
用法
explore: explore_name {
join: view_name { ... }
}
|
层次结构
join |
默认值
无
接受
现有视图的名称
特殊规则
|
定义
借助 join,您可以定义探索与视图之间的联接关系,以便合并来自多个视图的数据。您可以根据需要,为任意给定的探索联接任意数量的视图。
请注意,每个视图都与数据库中的某个表或您在 Looker 中定义的派生表相关联。同样,由于探索与视图相关联,因此它也与某种表相关联。
与探索相关联的表会放置在 Looker 生成的 SQL 的 FROM 子句中。与联接视图相关联的表会放置在 Looker 生成的 SQL 的 JOIN 子句中。
主要联接参数
如需定义 Explore 与视图之间的联接关系(SQL ON 子句),您需要将 join 与其他参数结合使用。
您必须使用 sql_on 或 foreign_key 参数来建立 SQL ON 子句。
您还需要确保使用适当的联接类型和关系,不过 type 和 relationship 参数并不总是明确要求。如果其默认值 type: left_outer 和 relationship: many_to_one 适合您的使用情形,则可以排除这些参数。
这些关键参数及其与 Looker 生成的 SQL 的关系可以总结如下:
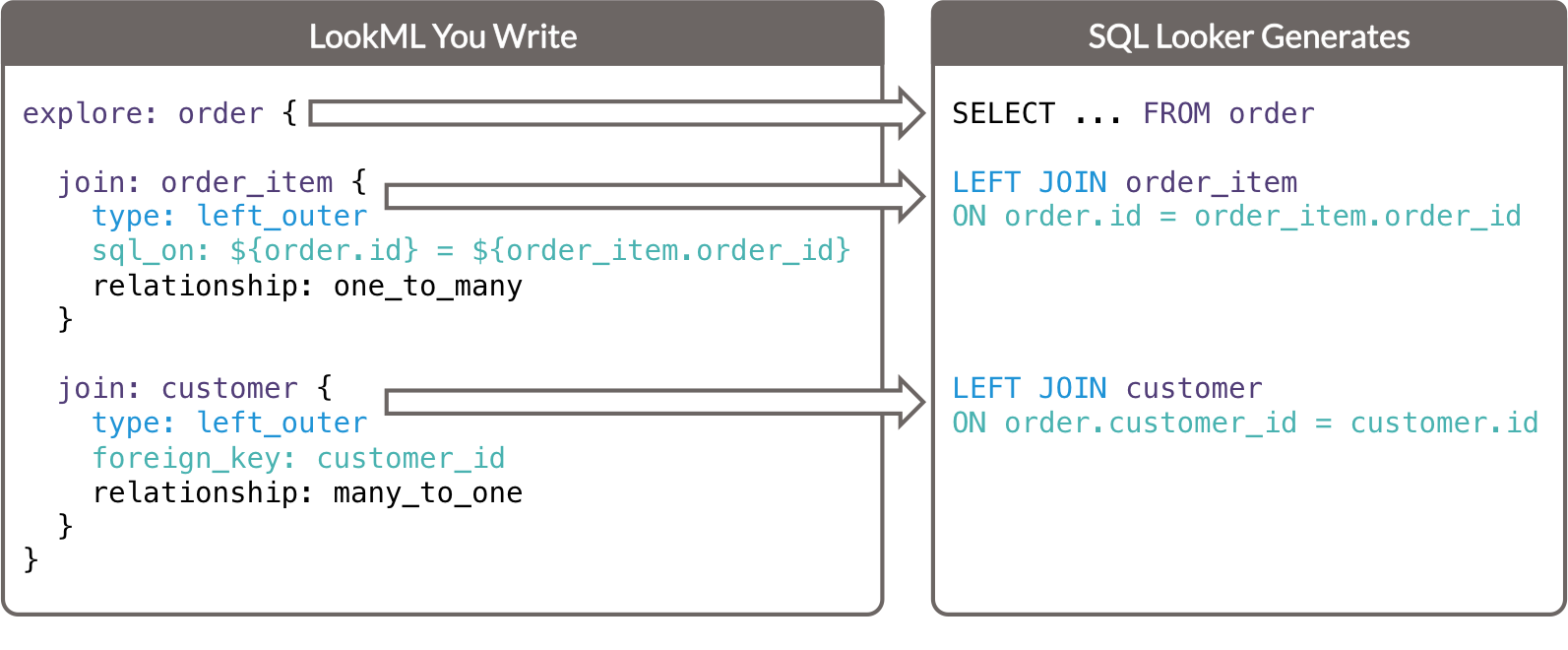
explore参数决定了生成的 SQL 查询的FROM子句中的表。- 每个
join参数都会确定生成的 SQL 查询的JOIN子句。type参数用于确定 SQL 联接的类型。sql_on参数和foreign_key参数决定了生成的 SQL 查询的ON子句。
sql_on
sql_on 可让您直接编写 SQL ON 子句来建立联接关系。它可以实现与 foreign_key 相同的联接,但更易于阅读和理解。
如需了解详情,请参阅 sql_on 参数文档页面。
foreign_key
foreign_key 可让您使用联接视图的主键建立联接关系,并将其与探索中的维度相关联。这种模式在数据库设计中非常常见,而 foreign_key 是一种在这些情况下表达联接的优雅方式。
如需全面了解,请参阅 foreign_key 参数文档页面。
type
Looker 中的大多数联接都是 LEFT JOIN,原因如本页面的尽可能不要在联接中应用业务逻辑部分中所述。因此,如果您未明确添加 type,Looker 会假定您需要 LEFT JOIN。不过,如果您因某种原因需要其他类型的联接,可以使用 type 来实现。
如需查看完整说明,请参阅 type 参数文档页面。
relationship
relationship 对 Looker 生成的 SQL 没有直接影响,但对于 Looker 的正常运行至关重要。如果您未明确添加 relationship,Looker 会将关系解读为 many-to-one,这意味着探索中的许多行在联接的视图中可以有一行。并非所有联接都具有这种类型的关系,具有其他关系的联接需要正确声明。many-to-one
如需全面了解,请参阅 relationship 参数文档页面。
示例
将名为 customer 的视图与名为 order 的探索相关联,其中关联关系为
FROM order LEFT JOIN customer ON order.customer_id = customer.id:
explore: order {
join: customer {
foreign_key: customer_id
relationship: many_to_one # Could be excluded since many_to_one is the default
type: left_outer # Could be excluded since left_outer is the default
}
}
将名为 address 的视图与名为 person 的探索相关联,其中关联关系为
FROM person LEFT JOIN address ON person.id = address.person_id
AND address.type = 'permanent':
explore: person {
join: address {
sql_on: ${person.id} = ${address.person_id} AND ${address.type} = 'permanent' ;;
relationship: one_to_many
type: left_outer # Could be excluded since left_outer is the default
}
}
将名为 member 的视图与名为 event 的探索相关联,其中关联关系为
FROM event INNER JOIN member ON member.id = event.member_id:
explore: event {
join: member {
sql_on: ${event.member_id} = ${member.id} ;;
relationship: many_to_one # Could be excluded since many_to_one is the default
type: inner
}
}
常见挑战
join 必须使用视图名称,而不是底层表名称
join 参数仅接受视图名称,而不接受与该视图关联的表名称。通常,视图名称和表名称是相同的,这可能会导致错误地认为可以使用表名称。
某些类型的衡量指标需要对称汇总
如果您未使用对称聚合,则大多数度量类型都会从联接视图中排除。为了让 Looker 在 Looker 项目中支持对称聚合,您的数据库方言也必须支持对称聚合。下表显示了 Looker 最新版本中哪些方言支持对称聚合:
| 方言 | 是否支持? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
如果没有对称聚合,非一对一的联接关系可能会在聚合函数中产生不准确的结果。由于 Looker 度量是聚合函数,因此只有 type: count 的度量(以 COUNT DISTINCT 为单位)会从联接的视图带入探索。如果您确实有一对一的联接关系,可以使用 relationship 参数强制包含其他度量类型,如下所示:
explore: person {
join: dna {
sql_on: ${person.dna_id} = ${dna.id} ;;
relationship: one_to_one
}
}
有关 Looker 为何以这种方式运行(对于不支持对称聚合的方言)的详细原因,请参阅SQL 扇出的问题社区帖子。
注意事项
您可以使用 from 多次联接同一表
如果单个表包含不同类型的实体,则可以将视图多次联接到探索中。为此,您需要使用 from 参数。假设您有一个 order 探索,并且需要将 person 视图联接到该探索两次:一次针对客户,一次针对客户服务代表。您可以执行以下操作:
explore: order {
join: customer {
from: person
sql_on: ${order.customer_id} = ${customer.id} ;;
}
join: representative {
from: person
sql_on: ${order.representative_id} = ${representative.id} ;;
}
}
尽可能不在联接中应用业务逻辑
Looker 的标准联接方法是尽可能使用 LEFT JOIN。如果您发现自己正在执行以下操作,请考虑采用其他方法:
explore: member_event {
from: event
always_join: [member]
join: member {
sql_on: ${member_event.member_id} = ${member.id} ;;
type: inner
}
}
在此示例中,我们创建了一个仅查看与已知会员相关联的事件的探索。不过,在 Looker 中执行此操作的首选方式是使用 LEFT JOIN 将事件数据和会员数据合并在一起,如下所示:
explore: event {
join: member {
sql_on: ${event.member_id} = ${member.id} ;;
}
}
然后,您可以创建一个维度,并将其设置为 yes 或 no(如果您只想查看会员活动),如下所示:
dimension: is_member_event {
type: yesno
sql: ${member.id} IS NOT NULL ;;
}
这种方法更可取,因为它可以让用户灵活地选择查看所有活动还是仅查看会员活动。您没有通过联接强制他们仅查看成员事件。
如果不使用对称聚合,请避免导致扇出的联接
本部分仅适用于不支持对称聚合的数据库方言。请参阅此页面上常见挑战部分中有关对称聚合的讨论,以确定您的方言是否支持对称聚合。
如果您的数据库方言不支持对称聚合,则应避免导致扇出的联接。换句话说,一般应避免在探索和视图之间建立一对多关系的联接。相反,应在派生表中聚合视图中的数据,以便与探索建立一对一关系,然后将该派生表联接到探索中。
社区帖子 SQL 扇出的问题中进一步说明了这一重要概念。