
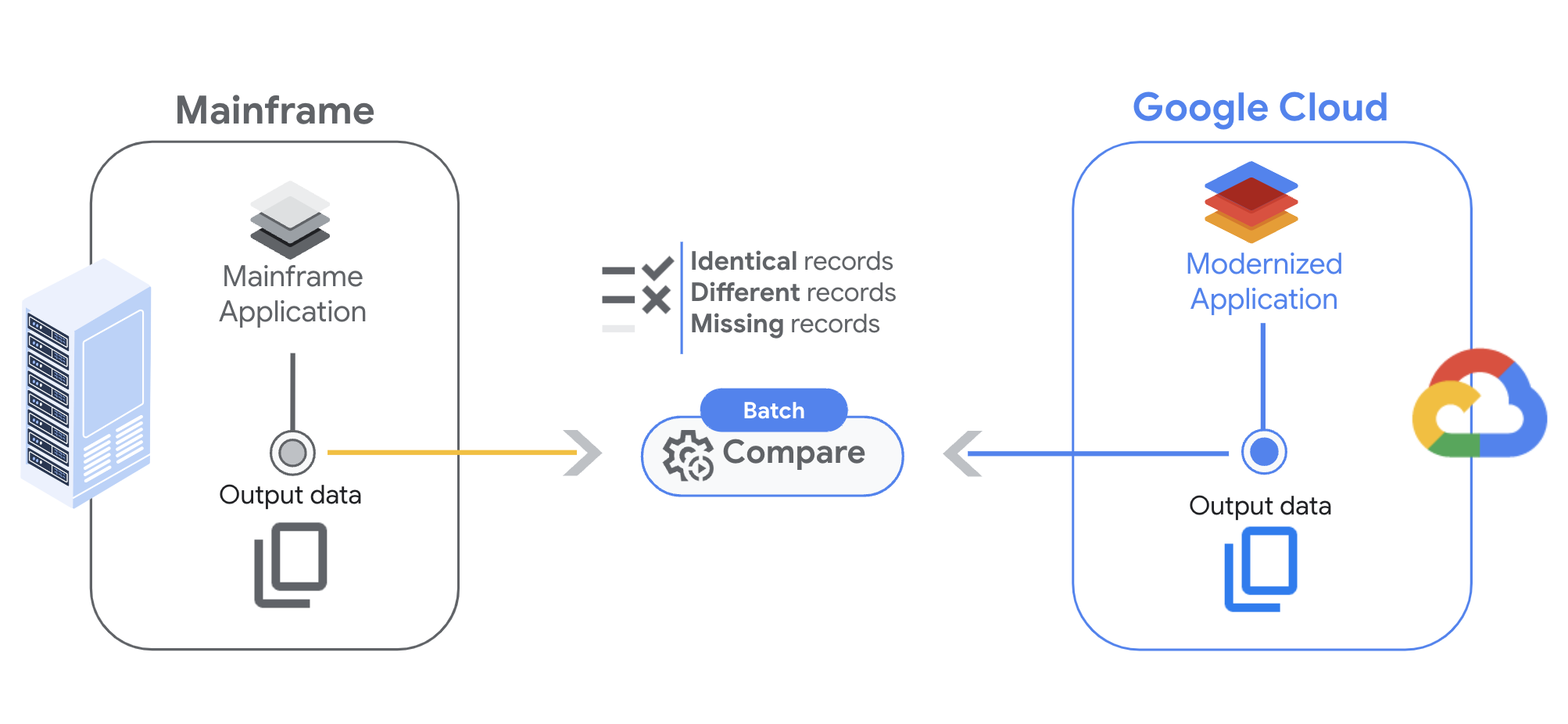
En esta página, se describe la comparación de archivos de ejecución doble, que está diseñada para ayudarte a comparar los resultados de las cargas de trabajo por lotes. Con esta función, puedes asegurarte de que los trabajos por lotes que se ejecutan en el mainframe y en Google Cloud generen resultados idénticos para las mismas entradas.
Cómo funcionan las comparaciones de archivos
La función de comparación de archivos de Dual Run te permite analizar archivos. Para ello, primero debes configurar los parámetros de comparación, luego configurar los activadores para iniciar el proceso y, por último, revisar los resultados.
En las siguientes secciones, obtén más información sobre cómo funciona la comparación de archivos.
Transferencia de archivos desde la unidad central
Antes de ejecutar una comparación de archivos, el primer paso es transferir archivos desde el mainframe a un bucket de Cloud Storage en Google Cloud.
Puedes transferir archivos desde la computadora central de dos maneras:
- con transferencias por FTP/HTTPS
- con Mainframe Connector.
En ambos casos, Dual Run puede leer formatos EBCDIC y admite la salida de UNLOAD sin necesidad de ninguna transformación adicional.
Configuración de comparación
Dual Run te brinda flexibilidad total para comparar tus archivos modernizados y de mainframe. Para cada archivo, debes especificar qué campos se compararán y sus formatos esperados.
La comparación de archivos de ejecución doble admite opciones avanzadas configurables, como ofuscación de datos, configuración de tolerancia, combinación de campos, etiquetas personalizadas y filtrado para un análisis de archivos preciso y flexible.
- Ofusca campos específicos cuando realices la comparación de archivos. Esto es útil para ocultar datos sensibles que no deberían aparecer en los informes ni en los paneles como contenido claramente visible.
- Permite la tolerancia al comparar valores numéricos de campos específicos. Esto es útil cuando se comparan números de punto flotante que provienen de diferentes sistemas.
- Permite la tolerancia al comparar valores de marcas de tiempo de campos específicos. Esto es útil cuando se comparan marcas de tiempo que provienen de diferentes sistemas.
- Combina varios campos con una cadena de unión opcional y trátalos como un solo campo durante la comparación.
- Configura etiquetas personalizadas para categorizar tus trabajos de comparación. Las etiquetas son pares clave-valor que puedes usar para etiquetar tus trabajos de comparación y diferenciarlos entre diferentes objetivos funcionales o comerciales.
- Ignorar los espacios en blanco iniciales y finales en campos específicos
- Ignora las mayúsculas y minúsculas en las cadenas.
- Aplicar filtros para ignorar registros durante la comparación, lo que permite aplicar varios filtros al mismo tiempo
Generación de configuración automatizada
Dual Run te proporciona herramientas automatizadas para ayudarte a configurar la comparación de archivos. Estas herramientas crean los archivos de configuración necesarios según tus copybooks de mainframe o según los archivos de muestra en formato JSON y CSV que proporciones.
Resultados de la comparación
Cuando comparas dos archivos, Dual Run devuelve tres resultados posibles:
- Coincidencia completa: El registro está presente en ambos archivos y el contenido de los campos coincide dentro de las restricciones especificadas.
- Coincidencia parcial: El registro está presente en ambos archivos, pero algunos de los campos no coinciden. Puedes verificar las diferencias en los resultados.
- Falta el registro: El registro solo está presente en los archivos reales o esperados.
En caso de que no coincidan los archivos comparados, puedes configurar la ejecución doble para que muestre todos los registros comparados dentro de los archivos, y no solo los registros que no coinciden, para facilitar la solución de problemas.
La ejecución doble ofrece una función llamada comparaciones diferidas para abordar situaciones en las que los datos podrían faltar temporalmente. Esto es particularmente útil para las comparaciones iterativas, como las que se realizan en las instantáneas diarias de la base de datos. Si un campo no está presente en una iteración, pero aparece en la siguiente, Dual Run lo almacena y compara más adelante, lo que garantiza que no se creen discrepancias en los datos. Esto proporciona un proceso de comparación más sólido y preciso, en especial para los conjuntos de datos dinámicos.
Archivos admitidos
Dual Run admite los siguientes archivos para la comparación:
- Archivos secuenciales de bloque fijo de z/OS
- Archivos de array JSON
- Archivos de líneas JSON (JSONL)
- Archivos CSV
Tipos de datos de z/OS admitidos
Dual Run admite los siguientes tipos de datos de z/OS, tanto en EBCDIC como en ASCII:
- COMP1
- COMP2
- PACKED_DECIMAL
- COMP4
- COMP5
- ZONED_DECIMAL
- ALPHANUMERIC
Archivos JSON admitidos
Dual Run admite los siguientes formatos JSON:
- JSONL: En este archivo, cada línea contiene un solo objeto JSON. No hay saltos de línea dentro del objeto.
- Array JSON: En este archivo, se admiten dos tipos de archivos:
- Es un array JSON en el que todo el array y los elementos se encuentran en una sola línea. No hay saltos de línea en este archivo.
- Es un array JSON con un salto de línea que separa los elementos del array. Cada objeto JSON también puede contener saltos de línea.
Archivos CSV admitidos
La ejecución doble admite archivos CSV que cumplen con el estándar RFC 4180. Puedes configurar cómo Dual Run analiza el archivo, incluidos los delimitadores, los encabezados, los caracteres de escape y las líneas múltiples.
¿Qué sigue?
Obtén más información para instalar y comenzar a usar Dual Run.