
Esta página descreve os principais componentes da execução dupla. Algumas partes da arquitetura são compartilhadas entre a comparação em lote e on-line, enquanto outras são específicas para cada carga de trabalho.
Componentes da execução dupla
Os componentes da execução dupla são executados como contêineres em um cluster do Google Kubernetes Engine (GKE). A execução dupla também depende de outros Google Cloud produtos, como o BigQuery, o Cloud Storage e outros componentes especializados para comparação em lote e on-line.
Os componentes do cluster de execução dupla compartilhados para cargas de trabalho on-line e em lote são os seguintes:
- Config Manager: a interface do usuário e os painéis.
- Env Checker: o mecanismo de verificação de instalação.
Config Manager
O Config Manager é o front-end do aplicativo de execução dupla. Use esse componente para gerenciar permissões de usuário, configurar cargas de trabalho on-line por endpoints e editar painéis. É possível configurar a autenticação do usuário usando o sistema Identity and Access Management.
O Config Manager também fornece o ambiente do painel em que é possível analisar os resultados da comparação. O painel permite visualizar um resumo dos resultados da comparação com base nos filtros aplicados e analisar os detalhes dos resultados de cada registro individual.
O painel é baseado no Apache Superset, um software de código aberto para visualização e exploração de dados. Ele também permite criar relatórios e consultas personalizados.
Env Checker
O Env Checker é o componente de execução dupla que verifica se a instalação e a implantação da execução dupla foram concluídas. Ele verifica se todos os componentes necessários da execução dupla estão configurados e em execução corretamente e, caso contrário, informa erros ou configurações incorretas.
Arquitetura para comparação em lote
O diagrama a seguir mostra a arquitetura de execução dupla para comparação em lote, conforme descrito nas seções a seguir.
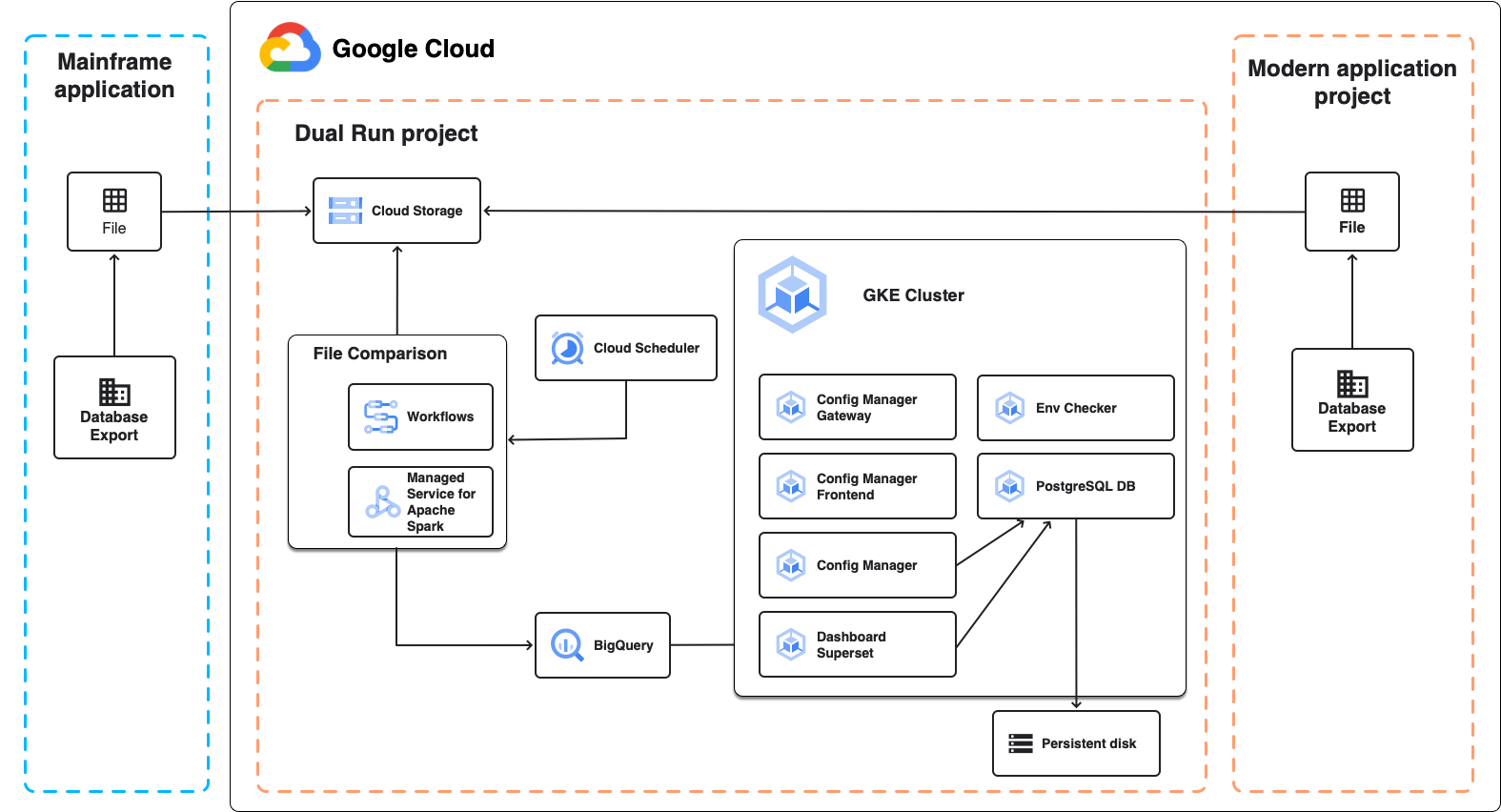
Comparação de arquivos
A comparação de arquivos é o componente de execução dupla que permite comparar as saídas de arquivos esperadas e reais da configuração de execução dupla. Ao realizar uma comparação, é possível definir o nível de tolerância para marcar os resultados como equivalentes.
A comparação de arquivos usa o Serviço Gerenciado para Apache Spark, um cluster do Apache Spark totalmente gerenciado em execução no Google Cloud, para realizar a comparação. Dependendo do tamanho dos dados que você planeja comparar e dos requisitos de infraestrutura, é possível escolher duas abordagens diferentes:
- Um ambiente gerenciado sem servidor baseado no Spark em execução no Serviço Gerenciado para Apache Spark, criado como parte da implantação de execução dupla. Ele usa uma configuração fixa que permite comparar arquivos de até vários GB. Essa é a abordagem padrão.
- Um cluster do Spark no Serviço Gerenciado para Apache Spark que você cria e configura após a implantação de execução dupla. Isso é útil nos seguintes casos:
- Você planeja usar configurações personalizadas de VM ou disco.
- Você precisa comparar arquivos maiores que vários GB.
- Você quer executar vários jobs de comparação ao mesmo tempo.
Arquitetura para comparação on-line
O diagrama a seguir mostra a arquitetura de execução dupla para comparação on-line, conforme descrito nas seções a seguir.
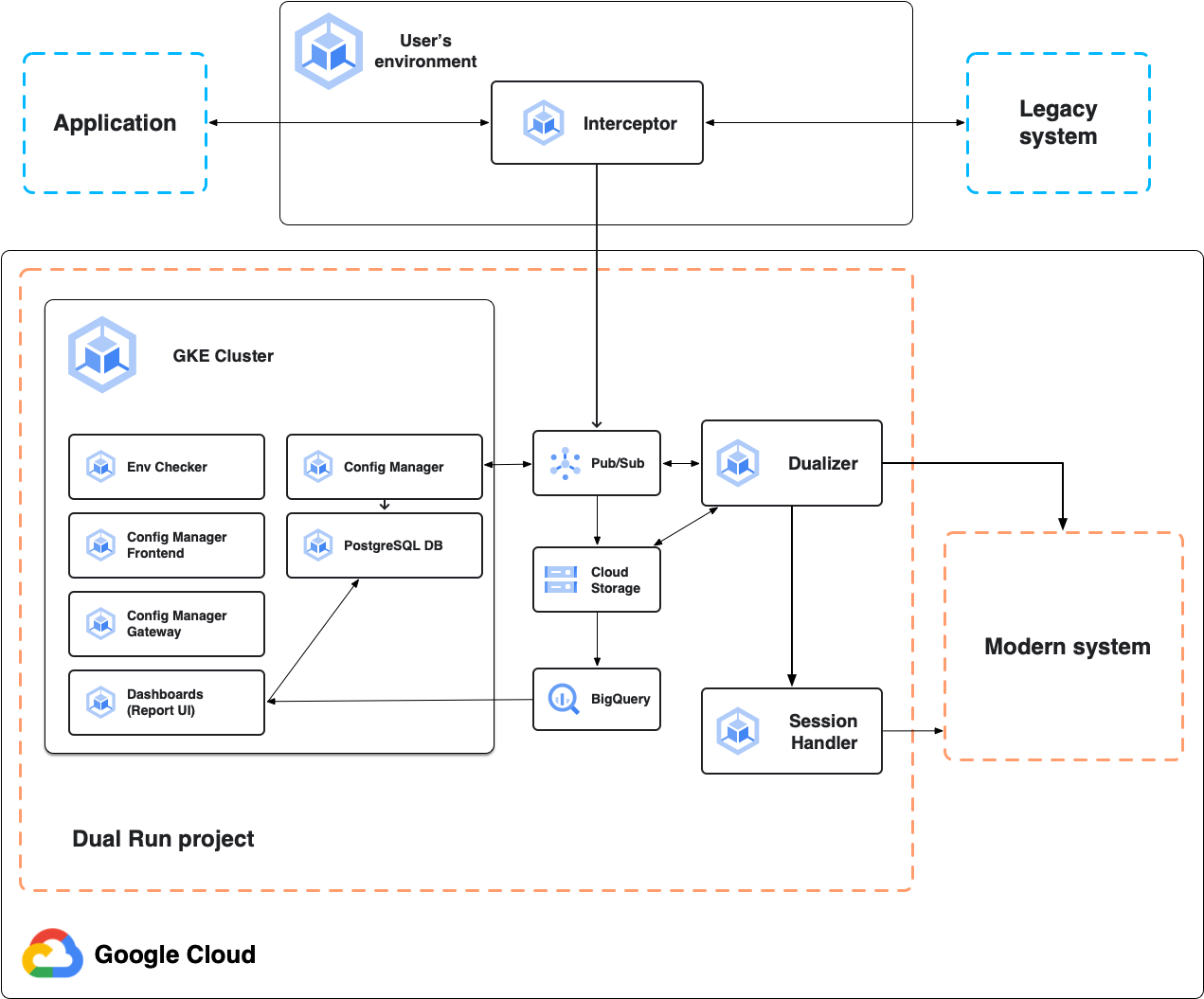
Interceptador
O interceptador atua como um proxy altamente confiável e eficiente para o sistema principal, o aplicativo de mainframe. Ele detecta o tráfego de aplicativos e encaminha solicitações para o sistema principal com latência mínima. Ele replica todas as solicitações e respostas para a dualização subsequente. É possível implantar o interceptador em qualquer ambiente baseado no Kubernetes, incluindo o projeto Dual Run ou seu ambiente local.
O interceptador opera mesmo quando a conexão com Google Cloud serviços falha, garantindo a máxima disponibilidade para o sistema principal.
A execução dupla oferece suporte a interceptadores para mensagens HTTP, TN3270 e MQ.
Dualizador
O dualizador reproduz transações on-line capturadas no sistema secundário modernizado. Ele consome transações gravadas na fila de dualização no Pub/Sub, envia solicitações ao sistema secundário e recupera respostas.
As respostas primárias e secundárias são comparadas usando o mesmo mecanismo de comparação subjacente usado pela comparação de arquivos para lote. Solicitações, respostas e resultados de comparação são armazenados no Cloud Storage, enquanto os resultados de comparação são transmitidos para o BigQuery. Os arquivos de configuração são gerenciados pelo Config Manager e lidos no Cloud Storage.
Gerenciador de sessão
O gerenciador de sessão é responsável por manter as sessões ativas com o sistema secundário. O gerenciador de sessão mantém um soquete TCP aberto por conexão de cliente para protocolos de comunicação com estado, como o TN3270. Para cada solicitação dualizada para o sistema secundário, o dualizador envia a solicitação dualizada para o processador de sessão. Em seguida, o gerenciador de sessão a envia para o sistema secundário usando o soquete aberto, recebe as respostas secundárias e as envia de volta ao dualizador para processamento.
Google Cloud Dependências
A execução dupla depende dos seguintes Google Cloud produtos para ser executada:
- Google Kubernetes Engine: A execução dupla usa o GKE para executar microsserviços em pods.
- Cloud Storage:a execução dupla armazena arquivos de configuração para seu ambiente e os artefatos de comparação fornecidos em buckets do Cloud Storage.
- Artifact Registry: O Dual Run armazena imagens de contêiner no registro para uso do GKE.
- BigQuery:a execução dupla armazena os resultados da comparação de transações em lote e on-line no BigQuery.
- Pub/Sub:a execução dupla usa o Pub/Sub como um sistema de mensagens interno para transmitir mudanças de configuração entre os diferentes pods.
- Cloud SQL:a execução dupla cria uma instância de banco de dados do Cloud SQL para garantir a compatibilidade com atualizações futuras.
A comparação em lote de execução dupla depende dos seguintes produtos adicionais:
- Serviço Gerenciado para Apache Spark:a execução dupla usa um cluster do Spark sem servidor no Serviço Gerenciado para Apache Spark para executar comparações de arquivos.
- Workflows e Cloud Run Functions:a execução dupla usa o Workflows para gerenciar as funções do Cloud Run que executam os jobs de comparação de arquivos.
- Identity and Access Management:a execução dupla depende do Identity and Access Management para autenticação e gerenciamento de acesso, o que permite usar provedores de identidade do Google ou SAML para autenticar e autorizar papéis de usuário.
A comparação on-line de execução dupla depende dos seguintes produtos adicionais:
- Secret Manager:a execução dupla usa o Secret Manager para armazenar secrets, como as credenciais do gerenciador de filas implantado para execução dupla.
- Cloud Monitoring: a execução dupla usa o Cloud Monitoring para coletar e monitorar métricas, eventos e registros dos componentes e Google Cloud recursos de execução dupla.
- Cloud Trace:a execução dupla usa o Cloud Trace para oferecer recursos aprimorados de monitoramento e depuração.
A seguir
Saiba mais sobre a comparação de arquivos de execução dupla .