
在大型主機上進行本機轉碼是 CPU 密集型程序,會導致每秒百萬指令數 (MIPS) 消耗量偏高。為避免發生這種情況,您可以使用 Cloud Run,在Google Cloud 上以遠端方式移動大型主機資料並轉碼為最佳化資料列直欄 (ORC) 格式,然後將資料移至 Cloud Storage。這樣一來,大型主機就能專心處理重要業務工作,還能減少 MIPS 消耗量。
下圖說明如何將大型主機資料移至Google Cloud ,並使用 Cloud Run 遠端轉碼為 ORC 格式,然後將內容移至 BigQuery。
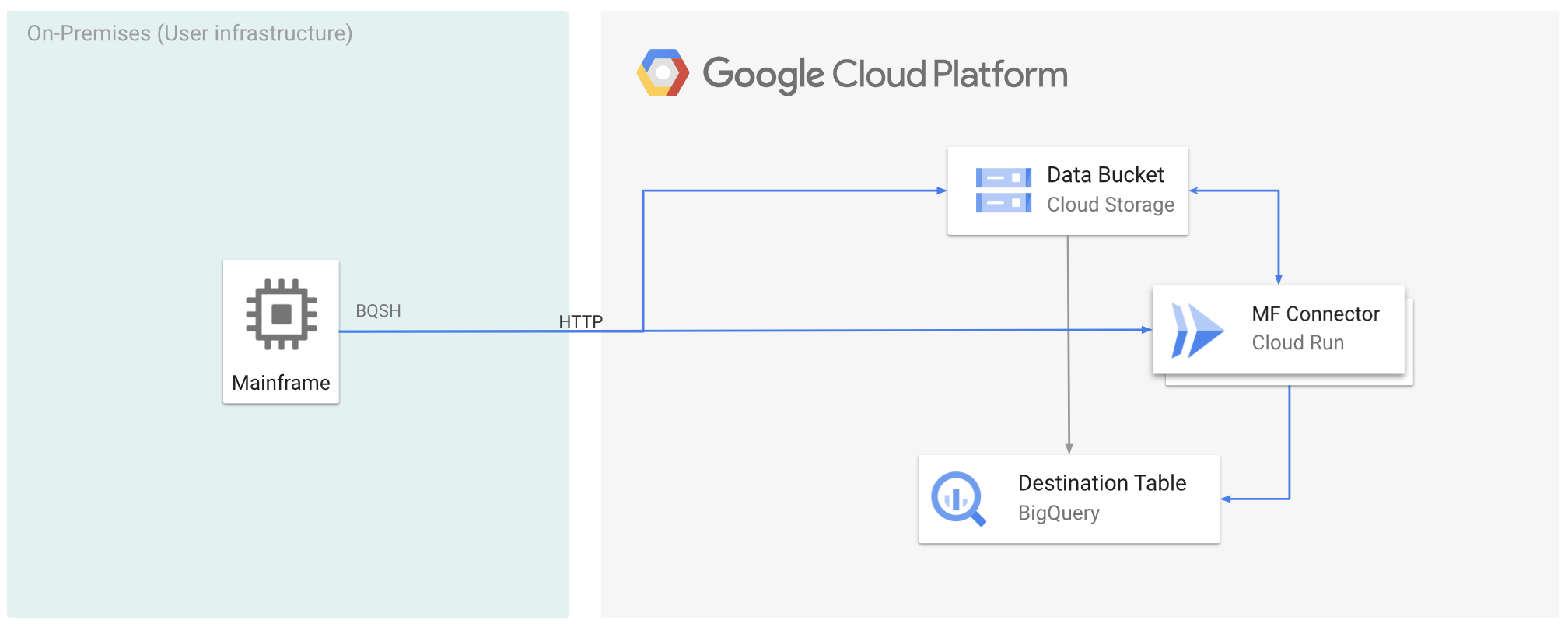
事前準備
- 在 Cloud Run 上部署 Mainframe Connector。
- 建立服務帳戶,或找出要與 Mainframe Connector 搭配使用的現有服務帳戶。這個服務帳戶必須具備存取 Cloud Storage bucket、BigQuery 資料集,以及您想使用的任何其他 Google Cloud 資源的權限。
- 確認您建立的服務帳戶已獲派 Cloud Run Invoker 角色。
將大型主機資料移至 Google Cloud ,並使用 Cloud Run 遠端轉碼
如要將大型主機資料移至 Google Cloud ,並使用 Cloud Run 遠端轉碼,請執行下列工作:
- 讀取並轉碼大型主機上的資料集,然後以 ORC 格式上傳至 Cloud Storage。轉碼作業會在
gsutil cp作業期間完成,也就是在複製到 Cloud Storage 值區時,將大型主機擴充二進位編碼十進位交換碼 (EBCDIC) 資料集轉換為 UTF-8 中的 ORC 格式。 - 將資料集載入 BigQuery 資料表。
- (選用) 對 BigQuery 資料表執行 SQL 查詢。
- (選用) 將資料從 BigQuery 匯出至 Cloud Storage 中的二進位檔案。
如要執行這些工作,請按照下列步驟操作:
在大型主機上建立工作,讀取大型主機上的資料集,並轉碼為 ORC 格式,如下所示。從 INFILE 資料集讀取資料,並從 COPYBOOK DD 讀取記錄版面配置。輸入資料集必須是具有固定或可變記錄長度的佇列循序存取方法 (QSAM) 檔案。
如需 Mainframe Connector 支援的環境變數完整清單,請參閱「環境變數」。
//STEP01 EXEC BQSH //INFILE DD DSN=<HLQ>.DATA.FILENAME,DISP=SHR //COPYBOOK DD DISP=SHR,DSN=<HLQ>.COPYBOOK.FILENAME //STDIN DD * gsutil cp --replace gs://mybucket/tablename.orc --remote \ --remoteHost <mainframe-connector-url>.a.run.app \ --remotePort 443 /*如要記錄這個程序執行的指令,可以啟用載入統計資料。
(選用) 建立並提交 BigQuery 查詢作業,從 QUERY DD 檔案執行 SQL 讀取作業。查詢通常是
MERGE或SELECT INTO DML陳述式,可轉換 BigQuery 資料表。請注意,Mainframe Connector 會將記錄寫入工作指標,但不會將查詢結果寫入檔案。您可以透過多種方式查詢 BigQuery,包括內嵌、使用 DD 的獨立資料集,或使用 DSN 的獨立資料集。
Example JCL //STEP03 EXEC BQSH //QUERY DD DSN=<HLQ>.QUERY.FILENAME,DISP=SHR //STDIN DD * PROJECT=PROJECT_NAME LOCATION=LOCATION bq query --project_id=$PROJECT \ --location=$LOCATION \ --remoteHost <mainframe-connector-url>.a.run.app \ --remotePort 443/* /*此外,您必須設定環境變數
BQ_QUERY_REMOTE_EXECUTION=true。更改下列內容:
PROJECT_NAME:要執行查詢的專案名稱。LOCATION:執行查詢的位置。建議您在靠近資料的位置執行查詢。
(選用) 建立並提交匯出工作,從 QUERY DD 檔案執行 SQL 讀取作業,然後將產生的資料集匯出至 Cloud Storage 做為二進位檔案。
Example JCL //STEP04 EXEC BQSH //OUTFILE DD DSN=<HLQ>.DATA.FILENAME,DISP=SHR //COPYBOOK DD DISP=SHR,DSN=<HLQ>.COPYBOOK.FILENAME //QUERY DD DSN=<HLQ>.QUERY.FILENAME,DISP=SHR //STDIN DD * PROJECT=PROJECT_NAME DATASET_ID=DATASET_ID DESTINATION_TABLE=DESTINATION_TABLE BUCKET=BUCKET bq export --project_id=$PROJECT \ --dataset_id=$DATASET_ID \ --destination_table=$DESTINATION_TABLE \ --location="US" \ --bucket=$BUCKET \ --remoteHost <mainframe-connector-url>.a.run.app \ --remotePort 443 /*更改下列內容:
PROJECT_NAME:要執行查詢的專案名稱。DATASET_ID:包含要匯出資料表的 BigQuery 資料集 ID。DESTINATION_TABLE:要匯出的 BigQuery 資料表。BUCKET:用於存放輸出二進位檔案的 Cloud Storage bucket。