
Comprende el resultado
Enterprise Knowledge Graph escribe los resultados en una nueva tabla de BigQuery para cada trabajo. Esta es una instantánea de los datos en el momento en que se ejecuta el trabajo. De forma predeterminada, cada trabajo genera un cluster_id aleatorio para cada clúster de entidades. Sin embargo, si quieres que el ID se mantenga estable entre diferentes ejecuciones de trabajos, usa la opción avanzada previous BigQuery result table.
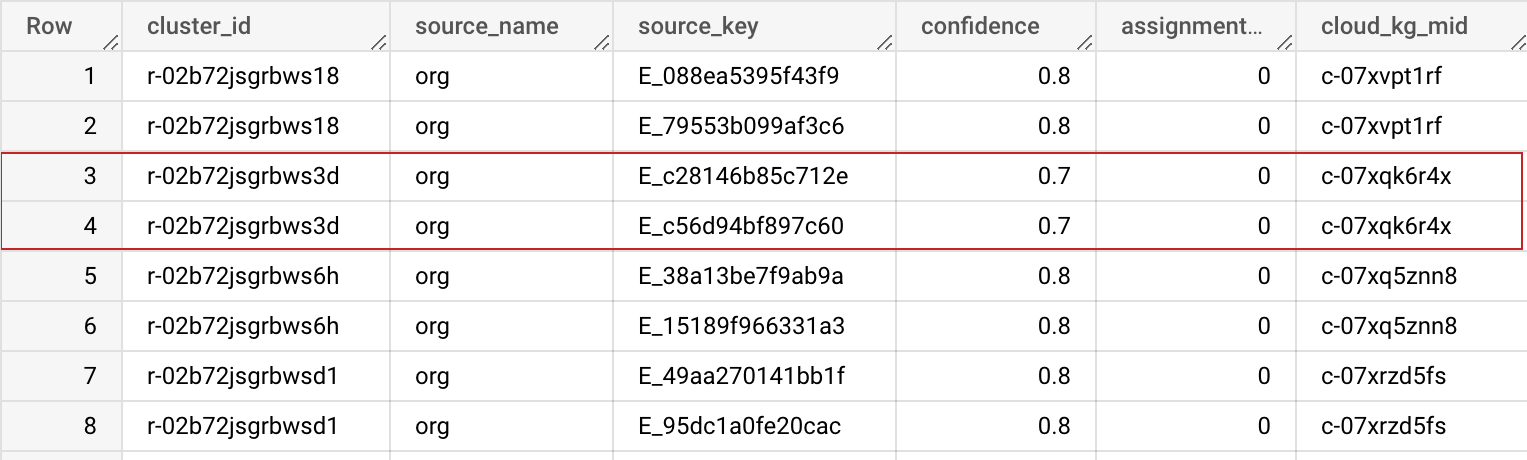
Esquema de salida
| Nombre del campo | Tipo | Descripción |
|---|---|---|
| cluster_id | STRING | Este ID de clúster es un ID de máquina (MID) privado del gráfico de conocimiento asignado a este clúster de registros. Se puede usar para identificar de forma única el registro en tu conjunto de datos. Puedes usar la tabla de BigQuery anterior en las opciones avanzadas para mantener este cluster_id estable y coherente en varias ejecuciones. |
| source_name | STRING | Es el nombre de la fuente especificado en la configuración de entrada para ayudarte a unir conjuntos de datos. |
| source_key | STRING | Es la clave única de la tabla de origen que te ayuda a unir el conjunto de datos. |
| confianza | FLOAT | Es la puntuación de confianza que determina qué tan firmemente pertenecen estos registros a este clúster. |
| assignment_age | INTEGER | Se usa de forma interna para la estabilización de cluster_id (MID) en diferentes trabajos. |
| cloud_kg_mid | STRING | Es el MID de la entidad vinculada del Gráfico de conocimiento de Google Cloud. Puedes usar este MID como tu ID permanente o buscar detalles adicionales en la API de Cloud Knowledge Graph. |
Usa SQL para unir el conjunto de datos
Enterprise Knowledge Graph agrupa las entidades por ID de clúster. La forma más sencilla de ver el resultado es usar el ID del clúster para "agrupar por" tu resultado. En el siguiente ejemplo, se realiza una verificación rápida de coherencia uniendo la tabla de resultado con la tabla original.
# get all entity clusters
SELECT distinct (cluster_id) FROM `ekg-test.<dataset>.clusters_9425187210682344597` order by cluster_id LIMIT 1000;
# join data with original table
SELECT confidence, RS., SRC. FROM `ekg-test.<dataset>.clusters_9425187210682344597` as RS join `ekg-api-test.demo.organization` as SRC
on RS.source_key = SRC.source_key where cluster_id = "r-02b72jsgrbws18";
Este clúster de entidades representa dos registros diferentes que pertenecen al mismo clúster. El mismo cluster_id indica que estos dos registros se deben unir y combinar.

Mida el éxito
Por pares
Precisión: Es la proporción de entidades distintas identificadas incorrectamente como falsos positivos similares (más fáciles de detectar con una inspección manual).
Recuperación: Es la proporción de entidades similares que no se identifican como falsos negativos o que son más difíciles de detectar.
Medida V del clúster
Medida V del clúster: (1 + beta) * homogeneidad * integridad / (beta * homogeneidad + integridad), donde beta=1.
Homogeneidad del clúster: Es la proporción de clústeres que tienen entidades que pertenecen a la misma entidad.
Integridad del clúster: Es la proporción de clústeres en los que todas las entidades que pertenecen a la misma entidad se colocan en el mismo clúster.