
本快速入门为您介绍实体调和 API。在本快速入门中,您将使用 Google Cloud 控制台设置Google Cloud 项目和授权,创建架构映射文件,然后请求 Enterprise Knowledge Graph 运行实体调和作业。
如需在 Google Cloud 控制台中直接遵循有关此任务的分步指导,请点击操作演示:
确定数据源
实体调和 API 仅支持将 BigQuery 表作为输入。如果您的数据未存储在 BigQuery 中,建议您在更多连接器可用之前将数据转移到 BigQuery。另请确保您配置的服务账号或 OAuth 客户端对您计划使用的表具有读取权限,并且对目标数据集具有写入权限。
创建架构映射文件
对于每个数据源,您都需要创建一个架构映射文件,以告知 Enterprise Knowledge Graph 如何注入数据。
Enterprise Knowledge Graph 使用一种名为 YARRRML 的人类可读简单格式语言来定义源架构与目标通用图谱本体之间的映射关系,schema.org。
Enterprise Knowledge Graph 仅支持 1:1 的简单映射。
支持以下与 schema.org 中的类型对应的实体类型:
架构映射文件示例
组织
prefixes:
ekg: http://cloud.google.com/ekg/0.0.1#
schema: https://schema.org/
mappings:
Organization:
sources:
- [example_project:example_dataset.example_table~bigquery]
s: ekg:company_$(record_id)
po:
- [a, schema:Organization]
- [schema:name, $(company_name_in_source)]
- [schema:streetAddress, $(street)]
- [schema:postalCode, $(postal_code)]
- [schema:addressCountry, $(country)]
- [schema:addressLocality, $(city)]
- [schema:addressRegion, $(state)]
- [ekg:recon.source_name, $(source_system)]
- [ekg:recon.source_key, $(source_key)]
LocalBusiness
prefixes:
ekg: http://cloud.google.com/ekg/0.0.1#
schema: https://schema.org/
mappings:
LocalBusiness:
sources:
- [example_project:example_dataset.example_table~bigquery]
s: ekg:local_business_$(record_id)
po:
- [a, schema:LocalBusiness]
- [schema:name, $(company_name_in_source)]
- [schema:streetAddress, $(street)]
- [schema:postalCode, $(postal_code)]
- [schema:addressCountry, $(country)]
- [schema:addressLocality, $(city)]
- [schema:addressRegion, $(state)]
- [schema:url, $(url)]
- [schema:telephone, $(telephone)]
- [schema:latitude, $(latitude)]
- [schema:longitude, $(longitude)]
- [ekg:recon.source_name, $(source_system)]
- [ekg:recon.source_key, $(source_key)]
人物
prefixes:
ekg: http://cloud.google.com/ekg/0.0.1#
schema: https://schema.org/
mappings:
Person:
sources:
- [example_project:example_dataset.example_table~bigquery]
s: ekg:person_$(record_id)
po:
- [a, schema:Person]
- [schema:postalCode, $(ZIP)]
- [schema:birthDate, $(BIRTHDATE)]
- [schema:name, $(NAME)]
- [schema:gender, $(GENDER)]
- [schema:streetAddress, $(ADDRESS)]
- [ekg:recon.source_name, (Patients)]
- [ekg:recon.source_key, $(source_key)]
对于来源字符串 example_project:example_dataset.example_table~bigquery,~bigquery 是一个固定字符串,用于指明数据源来自 BigQuery。
在谓词列表 (po) 中,ekg:recon.source_name 和 ekg:recon.source_key 是系统使用的预留谓词名称,始终需要在映射文件中提及。通常,谓词 ekg:recon.source_name 会为来源采用常量值(在本例中为 (Patients))。谓词 ekg:recon.source_key 会从源表中获取唯一键(在本例中为 $(source_key)),该键表示源列 ID 中的变量值。
如果您需要在映射文件中定义多个表或来源,或者在一个 API 调用中使用不同的映射文件,则需要确保主题值在不同来源之间是唯一的。您可以使用前缀加上源列键来确保其唯一性。例如,如果您有两个具有相同架构的人员表,则可以为主题 (s) 值分配不同的格式:ekg:person1_$(record_id) 和 ekg:person2_$(record_id)。
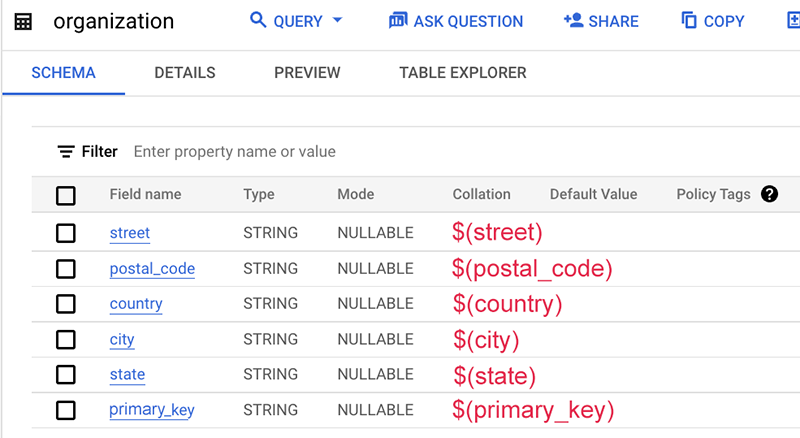
以下是映射文件的示例:
prefixes:
ekg: http://cloud.google.com/ekg/0.0.1#
schema: https://schema.org/
mappings:
organization:
sources:
- [ekg-api-test:demo.organization~bigquery]
s: ekg:company_$(source_key)
po:
- [a, schema:Organization]
- [schema:name, $(source_name)]
- [schema:streetAddress, $(street)]
- [schema:postalCode, $(postal_code)]
- [schema:addressCountry, $(country)]
- [schema:addressLocality, $(city)]
- [schema:addressRegion, $(state)]
- [ekg:recon.source_name, (org)]
- [ekg:recon.source_key, $(primary_key)]
在此示例中,表架构本身不包含此数据源的名称(通常是表名称或数据库名称)。因此,我们使用不含美元符号 $ 的静态字符串“org”。
创建实体协调作业
使用 Google Cloud 控制台创建对账作业。
打开 Enterprise Knowledge Graph 信息中心。
点击架构映射,根据我们的模板为每个数据源创建映射文件,然后将映射文件保存在 Cloud Storage 中。

点击 Job 和 Run A Job,在开始作业之前配置作业参数。
实体类型
值 模型名称 说明 Organizationgoogle_brasil在 Organization级层协调实体。例如,公司名称。这与LocalBusiness不同,后者侧重于特定分支机构、地图注点或实体经营场所,例如众多公司园区中的一个。LocalBusinessgoogle_cyprus根据特定分支机构、地图注点或实体店进行实体对账。它还可以将地理坐标作为模型输入。 Persongoogle_atlantis根据 schema.org中的一组预定义属性协调人员实体。数据源
仅支持 BigQuery 表。
目的地
输出路径应为 BigQuery 数据集,并且 Enterprise Knowledge Graph 具有向该数据集写入的权限。
对于执行的每项作业,Enterprise Knowledge Graph 都会创建一个带有时间戳的新 BigQuery 表来存储结果。
如果您使用实体调和 API,作业响应会包含完整的输出表名称和位置。
根据需要配置高级选项。
如需启动作业,请点击完成。
监控作业状态
您可以通过 Google Cloud 控制台和 API 监控作业状态。作业可能需要长达 24 小时才能完成,具体取决于数据集中的记录数。点击每个单独的作业,即可查看作业的详细配置。
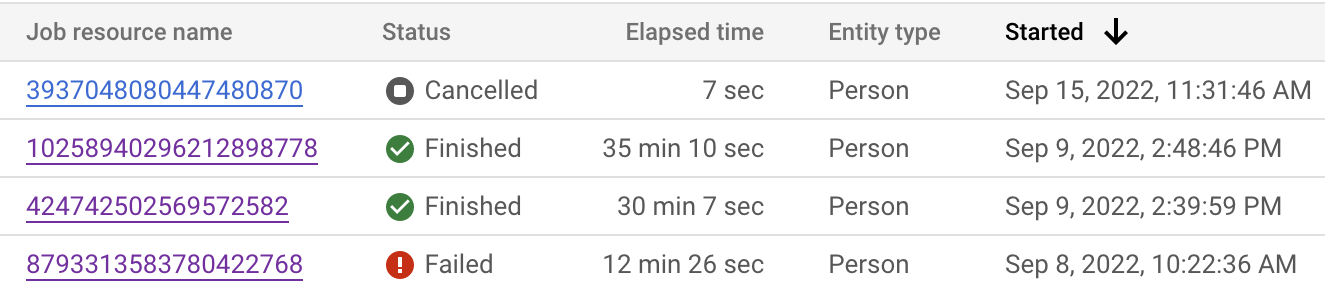
您还可以检查作业状态,了解当前步骤。
| 作业显示状态 | 代码状态 | 说明 |
|---|---|---|
| 正在运行 | JOB_STATE_RUNNING |
作业正在处理中。 |
| 知识提取 | JOB_STATE_KNOWLEDGE_EXTRACTION |
Enterprise Knowledge Graph 正在从 BigQuery 中提取数据并创建特征。 |
| 协调预处理 | JOB_STATE_RECON_PREPROCESSING |
作业处于协调预处理步骤。 |
| 聚簇 | JOB_STATE_CLUSTERING |
作业处于聚类步骤。 |
| 正在导出簇 | JOB_STATE_EXPORTING_CLUSTERS |
作业正在将输出写入 BigQuery 目标数据集。 |
每个作业的运行时长因多种因素而异,例如数据的复杂程度、数据集的大小以及同时运行的其他并行作业的数量。以下是作业执行时间与数据集大小的大致估算值,供您参考。您的实际作业完成时间会有所不同。
| 记录总数 | 执行时间 |
|---|---|
| 10 万 | 约 2 小时 |
| 1 亿 | 约 16 小时 |
| 3 亿 | 约 24 小时 |
取消对账作业
您可以从 Google Cloud 控制台(在作业详情页面上)和 API cancel 正在运行的作业;Enterprise Knowledge Graph 会尽最大努力尽快停止作业。无法保证 cancel 命令一定会成功。
高级选项
| 配置 | 说明 |
|---|---|
| 之前的 BigQuery 结果表 | 指定之前的结果表可确保集群 ID 在不同作业中保持稳定。然后,您可以使用集群 ID 作为永久 ID。 |
| 亲和聚簇 | 在大多数情况下,建议使用此选项。它是层次凝聚式聚类的并行版本,可实现出色的扩展。聚类轮数(迭代次数)可以指定在 [1, 5] 范围内。该数值越大,算法就越容易过度合并聚类。
|
| 关联组件聚类 | 默认选项。这是一个替代性旧版选项;仅当亲和性聚类在您的数据集上效果不佳时,才尝试使用此选项。权重阈值可以是 [0.6, 1] 范围内的数字。 |
| 地理编码隔离 | 此选项可确保来自不同地理区域的实体不会聚类在一起。 |