
在大型机上本地转码数据是一个 CPU 密集型过程,会导致每秒百万条指令 (MIPS) 消耗量很高。为避免这种情况,您可以使用 Cloud Run 在Google Cloud 上远程移动大型主机数据并将其转码为优化的行式列式 (ORC) 格式,然后将数据移至 Cloud Storage。这样一来,大型主机就可以专注于处理关键业务任务,同时还能减少 MIPS 消耗。
下图描述了如何使用 Cloud Run 将大型机数据移至Google Cloud 并远程将其转码为 ORC 格式,然后将内容移至 BigQuery。
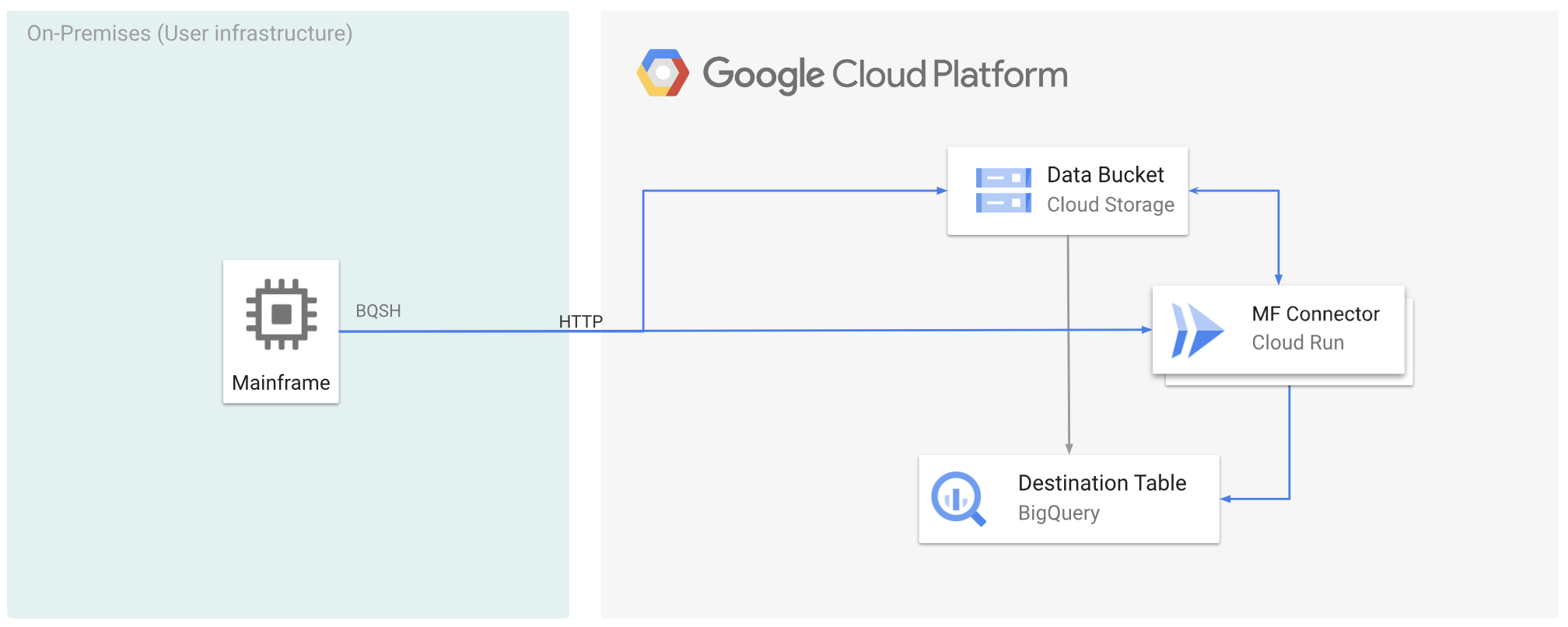
准备工作
- 在 Cloud Run 上部署 Mainframe Connector。
- 创建服务账号或确定要与 Mainframe Connector 搭配使用的现有服务账号。此服务账号必须具有访问 Cloud Storage 存储分区、BigQuery 数据集以及您要使用的任何其他 Google Cloud 资源的权限。
- 验证您创建的服务账号是否已分配 Cloud Run Invoker 角色。
将大型主机数据迁移到 Google Cloud 并使用 Cloud Run 远程转码
如需将大型主机数据迁移到 Google Cloud 并使用 Cloud Run 远程转码,您必须执行以下任务:
- 读取大型机上的数据集并将其转码,然后以 ORC 格式上传到 Cloud Storage。转码是在
gsutil cp操作期间完成的,在此操作期间,大型机扩展二进制编码十进制交换码 (EBCDIC) 数据集在复制到 Cloud Storage 存储桶时会转换为 UTF-8 中的 ORC 格式。 - 将数据集加载到 BigQuery 表中。
- (可选)对 BigQuery 表执行 SQL 查询。
- (可选)将数据从 BigQuery 导出到 Cloud Storage 中的二进制文件。
如需执行上述任务,请按以下步骤操作:
在大型主机上,创建一个作业以读取大型主机上的数据集并将其转码为 ORC 格式,如下所示。从 INFILE 数据集读取数据,并从 COPYBOOK DD 读取记录布局。输入数据集必须是具有固定或可变记录长度的排队顺序存取方法 (QSAM) 文件。
如需查看 Mainframe Connector 支持的环境变量的完整列表,请参阅环境变量。
//STEP01 EXEC BQSH //INFILE DD DSN=<HLQ>.DATA.FILENAME,DISP=SHR //COPYBOOK DD DISP=SHR,DSN=<HLQ>.COPYBOOK.FILENAME //STDIN DD * gsutil cp --replace gs://mybucket/tablename.orc --remote \ --remoteHost <mainframe-connector-url>.a.run.app \ --remotePort 443 /*如果您想记录此过程中执行的命令,可以启用加载统计信息。
(可选)创建并提交一个 BigQuery 查询作业,该作业会执行从 QUERY DD 文件读取数据的 SQL 操作。通常,该查询将是
MERGE或SELECT INTO DML语句,用于转换 BigQuery 表。请注意,Mainframe Connector 会在作业指标中记录,但不会将查询结果写入文件。您可以通过多种方式查询 BigQuery,例如内嵌查询、使用 DD 的单独数据集查询或使用 DSN 的单独数据集查询。
Example JCL //STEP03 EXEC BQSH //QUERY DD DSN=<HLQ>.QUERY.FILENAME,DISP=SHR //STDIN DD * PROJECT=PROJECT_NAME LOCATION=LOCATION bq query --project_id=$PROJECT \ --location=$LOCATION \ --remoteHost <mainframe-connector-url>.a.run.app \ --remotePort 443/* /*此外,您还必须设置环境变量
BQ_QUERY_REMOTE_EXECUTION=true。替换以下内容:
PROJECT_NAME:您要在其中执行查询的项目的名称。LOCATION:执行查询的位置。我们建议您在靠近数据的位置执行查询。
(可选)创建并提交导出作业,该作业会从 QUERY DD 文件执行 SQL 读取,并将生成的数据集以二进制文件形式导出到 Cloud Storage。
Example JCL //STEP04 EXEC BQSH //OUTFILE DD DSN=<HLQ>.DATA.FILENAME,DISP=SHR //COPYBOOK DD DISP=SHR,DSN=<HLQ>.COPYBOOK.FILENAME //QUERY DD DSN=<HLQ>.QUERY.FILENAME,DISP=SHR //STDIN DD * PROJECT=PROJECT_NAME DATASET_ID=DATASET_ID DESTINATION_TABLE=DESTINATION_TABLE BUCKET=BUCKET bq export --project_id=$PROJECT \ --dataset_id=$DATASET_ID \ --destination_table=$DESTINATION_TABLE \ --location="US" \ --bucket=$BUCKET \ --remoteHost <mainframe-connector-url>.a.run.app \ --remotePort 443 /*替换以下内容:
PROJECT_NAME:您要在其中执行查询的项目的名称。DATASET_ID:包含要导出的表的 BigQuery 数据集 ID。DESTINATION_TABLE:要导出的 BigQuery 表。BUCKET:将包含输出二进制文件的 Cloud Storage 存储桶。