

Mit dem Gemini Distillation Service (Destillation) können Nutzer ein kleineres, effizienteres „Schülermodell“ trainieren, das die Ausgaben und Begründungsmuster eines größeren, leistungsfähigeren „Lehrermodells“ verwendet. Obwohl Frontier-Modelle den neuesten Stand der KI darstellen, können sie für bestimmte Anwendungsfälle in Unternehmen überdimensioniert sein. Die Destillation schließt diese Lücke und ermöglicht Effizienz auf Produktionsniveau (geringere Latenz und Kosten), während kleinere Modelle ein höheres Maß an Begründung erreichen können.
Im Gegensatz zur standardmäßigen überwachten Feinabstimmung (Supervised Fine-Tuning, SFT), bei der nur die endgültige Textausgabe verwendet wird, nutzt die Destillation Folgendes:
- Antworten der Lehrkraft: Die endgültige Textausgabe.
- Rohdaten: Die internen Begründungspfade, die vom Lehrer modell generiert werden.
Unterstützte Modelle
Die folgenden Modelle werden für die Destillation während des Vorabzugriffs unterstützt:
- Lehrermodell:
gemini-3.1-pro - Schülermodell:
gemini-2.5-flash
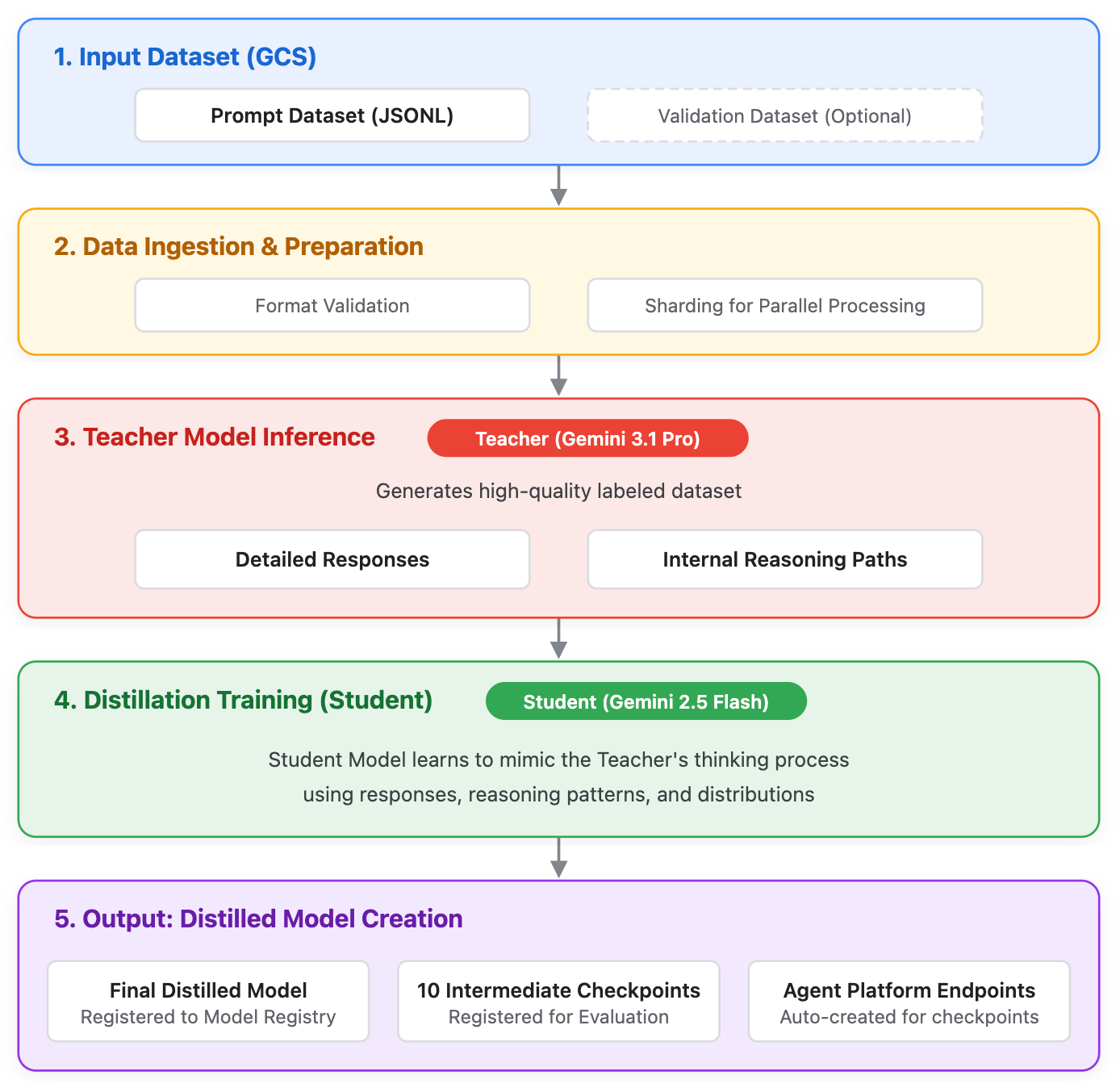
Abbildung 1 Systemdarstellung der Funktionsweise des Gemini Distillation Service
Geeignete Anwendungsfälle
Die Destillation wird in den folgenden Szenarien gegenüber Standard-Prompts oder der überwachten Feinabstimmung (SFT) empfohlen:
- Anwendungen mit hohem Volumen und hoher Latenzempfindlichkeit: Wenn Ihre Anwendung die Begründungsfunktionen eines Modells der Pro-Stufe erfordert, aber strenge Latenz-SLAs oder Budgetbeschränkungen eingehalten werden müssen, die ein Modell der Flash-Stufe erfordern.
- Fehlende Ground-Truth-Daten (SFT ist nicht möglich): Wenn Sie ein großes Dataset mit Nutzer-Prompts oder ‑Abfragen haben, aber nicht die Ressourcen, um hochwertige Ground-Truth-Antworten manuell zu labeln oder zu generieren, die für die standardmäßige SFT erforderlich sind.
- Komplexe Begründungsaufgaben: Aufgaben mit mehrstufiger Logik, Zusammenfassung hochtechnischer Dokumente oder komplexe Programmieraufgaben, bei denen das Flash -Basismodell Schwierigkeiten hat, das Pro-Modell jedoch erfolgreich ist.
- Erhebliche Leistungsunterschiede: Wenn das Lehrermodell das Schülermodell bei Ihrer spezifischen Aufgabe deutlich übertrifft und somit eine klare Wissenslücke besteht, die während der Destillation geschlossen werden kann.
Voraussetzungen und Projekteinrichtung
Bevor Sie einen Destillationsjob starten, muss Ihre Google Cloud Umgebung richtig konfiguriert sein:
- Zugriff auf die Zulassungsliste beantragen: Prüfen Sie, ob Ihre Google Cloud Projekt-ID der Zulassungsliste für den Vorabzugriff auf den Gemini Distillation Service hinzugefügt wurde. Wenden Sie sich an Ihren Google-Vertriebsmitarbeiter, um Ihr Projekt der Zulassungsliste hinzuzufügen.
- API aktivieren: Aktivieren Sie die Agent Platform API in Ihrem Google Cloud Projekt.
- IAM-Rollenberechtigungen festlegen: Sie benötigen die
IAM-Rolle „Administrator für die Agent Platform“ (
roles/aiplatform.admin) . - Region festlegen: Destillationsjobs müssen in der
us-central1Region ausgeführt werden.
Dataset vorbereiten
Ein wichtiges Feature dieses Dienstes ist die Verwendung von Datasets mit Prompts. Da das Lehrermodell die Zielausgaben während des Destillationsprozesses generiert, müssen Sie die erwarteten Antworten nicht angeben.
Anforderungen an Datasets
Datasets müssen im JSON Lines-Format (JSONL) vorliegen und in einem Cloud Storage-Bucket gespeichert sein. Jeder Eintrag muss zusätzlich zu den folgenden Anforderungen dem Format für Gemini-Abstimmungsdatasets entsprechen:
- Systemanweisungen: Sie können ein optionales
systemInstructionFeld (mit der Rolle „system“) einfügen, um System-Prompts zu definieren. - Eingabe: Das Feld „contents“ (mit der Rolle „user“) ist für die primäre Eingabe erforderlich.
Prompts mit mehreren Turns: Sie können zwischen den Rollen „user“ und „model“ wechseln, sofern der letzte Eintrag in der Sequenz „user“ ist.
Hier sind zwei Beispiele für dataset.jsonl-Dateien:
{
"contents": [
{
"role": "user",
"parts": [
{
"text": "You're the artist here. Choose as many strands of thread as you like, as long as you're using three or more. Go for color combinations that you think would make a pretty pattern. Get creative! If you only use one color of thread, you won't be able to create a pattern.\n\nProvide a summary of the article in two or three sentences:\n\n"
}
]
}
]
},
{
"contents": [
{
"role": "user",
"parts": [
{
"text": "You're the artist here. Choose as many strands of thread as you like, as long as you're using three or more. Go for color combinations that you think would make a pretty pattern. Get creative! If you only use one color of thread, you won't be able to create a pattern.\n\nProvide a summary of the article in two or three sentences:\n\n"
}
]
},
{
"role": "model",
"parts": [
{
"text": "Choose several strands of embroidery thread in a variety of colors."
}
]
},
{
"role": "user",
"parts": [
{
"text": "You will need one egg (raw or hard boiled but hard boiled is best) and one spoon for each person participating in the race. You might even like to use dyed Easter eggs as something special for Easter. It's best to have this race on grass or some other soft surface, to give dropped eggs a chance!"
}
]
}
]
}
Best Practices
Beachten Sie beim Erstellen Ihres Datasets die folgenden Richtlinien:
- Größe: Für eine spürbare Qualitätsverbesserung werden mindestens 1.000 Beispiele empfohlen.
- Vielfalt: Achten Sie darauf, dass Ihre Prompts die Grenzfälle und unterschiedlichen Längen abdecken, die im Produktions-Traffic zu erwarten sind.
Destillationsanfrage konfigurieren
Für einen Destillationsjob müssen sowohl das Generierungsverhalten des Lehrermodells als auch die Trainings-Hyperparameter des Schülermodells konfiguriert werden.
Generierungsverhalten des Lehrermodells konfigurieren
Sie müssen definieren, wie das Lehrermodell auf Ihr Dataset reagiert. Die Qualität des Schülermodells hängt direkt von der Qualität der Ausgabe des Lehrermodells ab. Legen Sie candidateCount fest, um das Generierungsverhalten des Lehrermodells zu konfigurieren:
candidateCount: Die Anzahl der zu generierenden Antwortvarianten. Beispiel:4. Bereich[1, 5]). Wenn er in der Anfrage nicht angegeben ist, wird ein Standardwert von4verwendet.
Wenn in der Anfrage nichts angegeben ist, wird der Standardwert `4` verwendet.
Hyperparameter für die Destillation festlegen Die Hyperparameter für die Destillation steuern den Trainingsprozess des Schülermodells.
Weitere Informationen zu Hyperparametern in der Gemini Enterprise Agent Platform finden Sie im Abschnitt „Abstimmungsjob erstellen“ des Leitfadens zur überwachten Feinabstimmung.
epochCount: Die Anzahl der Iterationen des Schülermodells über den Datensatz. `epochCount`: Die Anzahl der Durchläufe des Datasets durch das Schülermodell.20Bereich[1, 100]). Falls nicht angegeben, wird ein Standardwert von4verwendet.- `
learningRateMultiplier`: Modifiziert die Basis-Lernrate des Studenten Modells. (Beispiel:2.0. `learningRateMultiplier`: Ändert die Basis-Lernrate des Schülermodells. Source: Range[0.25, 4]). If not specified, a default value of1is used. Translation: Bereich[0.25, 4]). Falls nicht angegeben, wird ein Standardwert von1verwendet.
Beispiel: `2.0`.
Während des Vorabzugriffs können Sie Destillationsjobs über die REST-Version der Agent Platform API einreichen und überwachen. Sie können einen neuen Destillationsjob initiieren oder eine kontinuierliche Abstimmung auf einem bereits destillierten Modell-Checkpoint durchführen.
Destillationsjob starten
Erstellen Sie eine JSON-Datei mit dem Namen request.json, die Ihre Jobkonfiguration enthält. In
den folgenden Beispiel ist die Generierungskonfiguration des Lehrers in
das hyperParameters Feld verschachtelt:
{
"description": "Distillation testing job.",
"baseModel": "gemini-2.5-flash",
"tunedModelDisplayName": "flash-distillation-run-1",
"distillationSpec": {
"promptDatasetUri": "gs://your-bucket/path/to/prompt_dataset.jsonl",
"validationDatasetUri": "",
"base_teacher_model": "gemini-3.1-pro-preview",
"hyperParameters": {
"epochCount": "20",
"learningRateMultiplier": 2.0,
"generation_config": {
"candidateCount": 5
}
}
}
}
Neuen Destillationsjob erstellen mit curl
curl -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
https://us-central1-aiplatform.googleapis.com/v1beta1/projects/PROJECT_ID/locations/us-central1/tuningJobs \
-d @request.json
Erstellen Sie eine JSON-Datei mit dem Namen `request.json`, die Ihre Jobkonfiguration enthält.
Wenn Sie das Tuning von einem zuvor destillierten Modell-Checkpoint fortsetzen möchten,
fügen Sie den Block preTunedModel in Ihre Datei request.json ein. Senden Sie den Job mit `curl`: Kontinuierliche Abstimmung durchführen
Wenn Sie die Abstimmung ab einem zuvor destillierten Modell-Checkpoint fortsetzen möchten, fügen Sie den Block `preTunedModel` in Ihre Datei `request.json` ein.
{
"description": "Continuous distillation testing job.",
"preTunedModel": {
"tunedModelName": "projects/YOUR_PROJECT_ID/locations/us-central1/models/PRETUNED_MODEL_ID@1",
"checkpointId": "1",
"baseModel": "gemini-2.5-flash"
},
"tunedModelDisplayName": "flash-distillation-continuous",
"distillationSpec": {
"promptDatasetUri": "gs://your-bucket/path/to/prompt_dataset.jsonl",
"validationDatasetUri": "",
"base_teacher_model": "gemini-3.1-pro-preview",
"hyperParameters": {
"epochCount": "20",
"learningRateMultiplier": 2.0,
"generation_config": {
"candidateCount": 5,
}
}
}
}
Senden Sie die Nutzlast mit curl:
curl -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
https://us-central1-aiplatform.googleapis.com/v1beta1/projects/PROJECT_ID/locations/us-central1/tuningJobs \
-d @request.json
Zuvor überwacht abgestimmte Modell-Checkpoints (auch mit demselben Schülermodell) werden nicht unterstützt.
Die Übermittlungsantwort gibt einen Jobnamen zurück, der Ihre
JOB_ID enthält. Sie können den Status Ihres Jobs
(state, Fehler und endgültige Hyperparameter) überprüfen, indem Sie eine GET-Anfrage senden:
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
https://us-central1-aiplatform.googleapis.com/v1beta1/projects/PROJECT_ID/locations/us-central1/tuningJobs/JOB_ID
Sie können den Fortschritt auch visuell in der Google Cloud Console überwachen, indem Sie zu Agent Platform > Abstimmung navigieren und die
us-central1 Region auswählen.
Für diese Early-Access-Version weist die Agent Platform Console-Benutzeroberfläche die folgenden bekannten Einschränkungen auf:
- Fortschritt der Lehrersammlung: Es gibt kein Fortschritts-Widget für den Lehrermodell-Sampling-Prozess. Auch wenn der Status "Running Prepare for tuning" lautet, wird der Job im Hintergrund normal ausgeführt.
- Diagramme zur Feinabstimmung von Studentenmodellen: Während der Feinabstimmung von Studentenmodellen stellt die Benutzeroberfläche Diagramme für die Verlustkurve und die Gesamtzahl der Trainings-Text-Tokens bereit.
- Checkpoint-Tabelle: Die Benutzeroberfläche zeigt eine Tabelle mit Zwischen-Checkpoints und Links zum generierten Agent Platform-Vorhersage-Endpunkt für die Auswertung. Obwohl der Status „Wird ausgeführt: Vorbereitung für die Abstimmung“ angezeigt wird, wird der Job im Hintergrund normal ausgeführt.
**Diagramme zur Abstimmung des Schülermodells** : Während der Abstimmungsphase des Schülermodells enthält die Benutzeroberfläche Diagramme für die Verlustkurve und die Gesamtzahl der Text-Tokens für das Training.
**Checkpoint-Tabelle** : Die Benutzeroberfläche zeigt eine Tabelle mit Zwischen-Checkpoints und Links zum generierten Agent Platform-Vorhersageendpunkt zur Bewertung an.
Verwenden Sie die Google Cloud Konsole, und ändern Sie die folgende URL:
https://console.cloud.google.com/agent-platform/tuning/managed?project=YOUR_PROJECT_ID&vertex_ai_region=us-central1Ersetzen Sie YOUR_PROJECT_ID durch Ihre Projekt-ID.
Führen Sie
curlaus, um einen POST-Request zum Abbrechen des Jobs zu senden:curl -X POST \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" \ https://us-central1-aiplatform.googleapis.com/v1beta1/projects/YOUR_PROJECT_ID/locations/us-central1/tuningJobs/YOUR_JOB_ID:cancelVerwenden Sie die Console und ändern Sie die folgende URL:
- Ersetzen Sie
YOUR_PROJECT_IDdurch Ihre Projekt-ID. YOUR_JOB_IDmit Ihrer Job-ID.
- Ersetzen Sie
Ersetzen Sie Folgendes:
Nachdem der Destillationsjob erfolgreich abgeschlossen wurde, wird das neue Studentenmodell automatisch in der Gemini Enterprise Agent Platform Model Registry registriert, und ein oder mehrere dedizierte Endpunkte werden erstellt, um Vorhersagen zu liefern. To evaluate the result, you locate the endpoint, send a prediction request, and finally evaluate.
Ergebnis bewerten
Senden Sie die folgende GET-Anfrage, um den Status des Abstimmungsjobs anzuzeigen.
curl -X GET \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" \ https://us-central1-aiplatform.googleapis.com/v1beta1/projects/YOUR_PROJECT_ID/locations/us-central1/tuningJobs/YOUR_JOB_IDUm das Ergebnis zu bewerten, suchen Sie den Endpunkt, senden eine Vorhersageanfrage und führen dann die Bewertung durch.
YOUR_PROJECT_IDmit Ihrer Projekt-ID.YOUR_JOB_IDmit Ihrer Job-ID.
Abgeschlossene Jobs zeigen ein Feld
endpointan, das im ObjekttunedModelverschachtelt ist. Extrahieren Sie dieENDPOINT_IDaus dem Ende der zurückgegebenen Pfadzeichenfolge (z. B.projects/.../endpoints/YOUR_ENDPOINT_ID). Notieren Sie sich die Endpunkt-ID.Stellen Sie sicher, dass der Optimierungsauftrag erfolgreich abgeschlossen wurde, da der Endpunkt nicht verfügbar ist, solange der Optimierungsauftrag noch ausgeführt wird oder fehlgeschlagen ist. Wenn das Feld
endpointfehlt, debuggen Sie den Tuning-Job, indem Sie die Schlüsselstateodererrordes Jobs anzeigen.Erstellen Sie eine JSON-Nutzlastanforderung mit dem Namen
generate_content_request.json, die Ihre Eingabeaufforderung enthält:{ "contents": { "role": "user", "parts": [ { "text": "hi, say something" } ] } }Achten Sie darauf, dass der Abstimmungsjob erfolgreich abgeschlossen wurde, da der Endpunkt nicht verfügbar ist, solange der Abstimmungsjob noch ausgeführt wird oder fehlgeschlagen ist.
curl -X POST \ -H "Content-Type: application/json" \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ https://us-central1-aiplatform.googleapis.com/v1beta1/projects/YOUR_PROJECT_ID/locations/us-central1/endpoints/YOUR_ENDPOINT_ID:generateContent \ -d @generate_content_request.jsonWenn das Feld `endpoint` fehlt, beheben Sie Fehler im Abstimmungsjob, indem Sie die Schlüssel `state` oder `error` des Jobs aufrufen.
YOUR_PROJECT_ID: Ihre Projekt-ID.YOUR_JOB_ID: Ihre Job-ID.ENDPOINT_ID: Ihre Endpunkt-ID.
`YOUR_PROJECT_ID`: Ihre Projekt-ID.
Führen Sie einen Holdout-Testsatz mit Eingabeaufforderungen, die nicht in den Trainingsdaten enthalten sind, für Ihr neu destilliertes Modell aus.
Vergleichen Sie die Ausgaben mit dem Basismodell
gemini-2.5-flash, um die Qualitätsverbesserungen zu messen.So bewerten Sie die Ergebnisse: Vergleichen Sie die Ergebnisse mit dem
gemini-3.1-proModell, um zu bestimmen, wie genau der Student die Argumentation des Lehrers wiedergibt.
Führen Sie einen Holdout-Testsatz mit Prompts aus, die nicht in den Trainingsdaten enthalten sind, für Ihr neu destilliertes Modell aus.
Vergleichen Sie die Ausgaben mit dem Basismodell `gemini-2.5-flash`, um die Qualitätsverbesserungen zu messen.
Vergleichen Sie die Ausgaben mit dem Modell `gemini-3.1-pro`, um zu ermitteln, wie genau das Schülermodell die Begründung des Lehrermodells nachahmt.
- Beschränkungen:
- In der folgenden Tabelle werden die Beschränkungen für die Destillation beschrieben: unterstützten Modelle
- Für die Destillation gelten die folgenden Beschränkungen:
- Modellbeschränkungen:
- Unterstützte Modelle ansehen
- **Dataset-Beschränkungen** :
- Kontextfenster-Spezifikationen:
- Die maximale Kapazität des Trainingssets beträgt 50.000 Beispiele. Destillationsaufträge werden beendet, wenn mehr als 10% der bereitgestellten Einträge diesen festgelegten Schwellenwert überschreiten.
- Die Stichprobenziehung des Lehrermodells ist auf eine maximale Ausgabe von 24.000 Token begrenzt. In Fällen,in denen das Lehrermodell mehr als 24.000 Token generiert, wird der Inhalt auf dieses Limit gekürzt, was die Leistung des Schülermodells beeinträchtigen kann.
- Modalität: Beschränkt auf textbasierte Daten. Das Sampling des Lehrermodells ist auf eine maximale Ausgabe von 24.000 Tokens begrenzt.
- Modellbeschränkungen:
- Konfigurations- und Hyperparameterbeschränkungen
- **Modalität** : Beschränkt auf textbasierte Daten. Halten Sie sich bei der Definition der distillationSpec
und der zugehörigen hyperParameters an die folgenden Grenzen:
- Multimodale Eingaben wie Videos, Bilder oder Funktionsaufrufe werden nicht unterstützt.
epochCount: Beschränkungen für Konfiguration und HyperparameterlearningRateMultipliermuss im Gleitkommabereich von0.25bis4.0liegen.
- **Modalität** : Beschränkt auf textbasierte Daten. Halten Sie sich bei der Definition der distillationSpec
und der zugehörigen hyperParameters an die folgenden Grenzen:
- Verschlüsselung: CMEK ist für Destillationsaufgaben mit den eigenen Modellen von Google nicht verfügbar. `epochCount`: Beschränkt auf einen ganzzahligen Wert zwischen 1 und 100.
`learningRateMultiplier`: Die Werte müssen im Gleitkomma-Bereich von `0.25` bis `4.0` liegen.
Wenn Sie daran interessiert sind, mit dem Gemini Distillation Service zu experimentieren, wenden Sie sich an unser Tuning Service-Team unter cloud-ai-tuning-service-support@google.com , um Zugriff und Projekt-Allowlisting anzufordern.
Um eine optimale Leistung und Ressourcenverwaltung zu gewährleisten, empfehlen wir die Erstellung eines dedizierten Google Cloud Projekts für Ihre Destillationsaufgaben. Wenn Sie sich an unser Team wenden, geben Sie Ihre Projekt-ID oder Projektnummer an, um den Zulassungslistenprozess zu beschleunigen.
Wenn Sie mit dem Gemini Distillation Service experimentieren möchten, wenden Sie sich an unser Tuning Service-Team unter cloud-ai-tuning-service-support@google.com, um Zugriff und die Zulassung Ihres Projekts zu beantragen.
Für optimale Leistung und Ressourcenverwaltung empfehlen wir, ein dediziertes Projekt für Ihre Destillationsaufgaben zu erstellen.
Kapazität: Projekte, die kürzlich zu unserer Zulassungsliste hinzugefügt wurden, erhalten ein standardmäßiges gleichzeitiges Kontingent von 4. Kontingente und Zugriffsrichtlinien
Es gelten die folgenden Kontingente und Zugriffsrichtlinien: