
Auf dieser Seite werden die Hauptkomponenten von Dual Run beschrieben. Einige Teile der Architektur werden für den Batch- und den Onlinevergleich gemeinsam genutzt, andere sind spezifisch für die jeweilige Arbeitslast.
Komponenten der dualen Ausführung
Dual Run-Komponenten werden als Container in einem Google Kubernetes Engine-Cluster (GKE) ausgeführt. Dual Run basiert auch auf anderen Google Cloud Produkten wie BigQuery, Cloud Storage und anderen spezialisierten Komponenten für den Batch- und Onlinevergleich.
Die Dual Run-Clusterkomponenten, die sowohl für Online- als auch für Batcharbeitslasten freigegeben sind, sind die folgenden:
- Config Manager: die Benutzeroberfläche und die Dashboards.
- Env Checker: die Engine zur Überprüfung der Installation.
Config Manager
Config Manager ist das Frontend der Dual Run-Anwendung. Mit dieser Komponente können Sie Nutzerberechtigungen verwalten, Onlinearbeitslasten über Endpunkte konfigurieren und Dashboards bearbeiten. Sie können die Nutzerauthentifizierung über das Identity and Access Management-System einrichten.
Config Manager bietet auch die Dashboard-Umgebung, in der Sie die Ergebnisse des Vergleichs ansehen können. Im Dashboard können Sie eine Zusammenfassung der Vergleichsergebnisse auf Grundlage der angewendeten Filter aufrufen und die Details der Ergebnisse für jeden einzelnen Datensatz ansehen.
Das Dashboard basiert auf Apache Superset, einer Open-Source-Software für die Datenvisualisierung und ‑exploration. Außerdem können Sie benutzerdefinierte Berichte und Abfragen erstellen.
Env Checker
Env Checker ist die Dual Run-Komponente, mit der geprüft wird, ob die Installation und Bereitstellung von Dual Run erfolgreich abgeschlossen wurde. Es wird geprüft, ob alle erforderlichen Dual Run-Komponenten richtig konfiguriert sind und ausgeführt werden. Andernfalls werden Fehler oder Falschkonfigurationen gemeldet.
Architektur für den Batchvergleich
Das folgende Diagramm zeigt die Dual Run-Architektur für den Batchvergleich, wie in den folgenden Abschnitten beschrieben.
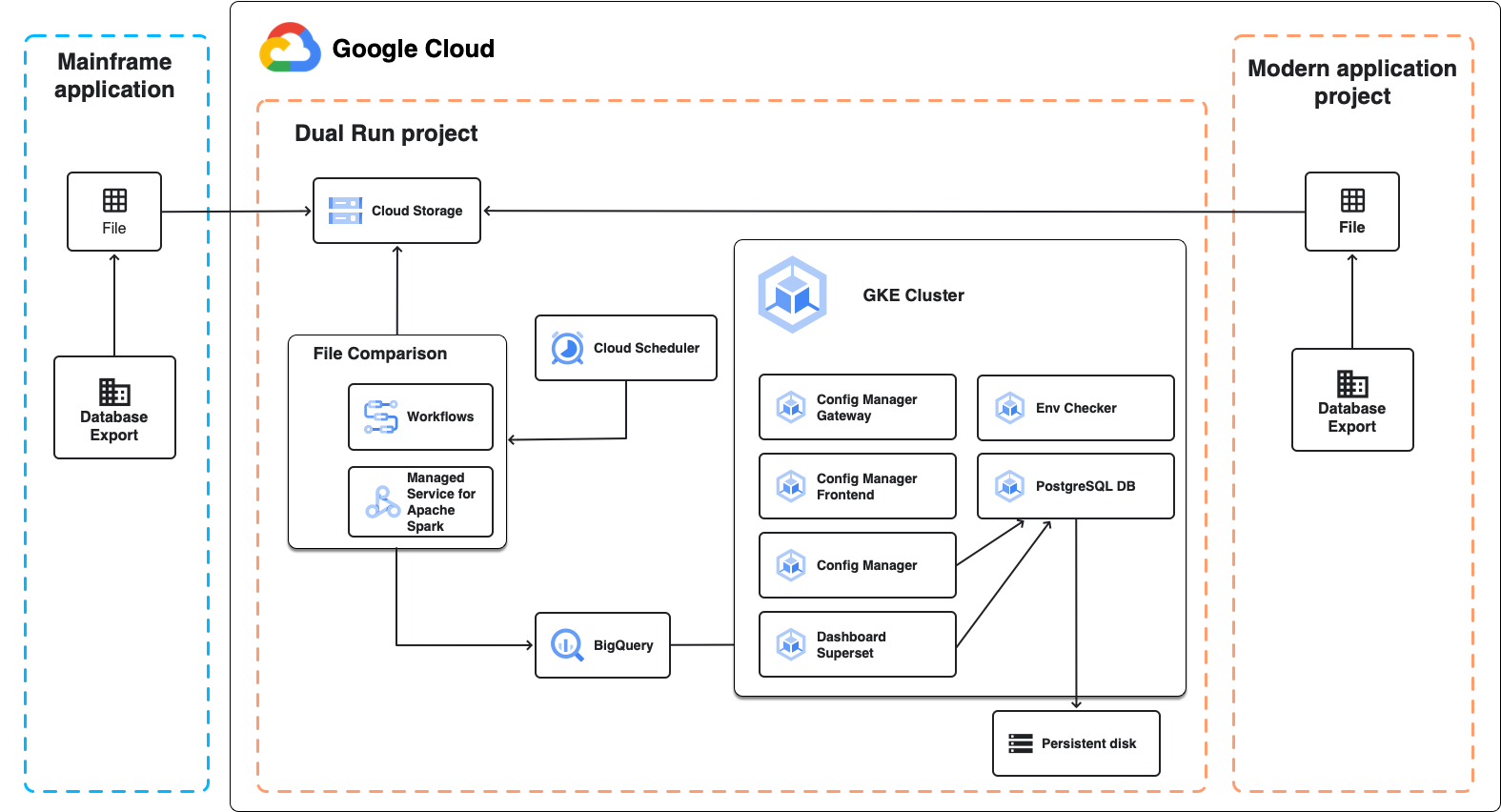
Dateivergleich
Der Dateivergleich ist die Dual Run-Komponente, mit der Sie die erwarteten und tatsächlichen Dateiausgaben Ihrer Dual Run-Einrichtung vergleichen können. Beim Vergleich können Sie die Toleranz festlegen, um die Ergebnisse als gleichwertig zu kennzeichnen.
Für den Dateivergleich wird Managed Service for Apache Spark verwendet, ein vollständig verwalteter Apache Spark-Cluster, der auf Google Cloudausgeführt wird. Je nach Umfang der Daten, die Sie vergleichen möchten, und je nach Ihren Infrastrukturanforderungen können Sie zwei verschiedene Ansätze wählen:
- Eine verwaltete serverlose Spark-basierte Umgebung, die in Managed Service for Apache Spark ausgeführt wird und als Teil der Dual Run-Bereitstellung erstellt wird. Es wird eine feste Konfiguration verwendet, mit der Sie Dateien mit einer Größe von bis zu mehreren GB vergleichen können. Dies ist der Standardansatz.
- Ein Spark-Cluster in Managed Service for Apache Spark, das Sie nach der Dual Run-Bereitstellung erstellen und konfigurieren. Das ist in folgenden Fällen nützlich:
- Sie planen, benutzerdefinierte VM- oder Laufwerkskonfigurationen zu verwenden.
- Sie müssen Dateien vergleichen, die mehrere GB groß sind.
- Sie möchten mehrere Vergleichsjobs gleichzeitig ausführen.
Architektur für den Onlinevergleich
Das folgende Diagramm zeigt die Dual Run-Architektur für den Onlinevergleich, wie in den folgenden Abschnitten beschrieben.
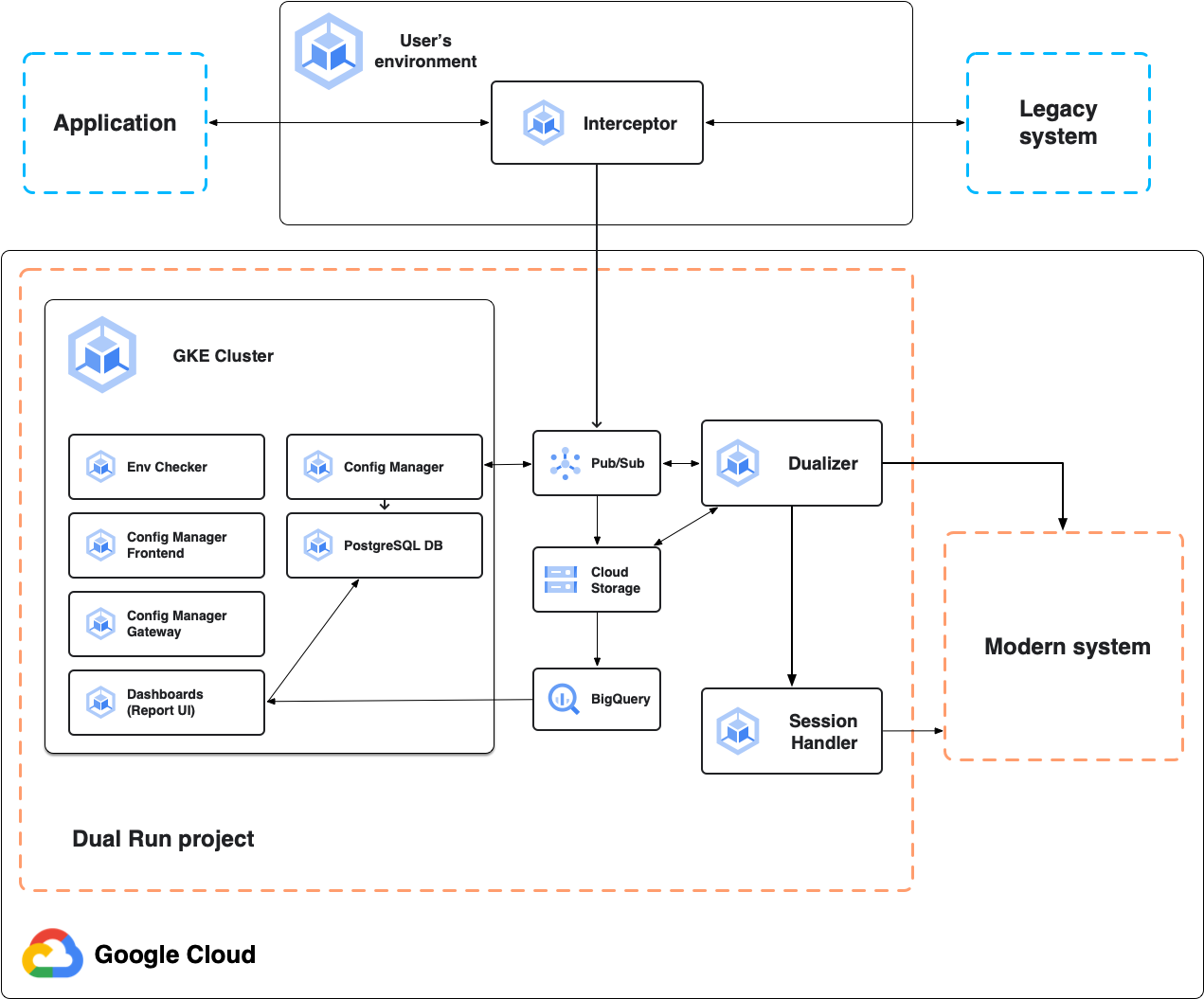
Interceptor
Der Interceptor fungiert als hochzuverlässiger und leistungsstarker Proxy für das primäre System, die Mainframe-Anwendung. Sie überwacht den Anwendungs-Traffic und leitet Anfragen mit minimaler Latenz an das primäre System weiter. Sie repliziert alle Anfragen und Antworten für die nachfolgende Dualisierung. Sie können den Interceptor in jeder Kubernetes-basierten Umgebung bereitstellen, einschließlich des Dual Run-Projekts oder Ihrer lokalen Umgebung.
Der Interceptor ist auch dann aktiv, wenn die Verbindung zu Google Cloud -Diensten fehlschlägt. So wird eine maximale Verfügbarkeit des primären Systems gewährleistet.
Dual Run unterstützt Interceptoren für HTTP-, TN3270- und MQ-Nachrichten.
Dualizer
Der Dualizer spielt erfasste Onlinetransaktionen im modernisierten sekundären System ab. Es verarbeitet aufgezeichnete Transaktionen aus der Dualisierungs-Warteschlange in Pub/Sub, sendet Anfragen an das sekundäre System und ruft Antworten ab.
Die primären und sekundären Antworten werden mit derselben zugrunde liegenden Vergleichs-Engine verglichen, die auch für den Batch-Dateivergleich verwendet wird. Anfragen, Antworten und Vergleichsergebnisse werden in Cloud Storage gespeichert, während Vergleichsergebnisse in BigQuery gestreamt werden. Die Konfigurationsdateien werden vom Config Manager verwaltet und aus Cloud Storage gelesen.
Sitzungshandler
Der Sitzungshandler ist für die Aufrechterhaltung der aktiven Sitzungen mit dem sekundären System verantwortlich. Der Sitzungshandler verwaltet einen offenen TCP-Socket pro Clientverbindung für zustandsorientierte Kommunikationsprotokolle wie TN3270. Für jede Anfrage, die an das sekundäre System dualisiert wird, sendet der Dualizer die dualisierte Anfrage an den Sitzungshandler. Der Sitzungshandler sendet sie dann über den geöffneten Socket an das sekundäre System, empfängt die sekundären Antworten und sendet sie zur Verarbeitung zurück an den Dualizer.
Google Cloud dependencies
Für Dual Run sind die folgenden Google Cloud Produkte erforderlich:
- Google Kubernetes Engine:Dual Run verwendet GKE, um seine Mikrodienste in Pods auszuführen.
- Cloud Storage:In Dual Run werden Konfigurationsdateien für Ihre Umgebung und die von Ihnen bereitgestellten Vergleichsartefakte in Cloud Storage-Buckets gespeichert.
- Artifact Registry:Dual Run speichert Container-Images in der Registry für die GKE-Nutzung.
- BigQuery:Bei Dual Run werden die Vergleichsergebnisse für Batch- und Onlinetransaktionen in BigQuery gespeichert.
- Pub/Sub:Bei Dual Run wird Pub/Sub als internes Nachrichtensystem verwendet, um Konfigurationsänderungen zwischen den verschiedenen Pods zu übergeben.
- Cloud SQL:Bei Dual Run wird eine Cloud SQL-Datenbankinstanz erstellt, um die Kompatibilität mit zukünftigen Updates zu gewährleisten.
Für den Batch-Vergleich im Dual Run sind die folgenden zusätzlichen Produkte erforderlich:
- Managed Service for Apache Spark:Bei Dual Run wird ein serverloser Spark-Cluster in Managed Service for Apache Spark verwendet, um Dateivergleiche auszuführen.
- Workflows und Cloud Run Functions:Dual Run verwendet Workflows, um die Cloud Run Functions zu verwalten, die die Dateivergleichsjobs ausführen.
- Identity and Access Management:Dual Run basiert auf Identity and Access Management für die Authentifizierung und Zugriffsverwaltung. So können Sie Google- oder SAML-Identitätsanbieter verwenden, um Nutzerrollen zu authentifizieren und zu autorisieren.
Für den Onlinevergleich im Dual Run sind die folgenden zusätzlichen Produkte erforderlich:
- Secret Manager:Dual Run verwendet Secret Manager zum Speichern von Secrets, z. B. der Anmeldedaten für den Warteschlangenmanager, den Sie für Dual Run bereitstellen.
- Cloud Monitoring:Dual Run verwendet Cloud Monitoring, um Messwerte, Ereignisse und Logs aus Ihren Dual Run-Komponenten und Google Cloud -Ressourcen zu erfassen und zu überwachen.
- Cloud Trace:Dual Run verwendet Cloud Trace, um erweiterte Überwachungs- und Debuggingfunktionen bereitzustellen.
Nächste Schritte
Weitere Informationen zum Dateivergleich in Dual Run