
結果を理解する
Enterprise Knowledge Graph は、ジョブごとに結果を新しい BigQuery テーブルに書き込みます。これは、ジョブの実行時のデータのスナップショットです。デフォルトでは、すべてのジョブでエンティティ クラスタごとにランダムな cluster_id が生成されます。ただし、ジョブ実行間で ID を安定させたい場合は、previous BigQuery result table 詳細オプションを使用します。
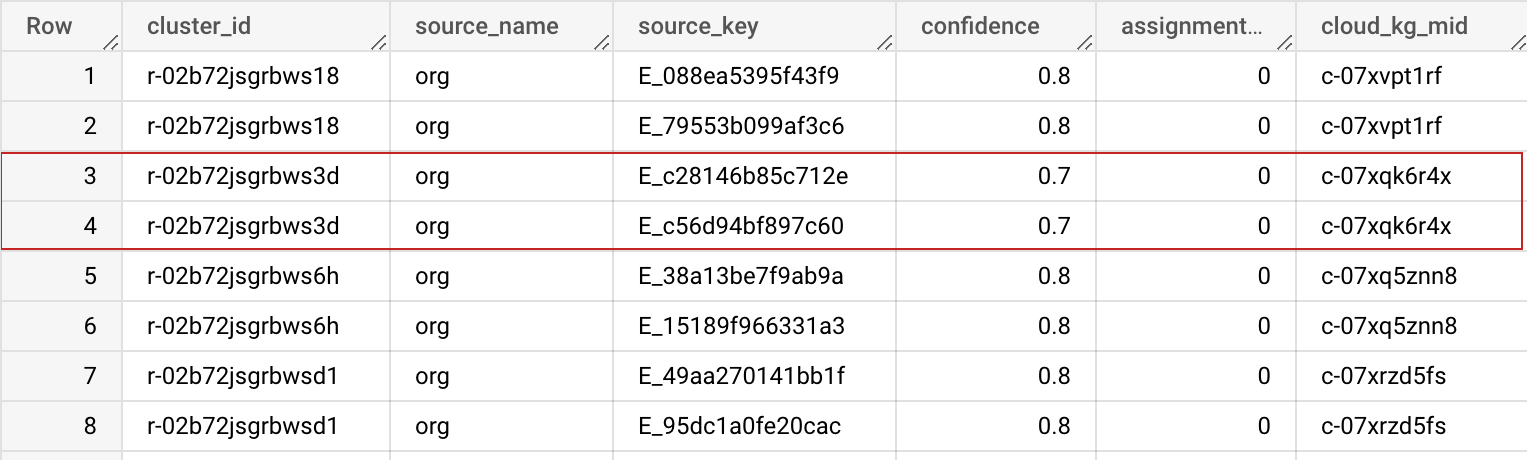
出力スキーマ
| フィールド名 | タイプ | 説明 |
|---|---|---|
| cluster_id | STRING | このクラスタ ID は、このレコードのクラスタに割り当てられた限定公開のナレッジグラフ マシン ID(MID)です。データセット内のレコードを一意に識別するために使用できます。[詳細オプション] の [以前の BigQuery テーブル] を使用すると、複数の実行でこの cluster_id を安定して一貫性を保つことができます。 |
| source_name | STRING | データセットを結合する際に役立つ、入力構成で指定されたソース名。 |
| source_key | STRING | データセットを結合するために使用する、ソーステーブルの一意のキー。 |
| confidence | FLOAT | これらのレコードがこのクラスタに属する度合いを決定する信頼度スコア。 |
| assignment_age | INTEGER | さまざまなジョブで cluster_id(MID)を安定させるために内部で使用されます。 |
| cloud_kg_mid | STRING | Google Cloud ナレッジグラフのリンクされたエンティティの MID。この MID を永続 ID として使用したり、Cloud ナレッジグラフ API から追加の詳細情報を検索したりできます。 |
SQL を使用してデータセットを結合する
Enterprise Knowledge Graph は、クラスタ ID でグループ化されたエンティティを出力します。結果を表示する最も簡単な方法は、クラスタ ID を使用して結果をグループ化することです。次の例では、出力テーブルと元のテーブルを結合して、簡単な健全性チェックを実行します。
# get all entity clusters
SELECT distinct (cluster_id) FROM `ekg-test.<dataset>.clusters_9425187210682344597` order by cluster_id LIMIT 1000;
# join data with original table
SELECT confidence, RS., SRC. FROM `ekg-test.<dataset>.clusters_9425187210682344597` as RS join `ekg-api-test.demo.organization` as SRC
on RS.source_key = SRC.source_key where cluster_id = "r-02b72jsgrbws18";
このエンティティ クラスタは、同じクラスタに属する 2 つの異なるレコードを表します。この同じ cluster_id は、これらの 2 つのレコードを結合して統合する必要があることを示します。

成果の測定
ペアワイズ
適合率: 類似していると誤って識別された異なるエンティティの割合(手動検査で検出されやすい)。
再現率: 偽陰性として識別されなかった、または検出が困難な類似エンティティの比率。
クラスタ V 測定
クラスタ V 測定: (1 + ベータ) * 同質性 * 完全性 / (ベータ * 同質性 + 完全性)。ここで、ベータ=1 です。
クラスタの同質性: 同じエンティティに属するエンティティを含むクラスタの比率。
クラスタの完全性: 同じエンティティに属するすべてのエンティティが同じクラスタに配置されているクラスタの比率。