
Halaman ini menjelaskan Perbandingan File Dual Run, yang dirancang untuk membantu Anda membandingkan output workload batch. Dengan fitur ini, Anda dapat memastikan bahwa tugas batch yang berjalan di mainframe dan di Google Cloud menghasilkan output yang identik untuk input yang sama.
Cara kerja perbandingan file
Fitur perbandingan file Dual Run memungkinkan Anda menganalisis file dengan terlebih dahulu mengonfigurasi setelan perbandingan, lalu menyiapkan pemicu untuk memulai proses, dan terakhir meninjau hasilnya.
Pelajari cara kerja perbandingan file di bagian berikut.
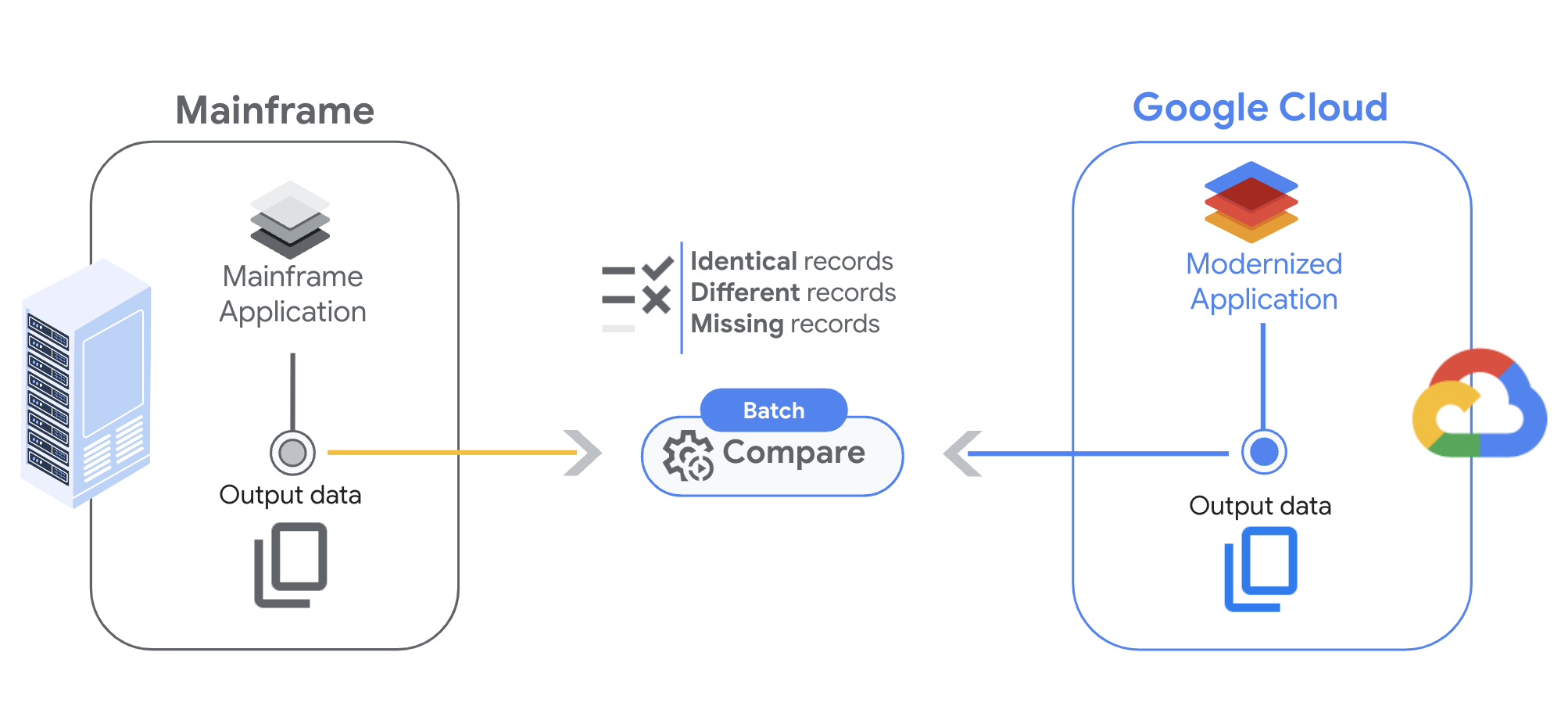
Transfer file dari mainframe
Sebelum Anda dapat menjalankan perbandingan file, langkah pertama adalah mentransfer file dari mainframe ke bucket Cloud Storage di Google Cloud.
Anda dapat mentransfer file dari mainframe dengan dua cara:
- dengan transfer FTP/HTTPS
- dengan Mainframe Connector.
Dalam kedua kasus tersebut, Dual Run dapat membaca format EBCDIC, dan mendukung output UNLOAD tanpa memerlukan transformasi tambahan.
Konfigurasi perbandingan
Dual Run memberi Anda fleksibilitas penuh tentang cara membandingkan file mainframe dan file yang dimodernisasi. Untuk setiap file, Anda menentukan kolom yang akan dibandingkan dan format yang diharapkan.
Perbandingan file Dual Run mendukung opsi yang dapat dikonfigurasi lanjutan, seperti pengaburan data, setelan toleransi, penggabungan kolom, label kustom, dan pemfilteran untuk analisis file yang presisi dan fleksibel.
- Samarkan kolom tertentu saat Anda melakukan perbandingan file. Hal ini berguna untuk menyembunyikan data sensitif yang tidak boleh muncul dalam laporan atau di dasbor sebagai konten yang terlihat jelas.
- Izinkan toleransi saat membandingkan nilai numerik dari kolom tertentu. Hal ini berguna saat membandingkan bilangan floating point yang berasal dari sistem yang berbeda.
- Izinkan toleransi saat membandingkan nilai stempel waktu kolom tertentu. Hal ini berguna saat membandingkan stempel waktu yang berasal dari sistem yang berbeda.
- Gabungkan beberapa kolom dengan string penggabungan opsional, dan perlakukan sebagai satu kolom selama perbandingan.
- Konfigurasi label kustom untuk mengategorikan tugas perbandingan Anda. Label adalah pasangan nilai kunci yang dapat Anda gunakan untuk memberi tag pada tugas perbandingan, dan untuk membedakannya antara berbagai tujuan fungsional atau bisnis.
- Abaikan spasi kosong di awal dan akhir di kolom tertentu.
- Mengabaikan kapitalisasi dalam string.
- Terapkan filter untuk mengabaikan data selama perbandingan, sehingga beberapa filter dapat diterapkan secara bersamaan.
Pembuatan konfigurasi otomatis
Dual Run menyediakan alat otomatis untuk membantu mengonfigurasi Perbandingan File. Alat ini membuat file konfigurasi yang diperlukan berdasarkan copybook mainframe Anda, atau berdasarkan file JSON dan CSV contoh yang Anda berikan.
Hasil perbandingan
Saat membandingkan dua file, Dual Run menampilkan tiga kemungkinan hasil:
- Kecocokan penuh: data ada di kedua file, dan konten kolom cocok dalam batasan yang Anda tentukan.
- Kecocokan sebagian: data ada di kedua file, tetapi beberapa kolom tidak cocok. Anda dapat memeriksa perbedaan dalam output hasil.
- Data tidak ada: data hanya ada dalam file aktual atau yang diharapkan.
Jika terjadi ketidakcocokan antara file yang dibandingkan, Anda dapat mengonfigurasi Dual Run untuk menampilkan semua data yang dibandingkan dalam file, dan bukan hanya data yang tidak cocok, agar pemecahan masalah lebih mudah.
Dual Run menawarkan fitur yang disebut perbandingan yang ditangguhkan untuk mengatasi situasi saat data mungkin tidak ada untuk sementara. Hal ini sangat berguna untuk perbandingan iteratif, seperti yang dilakukan pada snapshot database harian. Jika kolom tidak ada dalam satu iterasi, tetapi muncul di iterasi berikutnya, Dual Run akan menyimpan dan membandingkannya nanti, sehingga tidak ada perbedaan data yang dibuat. Hal ini memberikan proses perbandingan yang lebih andal dan akurat, terutama untuk set data dinamis.
File yang didukung
Jalankan Ganda mendukung file berikut untuk perbandingan:
- File berurutan blok tetap z/OS
- File array JSON
- File JSON Lines (JSONL)
- File CSV
Jenis data z/OS yang didukung
Dual Run mendukung jenis data z/OS berikut, baik dalam EBCDIC maupun ASCII:
- COMP1
- COMP2
- PACKED_DECIMAL
- COMP4
- COMP5
- ZONED_DECIMAL
- ALPHANUMERIC
File JSON yang didukung
Dual Run mendukung format JSON berikut:
- JSONL: dalam file ini, setiap baris berisi satu objek JSON. Tidak ada baris baru dalam objek.
- Array JSON: dalam file ini, dua jenis file didukung:
- Array JSON dengan seluruh array dan elemen dalam satu baris. Tidak ada baris baru dalam file ini.
- Array JSON dengan baris baru yang memisahkan elemen dalam array. Setiap objek JSON juga dapat berisi baris baru.
File CSV yang didukung
Dual Run mendukung file CSV yang mengikuti standar RFC 4180. Anda dapat mengonfigurasi cara Dual Run mem-parsing file, termasuk pemisah, header, karakter escape, dan multiline.
Langkah berikutnya
Pelajari cara menginstal dan mulai menggunakan Dual Run.