
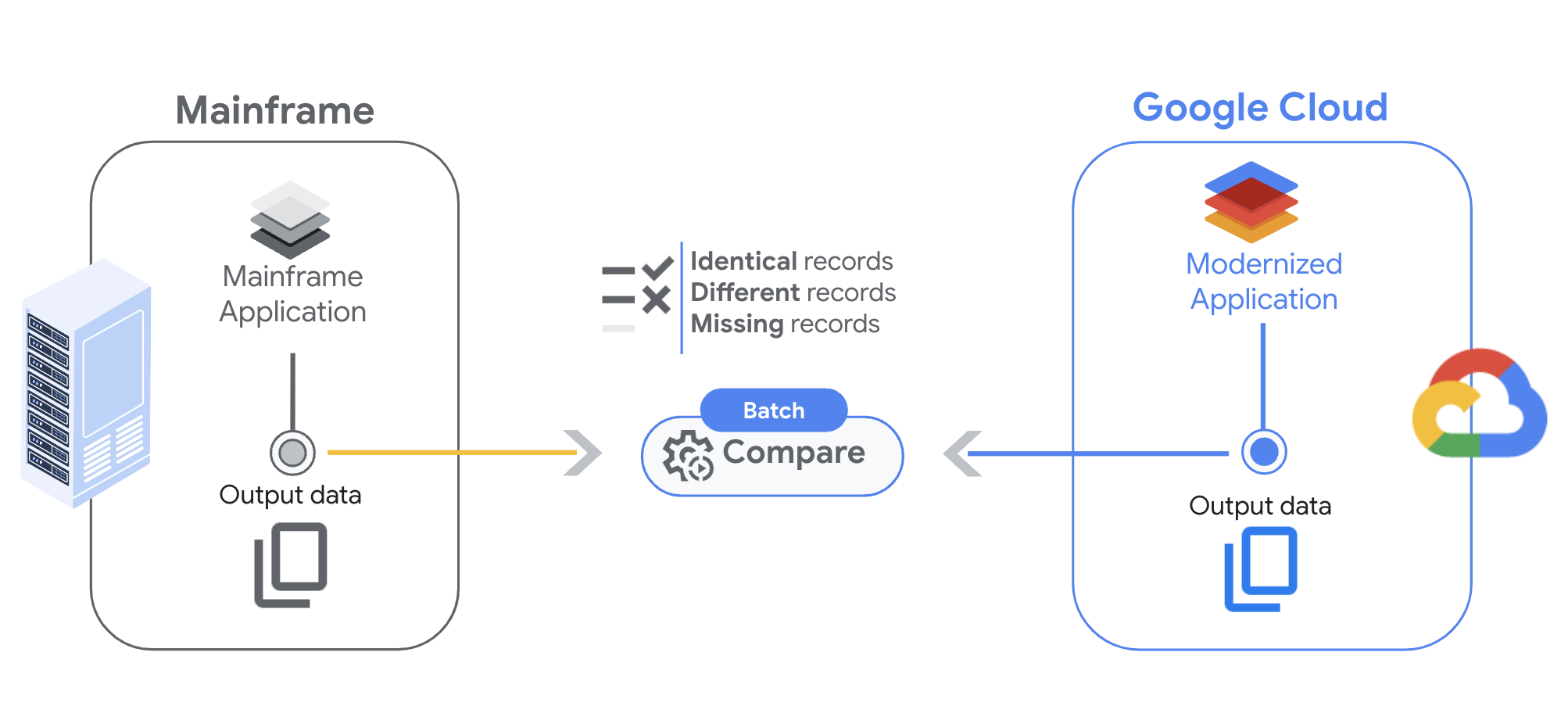
Auf dieser Seite wird der Dual Run Batch Comparison beschrieben, mit dem Sie die Ausgaben von Batch-Arbeitslasten vergleichen können. Mit dieser Funktion können Sie dafür sorgen, dass die Batchjobs, die auf dem Mainframe und auf Google Cloud ausgeführt werden, für dieselben Eingaben identische Ausgaben generieren.
Funktionsweise von Batchvergleichen
Mit der Batchvergleichsfunktion von Dual Run können Sie Dateien analysieren, indem Sie zuerst die Vergleichseinstellungen konfigurieren, dann die Trigger zum Starten des Prozesses einrichten und schließlich die Ergebnisse überprüfen.
In den folgenden Abschnitten erfahren Sie, wie der Batchvergleich funktioniert.
Dateiübertragung vom Mainframe
Bevor Sie einen Dateivergleich durchführen können, müssen Sie zuerst Dateien vom Mainframe in einen Cloud Storage-Bucket in Google Cloudübertragen.
Sie haben zwei Möglichkeiten, Dateien vom Mainframe zu übertragen:
- mit FTP-/HTTPS-Übertragungen
- mit dem Mainframe Connector.
In beiden Fällen kann Dual Run EBCDIC-Formate lesen und unterstützt die UNLOAD-Ausgabe ohne zusätzliche Transformation.
Vergleichskonfiguration
Mit Dual Run haben Sie die volle Flexibilität, wie Sie Ihre Mainframe- und modernisierten Dateien vergleichen. Für jede Datei geben Sie an, welche Felder verglichen werden sollen und welche Formate erwartet werden.
Der Dual Run-Dateivergleich unterstützt erweiterte konfigurierbare Optionen wie Datenverschleierung, Toleranzeinstellungen, Zusammenführen von Feldern, benutzerdefinierte Labels und Filter für eine präzise und flexible Dateianalyse.
- Bestimmte Felder beim Dateivergleich verschleiern Das ist nützlich, um vertrauliche Daten auszublenden, die nicht als deutlich sichtbare Inhalte in Berichten oder Dashboards erscheinen sollen.
- Toleranz beim Vergleichen numerischer Werte bestimmter Felder zulassen. Das ist nützlich, wenn Sie Gleitkommazahlen aus verschiedenen Systemen vergleichen möchten.
- Toleranz beim Vergleichen von Zeitstempelwerten für bestimmte Felder zulassen. Das ist nützlich, wenn Sie Zeitstempel aus verschiedenen Systemen vergleichen möchten.
- Mehrere Felder mit einem optionalen Verbindungsstring zusammenführen und sie beim Vergleich als ein einzelnes Feld behandeln.
- Benutzerdefinierte Labels zum Kategorisieren Ihrer Vergleichsjobs konfigurieren Labels sind Schlüssel/Wert-Paare, mit denen Sie Ihre Vergleichsjobs taggen und nach verschiedenen funktionalen oder geschäftlichen Zielsetzungen unterscheiden können.
- Vor- und nachgestellte Leerzeichen in bestimmten Feldern ignorieren
- Groß-/Kleinschreibung in Strings ignorieren
- Filter anwenden, um Datensätze beim Vergleich zu ignorieren. Es können mehrere Filter gleichzeitig angewendet werden.
Automatisierte Konfigurationsgenerierung
Dual Run bietet automatisierte Tools, mit denen Sie den Dateivergleich konfigurieren können. Mit diesen Tools werden die erforderlichen Konfigurationsdateien auf Grundlage Ihrer Mainframe-Copybooks oder auf Grundlage von JSON- und CSV-Beispieldateien erstellt, die Sie bereitstellen.
Vergleichsergebnisse
Beim Vergleich von zwei Dateien gibt Dual Run drei mögliche Ergebnisse zurück:
- Vollständige Übereinstimmung:Der Datensatz ist in beiden Dateien vorhanden und der Inhalt der Felder entspricht den von Ihnen angegebenen Einschränkungen.
- Teilweise Übereinstimmung:Der Datensatz ist in beiden Dateien vorhanden, aber einige der Felder stimmen nicht überein. Sie können sich die Unterschiede in der Ergebnisausgabe ansehen.
- Fehlender Datensatz:Der Datensatz ist nur in den tatsächlichen oder erwarteten Dateien vorhanden.
Bei einer Abweichung zwischen den verglichenen Dateien können Sie Dual Run so konfigurieren, dass alle verglichenen Datensätze in den Dateien und nicht nur die nicht übereinstimmenden Datensätze angezeigt werden, um die Fehlerbehebung zu erleichtern.
Bei Dual Run gibt es die Funktion Verzögerte Vergleiche, um Situationen zu berücksichtigen, in denen Daten vorübergehend fehlen. Das ist besonders nützlich für iterative Vergleiche, z. B. für tägliche Datenbank-Snapshots. Wenn ein Feld in einer Iteration fehlt, aber in der nächsten vorhanden ist, wird es im Dual Run gespeichert und später verglichen, um Datenabweichungen zu vermeiden. Das ermöglicht einen robusteren und genaueren Vergleich, insbesondere bei dynamischen Datasets.
Unterstützte Dateien
Dual Run unterstützt die folgenden Dateien für den Vergleich:
- Sequenzielle Dateien mit fester Blockgröße für z/OS
- JSON-Array-Dateien
- JSON Lines-Dateien (JSONL)
- CSV-Dateien
Unterstützte z/OS-Datentypen
Dual Run unterstützt die folgenden z/OS-Datentypen, sowohl in EBCDIC als auch in ASCII:
- COMP1
- COMP2
- PACKED_DECIMAL
- COMP4
- COMP5
- ZONED_DECIMAL
- ALPHANUMERIC
Unterstützte JSON-Dateien
Dual Run unterstützt die folgenden JSON-Formate:
- JSONL: In dieser Datei enthält jede Zeile ein einzelnes JSON-Objekt. Das Objekt enthält keine Zeilenumbrüche.
- JSON-Array: In dieser Datei werden zwei Dateitypen unterstützt:
- Ein JSON-Array, in dem das gesamte Array und die Elemente in einer einzigen Zeile stehen. Diese Datei enthält keine Zeilenumbrüche.
- Ein JSON-Array, in dem die Elemente durch einen Zeilenumbruch getrennt sind. Jedes JSON-Objekt kann auch Zeilenumbrüche enthalten.
Unterstützte CSV-Dateien
Dual Run unterstützt CSV-Dateien, die dem Standard RFC 4180 entsprechen. Sie können konfigurieren, wie Dual Run die Datei parst, einschließlich Trennzeichen, Kopfzeilen, Escapezeichen und mehrzeiliger Daten.
Nächste Schritte
Weitere Informationen zum Onlinevergleich