
En esta página, se describen los componentes principales de Dual Run. Si bien algunas partes de la arquitectura se comparten entre la comparación por lotes y la comparación en línea, otras son específicas de cada carga de trabajo.
Componentes de Dual Run
Los componentes de Dual Run se ejecutan como contenedores en un clúster de Google Kubernetes Engine (GKE). Dual Run también se basa en otros Google Cloud productos, como BigQuery, Cloud Storage y otros componentes especializados para la comparación por lotes y la comparación en línea.
Los componentes del clúster de Dual Run que se comparten para las cargas de trabajo en línea y por lotes son los siguientes:
- Administrador de configuración: Es la interfaz de usuario y los paneles.
- Verificador de entorno: Es el motor de verificación de la instalación.
Administrador de configuración
El Administrador de configuración es el frontend de la aplicación Dual Run. Usas este componente para administrar los permisos de los usuarios, configurar cargas de trabajo en línea a través de extremos y editar paneles. Puedes configurar la autenticación de usuarios con el sistema de Identity and Access Management.
El Administrador de configuración también proporciona el entorno del panel en el que puedes revisar los resultados de la comparación. El panel te permite ver un resumen de los resultados de la comparación en función de los filtros que aplicas y revisar los detalles de los resultados de cada registro individual.
El panel se basa en Apache Superset, un software de código abierto para la visualización y exploración de datos. También te permite crear informes y consultas personalizados.
Verificador de entorno
El Verificador de entorno es el componente de Dual Run que verifica que la instalación y la implementación de Dual Run se hayan completado correctamente. Verifica que todos los componentes necesarios de Dual Run estén configurados y en ejecución correctamente y, de lo contrario, informa cualquier error o configuración incorrecta.
Arquitectura para la comparación por lotes
En el siguiente diagrama, se muestra la arquitectura de Dual Run para la comparación por lotes, como se describe en las siguientes secciones.
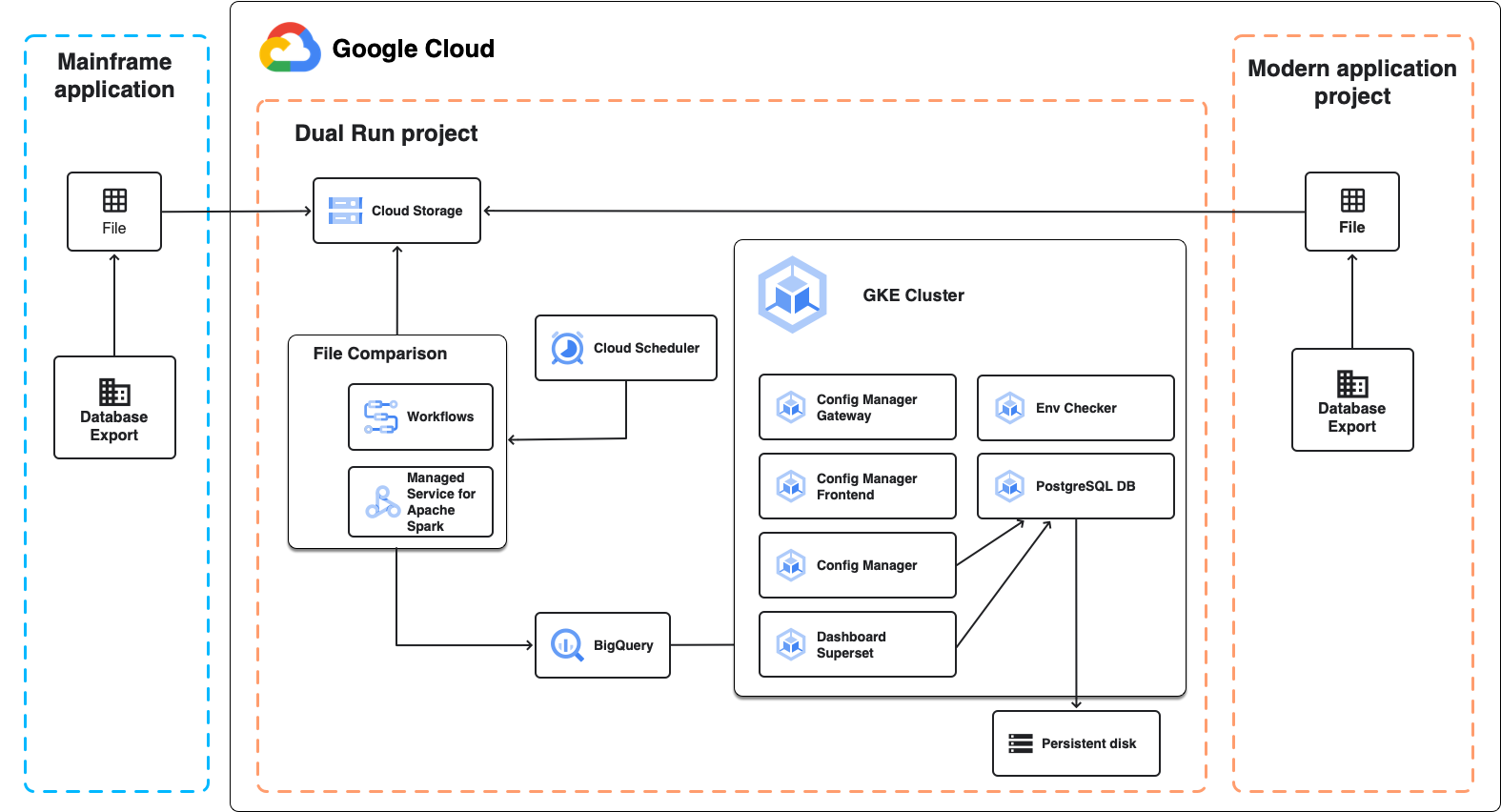
Comparación de archivos
La Comparación de archivos es el componente de Dual Run que te permite comparar los resultados de archivos esperados y reales de tu configuración de Dual Run. Cuando realizas una comparación, puedes establecer el nivel de tolerancia para marcar los resultados como equivalentes.
La Comparación de archivos usa Managed Service para Apache Spark, un clúster de Apache Spark completamente administrado que se ejecuta en Google Cloud, para realizar la comparación. Según el tamaño de los datos que planeas comparar y los requisitos de tu infraestructura, puedes elegir dos enfoques diferentes:
- Un entorno administrado sin servidores basado en Spark que se ejecuta en Managed Service para Apache Spark y que se crea como parte de la implementación de Dual Run. Usa una configuración fija que te permite comparar archivos de hasta varios GB. Este es el enfoque predeterminado.
- Un clúster de Spark en Managed Service para Apache Spark que creas y configuras después de la implementación de Dual Run. Esto es útil en los siguientes casos:
- Planeas usar configuraciones personalizadas de VM o disco.
- Necesitas comparar archivos de más de varios GB.
- Quieres ejecutar varios trabajos de comparación al mismo tiempo.
Arquitectura para la comparación en línea
En el siguiente diagrama, se muestra la arquitectura de Dual Run para la comparación en línea, como se describe en las siguientes secciones.
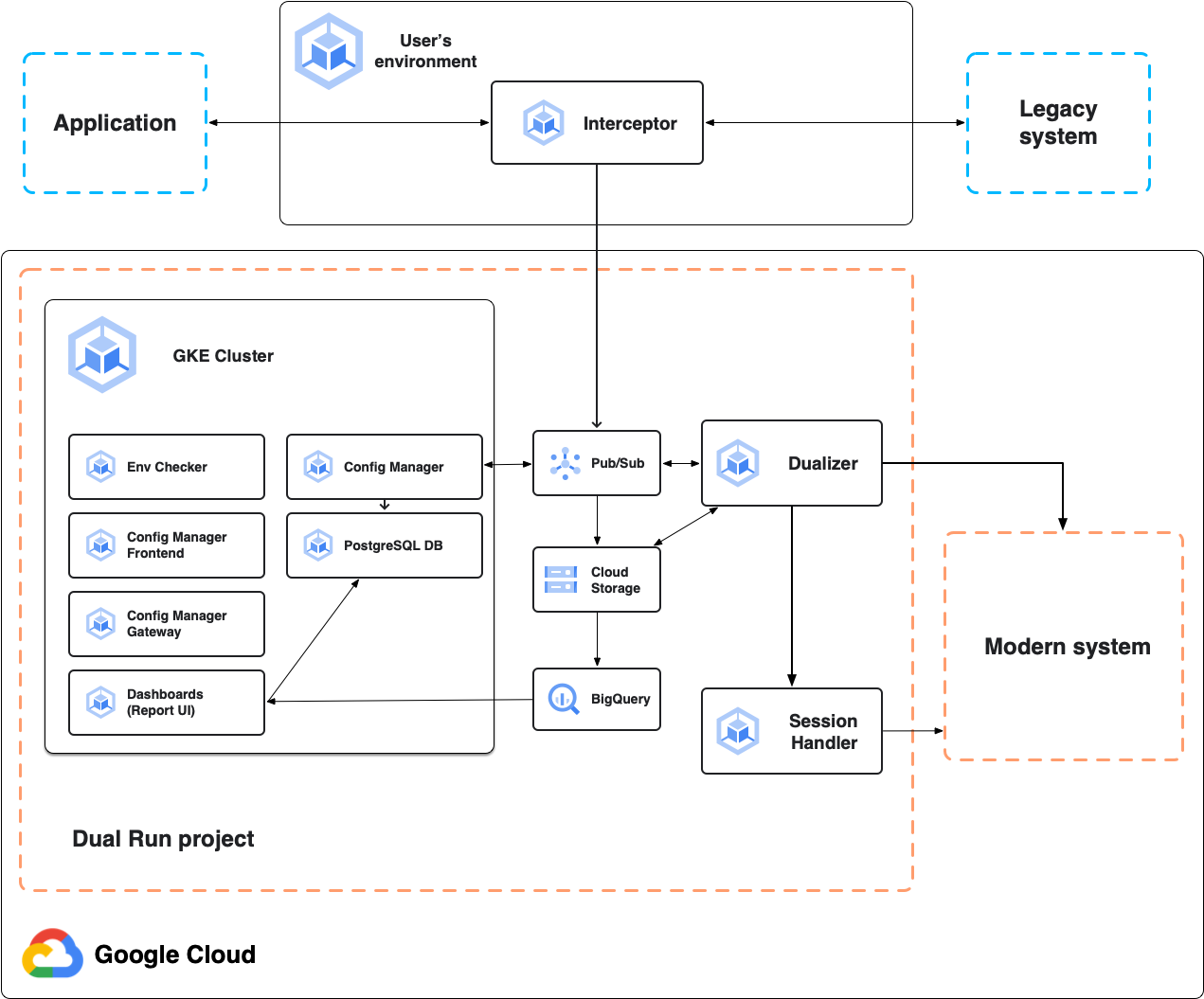
Interceptor
El interceptor actúa como un proxy altamente confiable y de alto rendimiento para el sistema principal, la aplicación de mainframe. Escucha el tráfico de la aplicación y reenvía las solicitudes al sistema principal con una latencia mínima. Replica todas las solicitudes y respuestas para la posterior dualización. Puedes implementar el interceptor en cualquier entorno basado en Kubernetes, incluido el proyecto de Dual Run o tu entorno local.
El interceptor opera incluso cuando falla la conexión a los Google Cloud servicios, lo que garantiza la máxima disponibilidad para el sistema principal.
Dual Run admite interceptores para mensajes HTTP, TN3270 y MQ.
Dualizador
El dualizador reproduce las transacciones en línea capturadas en el sistema secundario modernizado. Consume transacciones registradas de la cola de dualización en Pub/Sub, envía solicitudes al sistema secundario y recupera respuestas.
Las respuestas primarias y secundarias se comparan con el mismo motor de comparación subyacente que usa la Comparación de archivos para lotes. Las solicitudes, las respuestas y los resultados de la comparación se almacenan en Cloud Storage, mientras que los resultados de la comparación se transmiten a BigQuery. El Administrador de configuración administra los archivos de configuración y se leen desde Cloud Storage.
Controlador de sesiones
El controlador de sesiones es responsable de mantener las sesiones activas con el sistema secundario. El controlador de sesiones mantiene un socket TCP abierto por conexión de cliente para protocolos de comunicación con estado, como TN3270. Para cada solicitud dualizada al sistema secundario, el dualizador envía la solicitud dualizada al controlador de sesiones. Luego, el controlador de sesiones la envía al sistema secundario con el socket abierto, recibe las respuestas secundarias y las envía de vuelta al dualizador para su procesamiento.
Google Cloud dependencias
Dual Run se basa en los siguientes Google Cloud productos para ejecutarse:
- Google Kubernetes Engine: Dual Run usa GKE para ejecutar sus microservicios en pods.
- Cloud Storage: Dual Run almacena archivos de configuración para tu entorno y los artefactos de comparación que proporcionas en buckets de Cloud Storage.
- Artifact Registry: Dual Run almacena imágenes de contenedor en el registro para el uso de GKE.
- BigQuery: Dual Run almacena los resultados de la comparación para las transacciones por lotes y en línea en BigQuery.
- Pub/Sub: Dual Run usa Pub/Sub como un sistema de mensajería interno para pasar cambios de configuración entre sus diferentes pods.
- Cloud SQL: Dual Run crea una instancia de base de datos de Cloud SQL para garantizar la compatibilidad con futuras actualizaciones.
La comparación por lotes de Dual Run se basa en los siguientes productos adicionales:
- Managed Service para Apache Spark: Dual Run usa un clúster de Spark sin servidores en Managed Service para Apache Spark para ejecutar comparaciones de archivos.
- Workflows y Cloud Run Functions: Dual Run usa Workflows para administrar las Cloud Run Functions que realizan los trabajos de comparación de archivos.
- Identity and Access Management: Dual Run se basa en Identity and Access Management para la autenticación y la administración de acceso, lo que te permite usar proveedores de identidad de Google o SAML para autenticar y autorizar roles de usuario.
La comparación en línea de Dual Run se basa en los siguientes productos adicionales:
- Secret Manager: Dual Run usa Secret Manager para almacenar secretos, como las credenciales del administrador de colas que implementas para Dual Run.
- Cloud Monitoring: Dual Run usa Cloud Monitoring para recopilar y supervisar métricas, eventos y registros de tus componentes y Google Cloud recursos de Dual Run.
- Cloud Trace: Dual Run usa Cloud Trace para proporcionar capacidades mejoradas de supervisión y depuración.
¿Qué sigue?
Obtén más información sobre la Comparación de archivos de Dual Run File Comparison.