
本页介绍了双重运行批次比较,该功能旨在帮助您比较批次工作负载的输出。借助此功能,您可以确保在大型主机和 Google Cloud 上运行的批处理作业针对相同的给定输入生成相同的输出。
批量比较的运作方式
借助 Dual Run 的批次比较功能,您可以先配置比较设置,然后设置触发器以启动该流程,最后查看结果,从而分析文件。
请参阅以下部分,了解批次比较的运作方式。
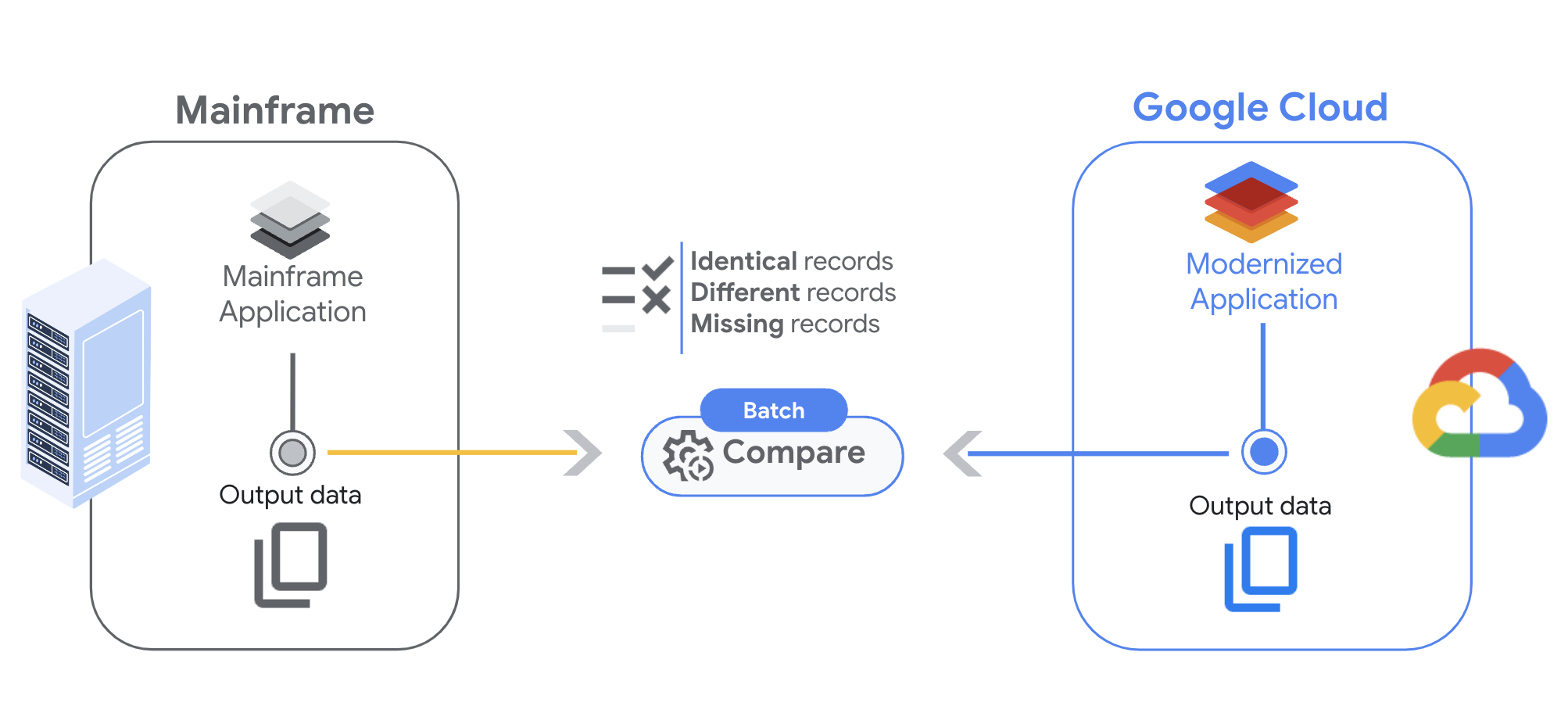
从大型主机进行文件传输
在运行文件比较之前,第一步是将文件从大型机转移到 Google Cloud中的 Cloud Storage 存储桶。
您可以通过两种方式从大型机传输文件:
- 通过 FTP/HTTPS 转移
- 使用 Mainframe Connector。
在这两种情况下,Dual Run 都可以读取 EBCDIC 格式,并支持 UNLOAD 输出,而无需进行任何额外的转换。
比较配置
借助 Dual Run,您可以灵活地比较大型主机文件和现代化改造后的文件。对于每个文件,您需要指定要比较的字段及其预期格式。
双重运行文件比较支持高级可配置选项,例如数据模糊处理、容差设置、字段合并、自定义标签和过滤,以便进行精确而灵活的文件分析。
- 在执行文件比较时,混淆特定字段。这有助于隐藏不应在报告或信息中心内以清晰可见的内容形式显示的敏感数据。
- 允许在比较特定字段的数值时存在容差。在比较来自不同系统的浮点数时,此属性非常有用。
- 在比较特定字段的时间戳值时允许容差。在比较来自不同系统的时间戳时,此字段非常有用。
- 将多个字段与可选的联接字符串合并在一起,并在比较期间将它们视为单个字段。
- 配置自定义标签以对比较作业进行分类。标签是键值对,可用于标记比较作业,并区分不同的功能或业务目标。
- 忽略特定字段中的前导和尾随空格。
- 忽略字符串中的字母大小写。
- 应用过滤条件以在比较期间忽略记录,从而允许同时应用多个过滤条件。
自动生成配置
Dual Run 提供自动化工具来帮助您配置文件比较。这些工具会根据您的主机簿或您提供的 JSON 和 CSV 示例文件创建所需的配置文件。
比较结果
比较两个文件时,双重运行会返回以下三种可能的结果:
- 完全匹配:记录同时存在于两个文件中,并且字段内容在您指定的限制范围内匹配。
- 部分匹配:记录同时存在于两个文件中,但部分字段不匹配。您可以查看结果输出中的差异。
- 缺少记录:记录仅存在于实际文件或预期文件中。
如果比较的文件之间存在不匹配的情况,您可以将双重运行配置为显示文件中的所有比较记录,而不仅仅是不匹配的记录,以便更轻松地进行问题排查。
为了应对数据可能暂时缺失的情况,Dual Run 提供了一项名为“延迟比较”的功能。这对于迭代比较(例如对每日数据库快照执行的比较)特别有用。如果某个字段在一次迭代中不存在,但在下一次迭代中出现,双重运行会存储并比较该字段,确保不会出现数据差异。这可以提供更可靠、更准确的比较流程,尤其适用于动态数据集。
支持的文件
双重跑步支持以下文件进行比较:
- z/OS 固定块顺序文件
- JSON 数组文件
- JSON Lines (JSONL) 文件
- CSV 文件
支持的 z/OS 数据类型
双重运行支持以下 z/OS 数据类型(以 EBCDIC 和 ASCII 格式):
- COMP1
- COMP2
- PACKED_DECIMAL
- COMP4
- COMP5
- ZONED_DECIMAL
- ALPHANUMERIC
支持的 JSON 文件
Dual Run 支持以下 JSON 格式:
- JSONL:在此文件中,每行包含一个 JSON 对象。对象内没有换行符。
- JSON 数组:此文件支持两种类型的文件:
- 一个 JSON 数组,其中整个数组和元素都位于一行中。此文件中没有任何换行符。
- 一个 JSON 数组,其中的元素以换行符分隔。每个 JSON 对象也可以包含换行符。
支持的 CSV 文件
双重运行支持符合 RFC 4180 标准的 CSV 文件。您可以配置 Dual Run 解析文件的方式,包括分隔符、标题、转义字符和多行。
后续步骤
了解在线比较。