
了解结果
Enterprise Knowledge Graph 会针对每个作业将结果写入新的 BigQuery 表中。这是作业执行时的数据快照。默认情况下,每个作业都会为每个实体聚类生成一个随机 cluster_id。不过,如果您希望在不同的作业运行之间保持 ID 的稳定性,请使用 previous BigQuery result table 高级选项。
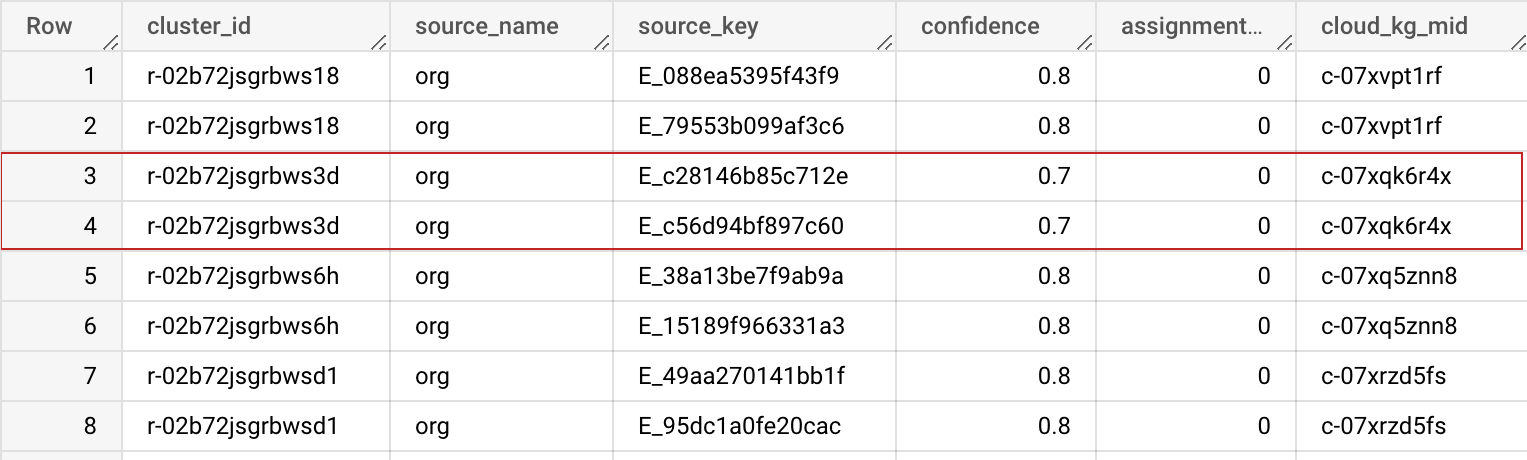
输出架构
| 字段名称 | 类型 | 说明 |
|---|---|---|
| cluster_id | STRING | 此聚类 ID 是分配给相应记录聚类的私有知识图谱机器 ID (MID)。可用于唯一标识数据集中的记录。您可以在“高级选项”中使用之前的 BigQuery 表,以确保此 cluster_id 在多次运行中保持稳定一致。 |
| source_name | STRING | 输入配置中指定的来源名称,以帮助您联接数据集。 |
| source_key | STRING | 源表中的唯一键,可帮助您联接数据集。 |
| 置信度 | FLOAT | 用于确定这些记录属于相应聚类的程度的置信度得分。 |
| assignment_age | INTEGER | 在不同作业之间用于内部稳定 cluster_id (MID)。 |
| cloud_kg_mid | STRING | Google Cloud 知识图谱关联实体的 MID。您可以将此 MID 用作永久 ID,也可以通过 Cloud Knowledge Graph API 查找更多详细信息。 |
使用 SQL 将数据集联接在一起
Enterprise Knowledge Graph 会按聚类 ID 对实体进行分组。查看结果的最简单方法是使用聚类 ID 对结果进行“分组依据”。以下示例通过将输出表与原始表联接来执行快速健全性检查。
# get all entity clusters
SELECT distinct (cluster_id) FROM `ekg-test.<dataset>.clusters_9425187210682344597` order by cluster_id LIMIT 1000;
# join data with original table
SELECT confidence, RS., SRC. FROM `ekg-test.<dataset>.clusters_9425187210682344597` as RS join `ekg-api-test.demo.organization` as SRC
on RS.source_key = SRC.source_key where cluster_id = "r-02b72jsgrbws18";
此实体聚类表示属于同一聚类的两条不同记录。此相同的 cluster_id 表示应联接并合并这两条记录。

衡量成效
成对
精确率:被错误识别为相似的假正例(可通过人工检查轻松检测到)的相异实体的比率。
召回率:未被识别为假负例或难以检测的类似实体的比率。
聚类 V-measure
聚类 V-measure:(1 + beta)* 同质性 * 完整性 /(beta * 同质性 + 完整性),其中 beta=1。
聚类同质性:具有属于同一实体的实体的聚类所占的比率。
聚类完整性:所有属于同一实体的实体都被放置在同一聚类中的聚类所占的比例。