
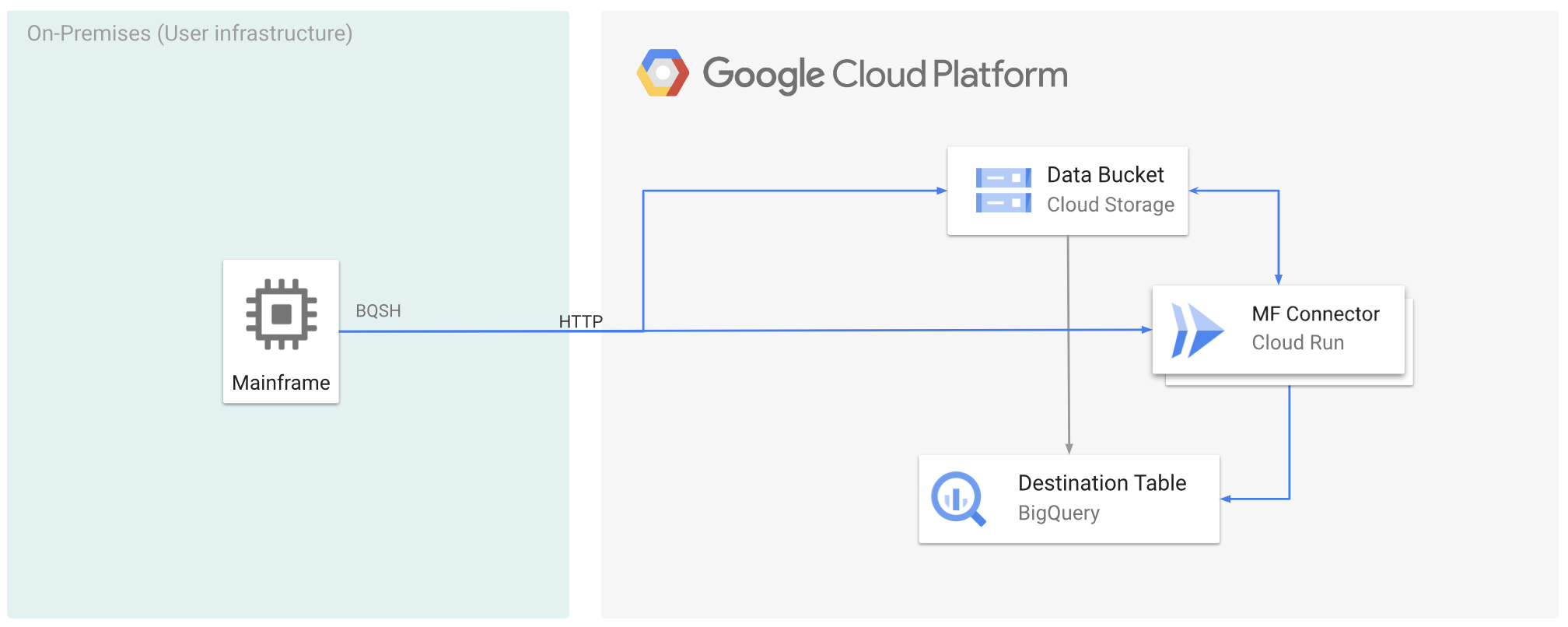
メインフレーム上でローカルにデータのコード変換を行うのは CPU 使用率の高いプロセスであり、100 万命令/秒(MIPS)の高い消費につながります。これを回避するには、Cloud Run を使用して、Google Cloud でメインフレーム データをリモートで移動してコード変換し、最適化された行の列(ORC)形式にしてから、データを Cloud Storage に移動します。これにより、メインフレームをビジネス クリティカルなタスクに解放し、MIPS の消費量も削減できます。
次の図は、メインフレーム データをGoogle Cloud に移動し、Cloud Run を使用してリモートで ORC 形式にコード変換してから、コンテンツを BigQuery に移動する方法を示しています。
始める前に
- Cloud Run に Mainframe Connector をデプロイする。
- Mainframe Connector で使用するサービス アカウントを作成するか、既存のサービス アカウントを特定します。このサービス アカウントには、Cloud Storage バケット、BigQuery データセット、使用するその他の Google Cloud リソースにアクセスする権限が必要です。
- 作成したサービス アカウントに Cloud Run 起動元ロールが割り当てられていることを確認します。
メインフレーム データを Google Cloud に移動し、Cloud Run を使用してリモートでコード変換する
メインフレーム データを Google Cloud に移動し、Cloud Run を使用してリモートでコード変換するには、次のタスクを行う必要があります。
- メインフレーム上のデータセットを読み取り、コード変換し、ORC 形式で Cloud Storage にアップロードします。コード変換は
gsutil cpオペレーション中に行われます。このオペレーションでは、メインフレームの拡張バイナリ コード 10 進数交換コード(EBCDIC)データセットが、Cloud Storage バケットへのコピー中に UTF-8 の ORC 形式に変換されます。 - データセットを BigQuery テーブルに読み込みます。
- (省略可)BigQuery テーブルで SQL クエリを実行します。
- (省略可)BigQuery から Cloud Storage のバイナリ ファイルにデータをエクスポートします。
これらのタスクを行うには、次の手順を行います。
メインフレームで、メインフレーム上のデータセットを読み取り、ORC 形式にコード変換するジョブを次のように作成します。INFILE データセットからデータを読み取り、COPYBOOK DD からレコード レイアウトを読み取ります。入力データセットは、固定または可変レコード長でキューに格納された順次アクセス方式(QSAM)ファイルである必要があります。
Mainframe Connector でサポートされている環境変数の一覧については、環境変数をご覧ください。
//STEP01 EXEC BQSH //INFILE DD DSN=<HLQ>.DATA.FILENAME,DISP=SHR //COPYBOOK DD DISP=SHR,DSN=<HLQ>.COPYBOOK.FILENAME //STDIN DD * gsutil cp --replace gs://mybucket/tablename.orc --remote \ --remoteHost <mainframe-connector-url>.a.run.app \ --remotePort 443 /*このプロセスで実行されたコマンドをログに記録する場合は、読み込み統計情報を有効にできます。
(省略可)QUERY DD ファイルから SQL 読み取りを実行する BigQuery クエリジョブを作成して送信します。 通常、クエリは
MERGEまたはSELECT INTO DMLステートメントであり、BigQuery テーブルが変換されます。Mainframe Connector は、ジョブ指標に記録しますが、クエリ結果をファイルに書き込みません。BigQuery にはさまざまな方法でクエリできます。インラインでクエリすることも、DD を使用して別のデータセットを使用してクエリすることもできます。DSN を使用して別のデータセットを使用してクエリすることもできます。
Example JCL //STEP03 EXEC BQSH //QUERY DD DSN=<HLQ>.QUERY.FILENAME,DISP=SHR //STDIN DD * PROJECT=PROJECT_NAME LOCATION=LOCATION bq query --project_id=$PROJECT \ --location=$LOCATION \ --remoteHost <mainframe-connector-url>.a.run.app \ --remotePort 443/* /*また、環境変数
BQ_QUERY_REMOTE_EXECUTION=trueを設定する必要があります。次のように置き換えます。
PROJECT_NAME: クエリを実行するプロジェクトの名前。LOCATION: クエリが実行されるロケーション。データの近くのロケーションでクエリを実行することをおすすめします。
(省略可)QUERY DD ファイルから SQL 読み取りを実行し、結果のデータセットをバイナリ ファイルとして Cloud Storage にエクスポートするエクスポート ジョブを作成して送信します。
Example JCL //STEP04 EXEC BQSH //OUTFILE DD DSN=<HLQ>.DATA.FILENAME,DISP=SHR //COPYBOOK DD DISP=SHR,DSN=<HLQ>.COPYBOOK.FILENAME //QUERY DD DSN=<HLQ>.QUERY.FILENAME,DISP=SHR //STDIN DD * PROJECT=PROJECT_NAME DATASET_ID=DATASET_ID DESTINATION_TABLE=DESTINATION_TABLE BUCKET=BUCKET bq export --project_id=$PROJECT \ --dataset_id=$DATASET_ID \ --destination_table=$DESTINATION_TABLE \ --location="US" \ --bucket=$BUCKET \ --remoteHost <mainframe-connector-url>.a.run.app \ --remotePort 443 /*以下を置き換えます。
PROJECT_NAME: クエリを実行するプロジェクトの名前。DATASET_ID: エクスポートするテーブルを含む BigQuery データセット ID。DESTINATION_TABLE: エクスポートする BigQuery テーブル。BUCKET: 出力バイナリ ファイルを含む Cloud Storage バケット。