
La transcodifica dei dati in locale su un mainframe è un processo che richiede un utilizzo elevato della CPU e comporta un elevato consumo di milioni di istruzioni al secondo (MIPS). Per evitare questo problema, puoi utilizzare Cloud Run per spostare e transcodificare i dati del mainframe in remoto suGoogle Cloud nel formato ORC (Optimized Row Columnar) e poi spostare i dati in Cloud Storage. In questo modo, il mainframe è libero per le attività business-critical e si riduce anche il consumo di MIPS.
La figura seguente descrive come spostare i dati del mainframe in Google Cloud e transcodificarli in remoto nel formato ORC utilizzando Cloud Run, per poi spostare i contenuti in BigQuery.
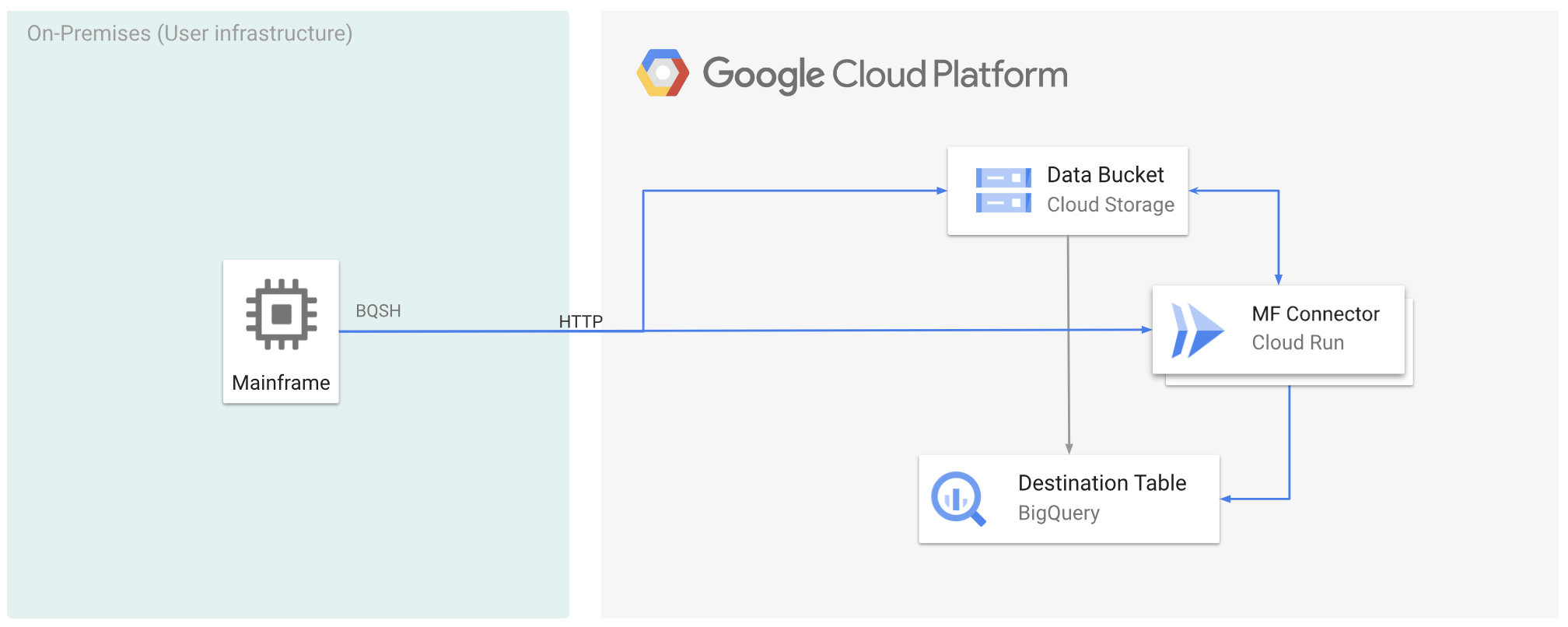
Prima di iniziare
- Esegui il deployment di Mainframe Connector su Cloud Run.
- Crea un service account o identifica un account di serviziot esistente da utilizzare con Mainframe Connector. Questo account di servizio deve disporre delle autorizzazioni per accedere ai bucket Cloud Storage, ai set di dati BigQuery e a qualsiasi altra risorsa Google Cloud che vuoi utilizzare.
- Verifica che al account di servizio che hai creato sia assegnato il ruolo Invoker Cloud Run.
Sposta i dati del mainframe in Google Cloud e transcodificali da remoto utilizzando Cloud Run
Per spostare i dati del mainframe in Google Cloud e transcodificarli da remoto utilizzando Cloud Run, devi svolgere le seguenti attività:
- Leggi e transcodifica un set di dati su un mainframe e caricalo in Cloud Storage
in formato ORC. La transcodifica viene eseguita durante l'operazione
gsutil cp, in cui un set di dati EBCDIC (Extended Binary Coded Decimal Interchange Code) del mainframe viene convertito nel formato ORC in UTF-8 durante la copia in un bucket Cloud Storage. - Carica il set di dati in una tabella BigQuery.
- (Facoltativo) Esegui una query SQL sulla tabella BigQuery.
- (Facoltativo) Esporta i dati da BigQuery in un file binario in Cloud Storage.
Per eseguire queste attività, segui questi passaggi:
Sul mainframe, crea un job per leggere il set di dati sul mainframe e trascodificarlo nel formato ORC, come segue. Leggi i dati dal set di dati INFILE e il layout del record da COPYBOOK DD. Il set di dati di input deve essere un file con metodo di accesso sequenziale in coda (QSAM) con lunghezza del record fissa o variabile.
Per l'elenco completo delle variabili di ambiente supportate da Mainframe Connector, consulta Variabili di ambiente.
//STEP01 EXEC BQSH //INFILE DD DSN=<HLQ>.DATA.FILENAME,DISP=SHR //COPYBOOK DD DISP=SHR,DSN=<HLQ>.COPYBOOK.FILENAME //STDIN DD * gsutil cp --replace gs://mybucket/tablename.orc --remote \ --remoteHost <mainframe-connector-url>.a.run.app \ --remotePort 443 /*Se vuoi registrare i comandi eseguiti durante questa procedura, puoi attivare le statistiche di caricamento.
(Facoltativo) Crea e invia un job di query BigQuery che esegue una lettura SQL dal file QUERY DD. In genere, la query è un'istruzione
MERGEoSELECT INTO DMLche comporta la trasformazione di una tabella BigQuery. Tieni presente che Mainframe Connector registra le metriche dei job, ma non scrive i risultati della query in un file.Puoi eseguire query BigQuery in vari modi: inline, con un set di dati separato utilizzando DD o con un set di dati separato utilizzando DSN.
Example JCL //STEP03 EXEC BQSH //QUERY DD DSN=<HLQ>.QUERY.FILENAME,DISP=SHR //STDIN DD * PROJECT=PROJECT_NAME LOCATION=LOCATION bq query --project_id=$PROJECT \ --location=$LOCATION \ --remoteHost <mainframe-connector-url>.a.run.app \ --remotePort 443/* /*Inoltre, devi impostare la variabile di ambiente
BQ_QUERY_REMOTE_EXECUTION=true.Sostituisci quanto segue:
PROJECT_NAME: il nome del progetto in cui vuoi eseguire la query.LOCATION: la posizione in cui verrà eseguita la query. Ti consigliamo di eseguire la query in una località vicina ai dati.
(Facoltativo) Crea e invia un job di esportazione che esegue una lettura SQL dal file QUERY DD ed esporta il set di dati risultante in Cloud Storage come file binario.
Example JCL //STEP04 EXEC BQSH //OUTFILE DD DSN=<HLQ>.DATA.FILENAME,DISP=SHR //COPYBOOK DD DISP=SHR,DSN=<HLQ>.COPYBOOK.FILENAME //QUERY DD DSN=<HLQ>.QUERY.FILENAME,DISP=SHR //STDIN DD * PROJECT=PROJECT_NAME DATASET_ID=DATASET_ID DESTINATION_TABLE=DESTINATION_TABLE BUCKET=BUCKET bq export --project_id=$PROJECT \ --dataset_id=$DATASET_ID \ --destination_table=$DESTINATION_TABLE \ --location="US" \ --bucket=$BUCKET \ --remoteHost <mainframe-connector-url>.a.run.app \ --remotePort 443 /*Sostituisci quanto segue:
PROJECT_NAME: il nome del progetto in cui vuoi eseguire la query.DATASET_ID: l'ID del set di dati BigQuery che contiene la tabella che vuoi esportare.DESTINATION_TABLE: la tabella BigQuery che vuoi esportare.BUCKET: il bucket Cloud Storage che conterrà il file binario di output.