |
data |
JSON 객체 | 예 |
eventTimestamp |
정수 (epoch ms로 형식이 지정됨) | 예 |
clustered_column_1 |
문자열 | 아니요 |
clustered_column_2 |
문자열 | 아니요 |
clustered_column_3 |
문자열 | 아니요 |
clustered_column_4 |
문자열 | 아니요 |
연속 원형 패밀리
연속 원형 계열은 시작 및 종료 타임스탬프로 정의된 연속 상태 계열을 모델링하는 유형의 기반으로 사용하도록 설계되었습니다(예: 연속된 기간 동안의 머신 작동 상태).
원형의 표준 버전과 클러스터링된 버전은 다음 기본 레코드 스키마를 정의합니다.
표준
| 필드 | 데이터 유형 | 필수 |
|---|---|---|
tagName |
문자열 | 예 |
data |
JSON 객체 | 예 |
eventTimestampStart |
정수 (epoch ms로 형식이 지정됨) | 예 |
eventTimestampEnd |
정수 (epoch ms로 형식이 지정됨) | 예 |
클러스터링됨
| 필드 | 데이터 유형 | 필수 |
|---|---|---|
tagName |
문자열 | 예 |
data |
JSON 객체 | 예 |
eventTimestampStart |
정수 (epoch ms로 형식이 지정됨) | 예 |
eventTimestampEnd |
정수 (epoch ms로 형식이 지정됨) | 예 |
clustered_column_1 |
문자열 | 아니요 |
clustered_column_2 |
문자열 | 아니요 |
clustered_column_3 |
문자열 | 아니요 |
clustered_column_4 |
문자열 | 아니요 |
데이터 필드
이산 데이터 계열 및 연속 데이터 계열 원형은 data 필드의 JSON 스키마를 허용합니다. 필드의 JSON 스키마가 정의된 경우 파서에서 내보낸 레코드에 포함된 data 필드의 값이 런타임에 스키마에 대해 검증됩니다. 예를 들어 이산 시계열 유형에 대해 다음 스키마를 정의한다고 가정해 보겠습니다.
{
"$schema": "http://json-schema.org/draft-04/schema#",
"type": "object",
"properties": {
"eventName": {
"type": "string"
}
},
"required": ["eventName"]
}
이산 시계열 유형의 이전 스키마를 사용하면 파서에서 내보낸 해당 유형의 다음 (부분) 레코드가 유효하지 않습니다.
{
"data": {
"complex": {
"machineName": "example"
}
}
}
데이터 검증에 실패하면 레코드가 데드 레터 큐로 이동합니다. 데드 레터 큐의 레코드는 나중에 수동으로 처리할 수 있습니다.
메타데이터 버킷
유형은 메타데이터 버킷을 참조할 수 있습니다. 타입의 메타데이터 버킷 참조는 레코드가 메타데이터 버킷 인스턴스에 대한 참조를 제공할 수 있는지 또는 제공해야 하는지 (required 속성 값에 따라 다름) 정의합니다.
유형의 메타데이터 버킷 참조는 해당 유형의 레코드에 대한 메타데이터 계약을 정의합니다. 예를 들어 유형의 모든 레코드는 기기 메타데이터로 컨텍스트화되어야 한다고 정의할 수 있습니다 (device라는 메타데이터 버킷에서 메타데이터 인스턴스에 대한 참조 제공).
메타데이터 버킷이 유형과 연결되어 있고 required 플래그가 true로 설정된 경우 메타데이터 버킷 인스턴스에 대한 참조를 제공하지 않는 파서에서 내보낸 해당 유형의 레코드는 데드 레터 대기열로 이동됩니다. 자세한 내용은 메시지를 다시 처리하는 방법을 참고하세요.
유형 버전 관리
버전 관리 유형은 여러 가지가 있으며 다음 섹션에서 각 유형을 설명합니다.
새 유형 버전 생성
특정 유형의 새 버전을 만들 수 있습니다. 각 새 버전은 추가 메타데이터 버킷 연결을 지정하거나 데이터 필드의 스키마를 수정할 수 있습니다. 하지만 유형의 전체 수명 동안 데이터 일관성을 유지하려면 새 유형 버전은 앞으로만 발전할 수 있으며 버전 관리 규칙을 준수해야 합니다. 새 버전의 유형은 다음을 변경할 수 있습니다.
5월:
- 데이터 스키마에 새 선택적 필드를 추가합니다.
- 데이터 스키마에서 필수 필드를 선택사항으로 표시합니다.
- 새 메타데이터 버킷 참조 추가
금지사항:
- 데이터 스키마에서 필드를 삭제합니다.
- 데이터 스키마에서 기존 필드의 데이터 유형을 변경합니다.
- 데이터 스키마에서 선택적 속성을 필수 속성으로 표시합니다.
- 메타데이터 버킷 참조를 삭제합니다.
기존 유형 버전 수정
새 유형 버전을 만들지 않고도 기존 유형 버전에서 스토리지 사양과 변환을 업데이트할 수 있습니다.
유형 수정
유형에 대한 대부분의 작업에는 새 유형 버전을 만들거나 기존 유형 버전을 수정해야 합니다. 버전에 관계없이 유형에 대해 실행할 수 있는 유일한 작업은 사용 설정 또는 사용 중지입니다. 유형이 사용 중지되면 해당 유형의 모든 버전에서 데이터 수집이 중지됩니다.
유형 이름 지정 제한사항
유형 이름에는 다음이 포함될 수 있습니다.
- 문자 (대문자 및 소문자), 숫자, 특수문자
-및_ - 최대 255자(영문 기준)까지 가능합니다.
검증에 다음 정규 표현식을 사용할 수 있습니다. ^[a-z][a-z0-9\\-_]{1,255}$
이름 지정 제한을 위반하는 항목을 만들려고 하면 400 error 오류가 발생합니다.