
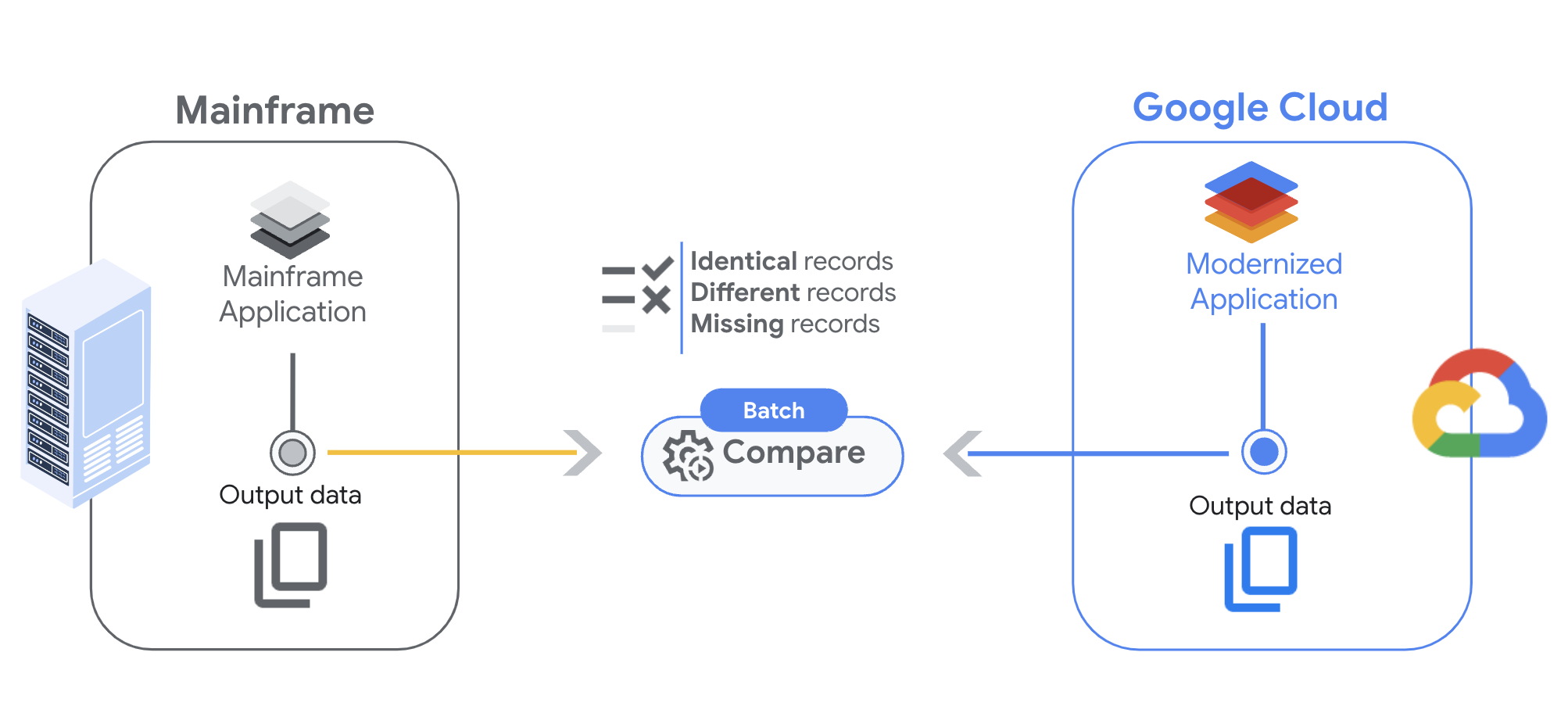
Cette page décrit la comparaison par lot Dual Run, conçue pour vous aider à comparer les sorties des charges de travail par lot. Grâce à cette fonctionnalité, vous pouvez vous assurer que les tâches par lot exécutées sur le mainframe et sur Google Cloud génèrent des sorties identiques pour les mêmes entrées.
Fonctionnement des comparaisons par lot
La fonctionnalité de comparaison par lot de Dual Run vous permet d'analyser des fichiers en configurant d'abord les paramètres de comparaison, puis en configurant les déclencheurs pour démarrer le processus et, enfin, en examinant les résultats.
Découvrez le fonctionnement d'une comparaison par lot dans les sections suivantes.
Transfert de fichiers depuis le mainframe
Avant de pouvoir exécuter une comparaison de fichiers, vous devez d'abord transférer des fichiers du mainframe vers un bucket Cloud Storage dans Google Cloud.
Vous pouvez transférer des fichiers depuis le mainframe de deux manières :
- avec des transferts FTP/HTTPS
- avec le Mainframe Connector.
Dans les deux cas, Dual Run peut lire les formats EBCDIC et est compatible avec la sortie UNLOAD sans nécessiter de transformation supplémentaire.
Configuration de la comparaison
Dual Run vous offre une flexibilité totale pour comparer vos fichiers mainframe et modernisés. Pour chaque fichier, vous spécifiez les champs à comparer et leurs formats attendus.
La comparaison de fichiers Dual Run est compatible avec des options configurables avancées, telles que l'obfuscation des données, les paramètres de tolérance, la fusion de champs, les libellés personnalisés et le filtrage pour une analyse de fichiers précise et flexible.
- Obfusquez des champs spécifiques lorsque vous effectuez la comparaison de fichiers. Cela est utile pour masquer les données sensibles qui ne doivent pas apparaître dans les rapports ni dans les tableaux de bord en tant que contenu clairement visible.
- Autorisez une tolérance lors de la comparaison des valeurs numériques de champs spécifiques. Cela est utile lorsque vous comparez des nombres à virgule flottante provenant de différents systèmes.
- Autorisez une tolérance lors de la comparaison des valeurs d'horodatage de champs spécifiques. Cela est utile lorsque vous comparez des horodatages provenant de différents systèmes.
- Fusionnez plusieurs champs avec une chaîne de jointure facultative et traitez-les comme un seul champ lors de la comparaison.
- Configurez des libellés personnalisés pour catégoriser vos tâches de comparaison. Les libellés sont des paires clé-valeur que vous pouvez utiliser pour baliser vos tâches de comparaison et les différencier en fonction de différents objectifs fonctionnels ou commerciaux.
- Ignorez les espaces blancs de début et de fin dans des champs spécifiques.
- Ignorez la casse dans les chaînes.
- Appliquez des filtres pour ignorer les enregistrements lors de la comparaison, ce qui permet d' appliquer plusieurs filtres en même temps.
Génération automatisée de la configuration
Dual Run vous fournit des outils automatisés pour vous aider à configurer la comparaison de fichiers. Ces outils créent les fichiers de configuration requis en fonction de vos copybooks mainframe ou d'exemples de fichiers JSON et CSV que vous fournissez.
Résultats de la comparaison
Lorsque vous comparez deux fichiers, Dual Run renvoie trois résultats possibles :
- Correspondance complète : l'enregistrement est présent dans les deux fichiers et le contenu des champs correspond aux contraintes spécifiées.
- Correspondance partielle : l'enregistrement est présent dans les deux fichiers, mais certains champs ne correspondent pas. Vous pouvez vérifier les différences dans la sortie des résultats.
- Enregistrement manquant : l'enregistrement n'est présent que dans les fichiers réels ou attendus.
En cas de non-concordance entre les fichiers comparés, vous pouvez configurer Dual Run pour afficher tous les enregistrements comparés dans les fichiers, et pas seulement les enregistrements non concordants, afin de faciliter le dépannage.
Dual Run propose une fonctionnalité appelée comparaisons différées pour résoudre les situations dans lesquelles des données peuvent être temporairement manquantes. Cela est particulièrement utile pour les comparaisons itératives, comme celles effectuées sur des instantanés de base de données quotidiens. Si un champ est absent dans une itération, mais apparaît dans la suivante, Dual Run le stocke et le compare ultérieurement, ce qui garantit qu'aucune différence de données n'est créée. Cela permet un processus de comparaison plus robuste et précis, en particulier pour les ensembles de données dynamiques.
Fichiers compatibles
Dual Run est compatible avec les fichiers suivants pour la comparaison :
- Fichiers séquentiels à blocs fixes z/OS
- Fichiers de tableaux JSON
- Fichiers JSON Lines (JSONL)
- Fichiers CSV
Types de données z/OS compatibles
Dual Run est compatible avec les types de données z/OS suivants, en EBCDIC et en ASCII :
- COMP1
- COMP2
- PACKED_DECIMAL
- COMP4
- COMP5
- ZONED_DECIMAL
- ALPHANUMERIC
Fichiers JSON compatibles
Dual Run est compatible avec les formats JSON suivants :
- JSONL : dans ce fichier, chaque ligne contient un seul objet JSON. Aucun saut de ligne n'est présent dans l'objet.
- Tableau JSON : deux types de fichiers sont compatibles :
- Un tableau JSON où l'ensemble du tableau et des éléments se trouve sur une seule ligne. Ce fichier ne contient aucun saut de ligne.
- Un tableau JSON avec un saut de ligne séparant les éléments du tableau. Chaque objet JSON peut également contenir des sauts de ligne.
Fichiers CSV compatibles
Dual Run est compatible avec les fichiers CSV conformes à la norme RFC 4180. Vous pouvez configurer la façon dont Dual Run analyse le fichier, y compris les délimiteurs, les en-têtes, les caractères d'échappement et les lignes multiples.
Étape suivante
En savoir plus sur la comparaison en ligne.