
Ergebnis verstehen
Enterprise Knowledge Graph schreibt die Ergebnisse für jeden Job in eine neue BigQuery-Tabelle. Dies ist ein Snapshot der Daten zum Zeitpunkt der Ausführung des Jobs. Standardmäßig wird für jeden Entitätscluster ein zufälliger cluster_id generiert. Wenn Sie jedoch möchten, dass die ID bei verschiedenen Jobläufen stabil bleibt, verwenden Sie die erweiterte Option previous BigQuery result table.
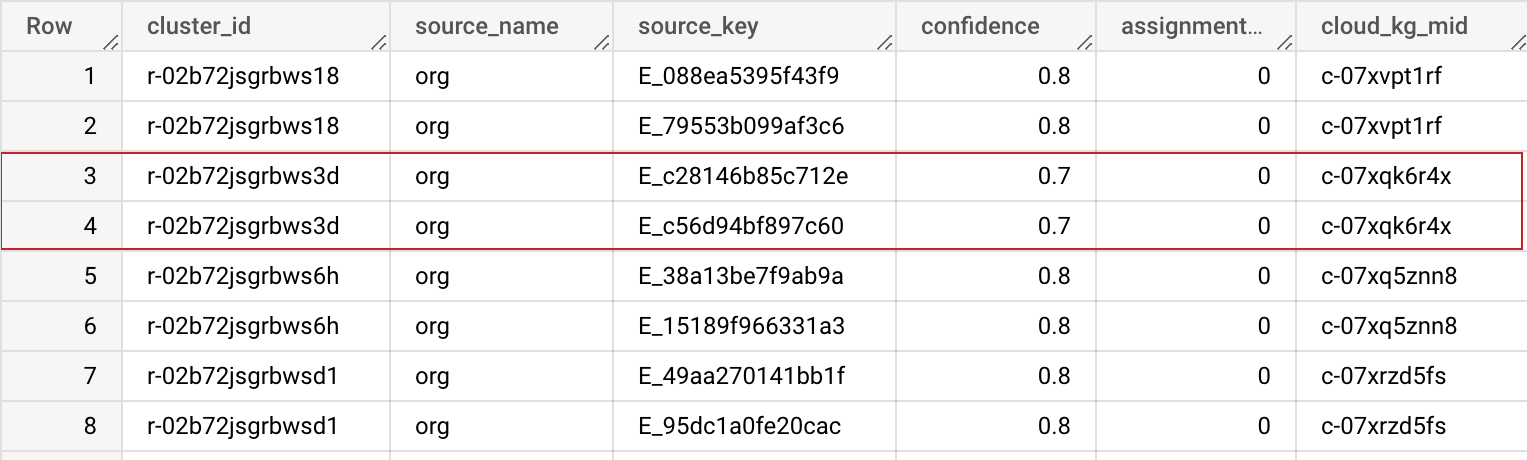
Ausgabeschema
| Feldname | Typ | Beschreibung |
|---|---|---|
| cluster_id | STRING | Diese Cluster-ID ist eine private Knowledge Graph-MID (Machine ID), die diesem Datensatzcluster zugewiesen ist. Damit kann der Datensatz in Ihrem Dataset eindeutig identifiziert werden. Sie können die vorherige BigQuery-Tabelle in den erweiterten Optionen verwenden, um cluster_id über mehrere Ausführungen hinweg stabil und konsistent zu halten. |
| source_name | STRING | Der in der Eingabekonfiguration angegebene Quellname, mit dem Sie Datasets zusammenführen können. |
| source_key | STRING | Der eindeutige Schlüssel in Ihrer Quelltabelle, mit dem Sie Datasets zusammenführen können. |
| Konfidenz | FLOAT | Konfidenzwert, der bestimmt, wie stark diese Datensätze zu diesem Cluster gehören. |
| assignment_age | INTEGER | Wird intern für die Stabilisierung von „cluster_id“ (MID) über verschiedene Jobs hinweg verwendet. |
| cloud_kg_mid | STRING | Die MID des verknüpften Google Cloud Knowledge Graph-Elements. Sie können diese MID als Ihre permanente ID verwenden oder zusätzliche Details über die Cloud Knowledge Graph API abrufen. |
Dataset mit SQL zusammenführen
Im Enterprise Knowledge Graph werden Entitäten nach Cluster-ID gruppiert. Am einfachsten lässt sich das Ergebnis ansehen, indem Sie die Cluster-ID verwenden, um das Ergebnis zu gruppieren. Im folgenden Beispiel wird eine schnelle Plausibilitätsprüfung durchgeführt, indem die Ausgabetabelle mit der Originaltabelle verknüpft wird.
# get all entity clusters
SELECT distinct (cluster_id) FROM `ekg-test.<dataset>.clusters_9425187210682344597` order by cluster_id LIMIT 1000;
# join data with original table
SELECT confidence, RS., SRC. FROM `ekg-test.<dataset>.clusters_9425187210682344597` as RS join `ekg-api-test.demo.organization` as SRC
on RS.source_key = SRC.source_key where cluster_id = "r-02b72jsgrbws18";
Dieser Entitätscluster stellt zwei verschiedene Datensätze dar, die zum selben Cluster gehören. Dasselbe cluster_id signalisiert, dass diese beiden Datensätze zusammengeführt werden sollten.

Erfolg messen
Paarweise
Präzision: Verhältnis von einzelnen Entitäten, die fälschlicherweise als ähnliche Falsch-Positive identifiziert wurden (leichter durch manuelle Überprüfung zu erkennen).
Recall: Verhältnis ähnlicher Entitäten, die nicht als falsch negativ oder schwerer zu erkennen eingestuft werden.
V-Maß für Cluster
V-Messwert für Cluster: (1 + Beta) * Homogenität * Vollständigkeit / (Beta * Homogenität + Vollständigkeit), wobei Beta=1.
Cluster-Homogenität: Verhältnis von Clustern mit Entitäten, die zur selben Entität gehören.
Cluster-Vollständigkeit: Verhältnis von Clustern, in denen alle Entitäten, die zur selben Entität gehören, im selben Cluster platziert werden.